+ محدودیت زمان: ۱ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
جو شرکت رهنما خیلی صمیمی است؛ بدین منظور در این شرکت همه، از پیر تا جوان، همدیگر را به اسم کوچک صدا میزنند.
در پی استخدامات بیرویه واحد منابع انسانی، به تازگی رهنما با مشکلی اساسی تشابه اسمی مواجه شدهاست.
متاسفانه وقتی کسی در شرکت صدا میزند «باقر» از آنجایی که تعداد زیادی «باقر» در شرکت مشغول کار هستند، نمیتوان فهمید که منظورش کدام «باقر» است.
بدین منظور مدیر منابع انسانی تصمیم میگیرد که برای هر شخص دقیقا یک کلاهرنگی بخرد به طوری که همه کسانی که اسم کوچک مشابهی دارند کلاهی با رنگ متفاوت داشته باشند.
با اینکار تا حدودی مشکل حل میشود؛ بدین صورت که از این به بعد کارکنان شرکت به جای اینکه اسمکوچک شخص را صدا بزنند، از ترکیب «اسم کوچک + رنگ» استفاده میکنند.
مثلا وقتی میگوییم «باقر صورتی» میدانیم تنها یک «باقر صورتی» داریم و دیگر ابهامی وجود ندارد.
حال مدیر منابع انسانی رهنما از شما خواسته تا با گرفتن نام افراد، حداقل تعداد رنگهای مختلف لازم را بدست آورید تا به هر فرد بتوان ترکیب «اسم کوچک + رنگ» یکتایی را متناظر کرد.
**برای فهم بهتر به نمونهها و توضیحشان دقت کنید.**

# ورودی
در خط اول $n$ که تعداد کارکنان شرکت رهنما است به شما داده میشود.
در $n$ خط بعدی در هر خط دو رشته متشکل از حروف کوچک الفبای انگلیسی که طول هر یک حداکثر ۱۵ حرف است به شما داده میشود که با فاصله از هم جدا شده و به ترتیب، نام و نام خانوادگی کارمند $i$ ام را نشان میدهند.
**تضمین میشود که هیچ دو نفری در رهنما وجود ندارند که نام و نام خانوادگیشان دقیقا یکی باشد.**
$$ 1 \le n \le 100$$
# خروجی
در تنها خط خروجی حداقل تعداد رنگهای مختلف لازم را چاپ کنید.
# مثال
## ورودی نمونه ۱
```
5
bagher bagherian
bagher naderian
nader bagherian
nader naderian
steve jobs
```
## خروجی نمونه ۱
```
2
```
توضیح نمونه ۱: با دو رنگ مختلف میتوان مشکل تشابه اسمی را حل کرد به اینصورت که به دو باقر و دو نادر کلاه ناهمرنگ بدهیم.
## ورودی نمونه ۲
```
5
bagher bagherian
bagher borna
bagher naderian
alfred nobel
alfred hitchcock
```
## خروجی نمونه ۲
```
3
```
## ورودی نمونه ۳
```
3
freddie mercury
brian may
roger taylor
```
## خروجی نمونه ۳
```
1
```
الگوریتمی، کارمند زیادی
+ محدودیت زمان: ۲ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
جدولی $ (2 \times n+1) \times (2 \times n+1)$ به این صورت ساخته شدهاست که ابتدا عدد ۱ را در مرکز جدول مینویسیم، سپس عدد ۲ را در خانهی سمت راست عدد ۱ مینویسیم و باقی اعداد را با شروع از عدد ۳ در جهت عکس عقربههای ساعت و به صورت مارپیج و کنار هم در جدول مینویسیم.
شما باید به ازای هر یک از $q$ تا درخواستی که یک زیر مستطیل از این جدول را نمایش میدهند، باقیماندهی مجموع اعداد داخل این زیر مستطیل را بر $10 ^ 9 + 7$ در خروجی چاپ کنید.
به عنوان مثال در جدول زیر عدد $n$ برابر ۲ و مجموع اعداد داخل زیرمستطیل طوسی رنگ برابر ۷۴ است.

# ورودی
در خط اول ورودی ۲ عدد $n$ و $q$ آمده است که به ترتیب اندازهی جدول و تعداد درخواستها را مشخص میکنند.
در $q$ خط بعدی در هر خط به ترتیب ۴ عدد $x_1$ و $y_1$ و $x_2$ و $y_2$ آمده است که مختصات ۲ خانه از جدول را نشان میدهند و این ۲ خانهي مشخص شده، ۲ خانه از ۲ گوشهی روبهروی هم زیر مستطیلی است که شما باید مجموع اعداد داخل آن را حساب کنید.
$$1 \le q \le 100$$
$$1 '\le n \le 1\ 000$$
$$-n \le x_1 \le x_2 \le n$$
$$-n \le y_1 \le y_2 \le n$$
# خروجی
در خط $i$ام خروجی باقیماندهی مجموع اعداد داخل زیرمستطیل مشخص شده در درخواست $i$ام را بر $10 ^ 9 +7$ چاپ کنید.
# مثال
## ورودی نمونه ۱
```
2 3
0 -2 1 1
-1 0 1 0
1 2 1 2
```
## خروجی نمونه ۱
```
74
9
14
```
الگوریتمی، چنبره الف
+ محدودیت زمان: ۲ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
**به محدودیت عدد $n$ در این سوال دقت کنید.**
جدولی $ (2 \times n+1) \times (2 \times n+1)$ به این صورت ساخته شدهاست که ابتدا عدد ۱ را در مرکز جدول مینویسیم، سپس عدد ۲ را در خانهی سمت راست عدد ۱ مینویسیم و باقی اعداد را با شروع از عدد ۳ در جهت عکس عقربههای ساعت و به صورت مارپیج و کنار هم در جدول مینویسیم.
شما باید به ازای هر یک از $q$ تا درخواستی که یک زیر مستطیل از این جدول را نمایش میدهند، باقیماندهی مجموع اعداد داخل این زیر مستطیل را بر $10 ^ 9 + 7$ در خروجی چاپ کنید.
به عنوان مثال در جدول زیر عدد $n$ برابر ۲ و مجموع اعداد داخل زیرمستطیل طوسی رنگ برابر ۷۴ است.

# ورودی
در خط اول ورودی ۲ عدد $n$ و $q$ آمده است که به ترتیب اندازهی جدول و تعداد درخواستها را مشخص میکنند.
در $q$ خط بعدی در هر خط به ترتیب ۴ عدد $x_1$ و $y_1$ و $x_2$ و $y_2$ آمده است که مختصات ۲ خانه از جدول را نشان میدهند و این ۲ خانهي مشخص شده، ۲ خانه از ۲ گوشهی روبهروی هم زیر مستطیلی است که شما باید مجموع اعداد داخل آن را حساب کنید.
$$1 \le q \le 100$$
$$1 \le n \le 100\ 000$$
$$-n \le x_1 \le x_2 \le n$$
$$-n \le y_1 \le y_2 \le n$$
# خروجی
در خط $i$ام خروجی باقیماندهی مجموع اعداد داخل زیرمستطیل مشخص شده در درخواست $i$ام را بر $10 ^ 9 +7$ چاپ کنید.
# مثال
## ورودی نمونه ۱
```
2 3
0 -2 1 1
-1 0 1 0
1 2 1 2
```
## خروجی نمونه ۱
```
74
9
14
```
الگوریتمی، چنبره ب
+ محدودیت زمان: ۱ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
هر کسی در شرکت رهنما گلدان مخصوص خودش را دارد.
اگر کارمندی در شرکت رهنما هوس کند گیاهی را روی میز کارش بگذارد، زحمت ساخت گلدان آن گیاه را پرینتر سهبعدی موجود در طبقهی دوم شرکت میکشد.
به این صورت که ابتدا مختصات یک مستطیل موازی با محورهای مختصات به همراه یک عدد $\theta$ را به پرینتر میدهیم و پرینتر برای ما گلدانی میسازد که حاصل از دوران $\theta$ درجهی این مستطیل حول محور $y$ها **(محور $x=0$)** است.
کارمندان از ابتدای خرید این پرینتر توسط شرکت خیلی از این دستگاه استقبال کردند، اما همهی کارمندان بعد از ساخت گلدانشان یک سوال به ذهنشان میآمد و آن هم این بود که چه مقدار خاک باید بخرم که برای این گلدان کافی باشد.
به راستی که اگر پرینتر بعد از ساخت گلدان، حجم گلدان را هم به ما نمایش میداد دیگر حرفی برای گفتن باقی نمیگذاشت.
کارمندان شرکت که به این مشکل برخوردند، تصمیم گرفتند که خودشان برنامه ای بنویسند تا اینکار را انجام دهد.
حال از شما به عنوان کارمند آیندهی شرکت میخواهیم که این کد را برای ما بازنویسی کنید.
# ورودی
در خط اول ورودی ۴ عدد صحیح $x_1$ و $y_1$ و $x_2$ و $y_2$ آمدهاست که ۲ نقطه روبهروی مستطیل را نشان میدهند.
در خط بعدی ورودی عدد طبیعی $\theta$ آمده است.
$$-1000 \le x_1 < x_2 \le 1000$$
$$-1000 \le y_1 < y_2 \le 1000$$
$$1 \le \theta \le 360$$
# خروجی
در تنها خط خروجی حجم شکل حاصل از $\theta$ درجه دوران مستطیل داده شده، حول محور $x=0$ را چاپ کنید.
**دقت کنید که جواب شما در صورتی قابل قبول خواهد بود که اختلافش با جواب اصلی کمتر از $10 ^ {-6}$ باشد.**
# مثال
## ورودی نمونه ۱
```
0 0 4 3
360
```
## خروجی نمونه ۱
```
150.7964473723
```
## ورودی نمونه ۲
```
4 4 5 5
11
```
## خروجی نمونه ۲
```
0.8639379797
```
پیادهسازی، گلدان رهنما کالج
+ محدودیت زمان: ۱ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
همانطور که میدانید برنامهنویسی و کار کردن گروهی روی پروژهها نیازمند مقادیری نظم و هماهنگی است.
یکی از راههای مفید برای ایجاد نظم و هماهنگی در کارهای متنی و برنامهنویسی استفاده از ابزار `git` است.
در این سوال ما یک نسخهی شخصیسازی شده از `git` داریم و میخواهیم برای آن تعدادی دستور دیگر اضافه کنیم.
این نسخه از `git` شخصیسازی شده تنها میتواند تغییرات را روی یک فایل خاص که در ابتدا خالی است، اعمال و ذخیرهسازی کند.
در ادامه دستوراتی که در این نسخه نیاز به پیادهسازی دارند شرح داده شده است:
+ دستور `git add string`: این دستور به این معناست که رشتهی `string` را به انتهای فایل فعلی اضافه کن.
+ دستور `git clear`: این دستور به این معناست که فایل فعلی را خالی کن.
+ دستور `git del`: این دستور به این معناست که خط انتهایی فایل فعلی را در صورت وجود حذف کن.
+ دستور `git commit & push`: این دستور تغییراتی که در فایل ایجاد شده را، روی سرور و فایل اصلی اعمال میکند.
+ دستور `git checkout`: با اجرای این دستور باید **محتوای فایل فعلی و اصلی** را برابر محتوای فایل بعد از اجرای یکی مانده به آخرین دستور از نوع `git commit & push` قرار دهید.
+ دستور `git pull`: با اجرای این دستور باید آخرین محتوایی که روی سرور و فایل اصلی است را چاپ کنید.
وظیفهی اضافه کردن این دستورات با شماست.
برای آشنایی بیشتر با قابلیتهای `git` میتوانید به این [لینک](http://rogerdudler.github.io/git-guide/) مراجعه کنید.
# ورودی
در خ اول ورودی عدد $q$ آمدهاست، که تعداد دستورات را نشان میدهد.
در $q$ خط بعدی در هر خط یکی از دستورات بالا آمده است.
تضمین میشود که قبل از هر دستور `git checkout` حداقل ۲ دستور از نوع `git commit & push` آمده باشد.
طول هر رشته ورودی حداکثر ۳۰ میباشد.
$$1 \le q \le 20$$
# خروجی
در خروجی به ازای هر یک از دستورهای از نوع `git pull` ابتدا تعداد خطوط محتوای داخل فایل را چاپ کنید و در ادامهی خروجی به ترتیب در هر خط یکی از خطوط محتوای فایل را چاپ کنید.
# مثال
## ورودی نمونه ۱
```
8
git add #include <iostream>
git add using namespace std;
git add int main(){
git add cout<<"Rahnema\n";
git add }
git pull
git commit & push
git pull
```
## خروجی نمونه ۱
```
0
5
#include <iostream>
using namespace std;
int main(){
cout<<"Rahnema\n";
}
```
## ورودی نمونه ۲
```
6
git add test1
git commit & push
git add test2
git commit & push
git checkout
git pull
```
## خروجی نمونه ۲
```
1
test1
```
پیادهسازی، گیت شخصی
+ محدودیت زمان: ۱ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
شرکت رهنما میخواهد فرش بزرگی در طبقهی اختصاصی رهنما کالج بیاندازد.
از آنجا که کارمندان رهنما از طرح فرشهای موجود در بازار خوششان نیامده بود تصمیم گرفتند که طرح و اندارهی فرش را خودشان و متناسب با فضای رهنما کالج انتخاب کنند.
پس از بررسی های لازم توسط گرافیستهای شرکت، فرشی مربعی شکل، به ضلع $2^{n+1} -1$ متر و به طرحی که در ادامه گفته خواهد شد، انتخاب شد.
طرح فرش به این صورت است که ابتدا یک مربع به عنوان کادر فرش رسم میشود (طول ضلع این مربع با طول ضلع فرش برابر است)، سپس $n-1$ مرحله حرکت زیر را انجام میدهیم تا $n-1$ مربع دیگر رسم شوند.
+ وسط اضلاع آخرین مربعی که رسم شده را به صورت ساعتگرد به یکدیگر وصل میکنیم.
در انتها شکل به دست آمده را به قالی بافی میدهیم تا فرش مورد نظر را برایمان ببافند.
اما کشیدن طرح این فرش اینقدرها هم کار آسانی نیست، مخصوصا اگر قرار بر این باشد که برنامهای بنویسید تا این کار را انجام دهد.
شکل زیر روش رسم مرحله به مرحلهی فرش را به ازای $n = 4$ نمایش میدهد.

**برای فهم بهتر سوال به مثالها توجه کنید.**
# ورودی
در تنها خط ورودی عدد $n$ آمده است.
$$1 \le n \le 10$$
# خروجی
در خروجی به ازای عدد $n$ طرح فرش رهنما کالج را چاپ کنید.
دقت کنید که اضلاع مربعها را باید با کاراکتر `#` نشان دهید و باقی خانههای خالی روی فرش را با کاراکتر `.`.
# مثال
## ورودی نمونه ۱
```
1
```
## خروجی نمونه ۱
```
###
#.#
###
```
## ورودی نمونه ۲
```
2
```
## خروجی نمونه ۲
```
#######
#..#..#
#.#.#.#
##...##
#.#.#.#
#..#..#
#######
```
## ورودی نمونه ۳
```
3
```
## خروجی نمونه ۳
```
###############
#......#......#
#.....#.#.....#
#....#...#....#
#...#######...#
#..##.....##..#
#.#.#.....#.#.#
##..#.....#..##
#.#.#.....#.#.#
#..##.....##..#
#...#######...#
#....#...#....#
#.....#.#.....#
#......#......#
###############
```
پیادهسازی، فرش دستباف
همانطور که میدانید در لینوکس با استفاده از دستور `md5sum`، میتوان هش [MD5](https://en.wikipedia.org/wiki/MD5) محتوای یک فایل را به دست آورد. میتوان از این مقدار برای بررسی مساوی بودن محتوای دو فایل استفاده کرد، به این صورت که اگر مقدار هش دو فایل برابر باشد به احتمال بسیار زیاد محتوای آن فایلها با هم کاملاً یکسان است.
اکنون ما میخواهیم دو پوشه را با هم مقایسه کنیم و ببینیم که آیا محتوای این دو پوشه کاملاً یکسان است یا خیر. از نظر ما دو پوشه یکسان هستند اگر اولاً ساختار داخلی دو پوشه (پوشهبندیها و مسیر فایلها) دقیقاً یکسان باشد و محتوای فایلهای متناظر کاملاً یکسان باشد. یعنی هر دو فایل متناظر، آدرس نسبی یکسانی داشته باشند (نسبت به پوشه خود، در مسیر یکسانی قرار گرفته باشند) و محتوای یکسانی نیز داشته باشند. (اطلاعاتی مانند owner, permission, time فایلها را در نظر نمیگیریم).
بنابراین در مثال زیر، با فرض یکسان بودن محتوای فایلهای با نام یکسان، دو پوشه `dir1` و `dir2` یکسان نیستند چون ساختار داخلی متفاوتی دارند. اما `dir1` و `dir3` با این که نامهای متفاوتی دارند، یکسان هستند (زیرا محتوای یکسانی دارند).
```
dir1
├── file1
└── file2
dir2
├── file1
└── file2
└── file2
dir3
├── file1
└── file2
```
برای این مقایسه میخواهیم با استفاده از `md5sum` یک هش برای هر پوشه به دست بیاوریم و برای مقایسه پوشهها، هش پوشهها را با هم مقایسه کنیم.
یک اسکریپت Bash با نام `md5sum4dir.sh` بنویسید که آدرس یک پوشه را بگیرد و در خروجی، هش آن پوشه را بنویسد. هش تولیدشده باید مانند خروجی `md5sum` یک رشته hex به طول ۳۲ باشد.
```bash
$ bash md5sum4dir.sh path/to/some/dir
b459813010c9760d7ba32bed678c3752
```
اسکریپت `md5sum4dir.sh` را Zip کنید و به عنوان پاسخ ارسال کنید. دقت کنید که اسکریپت باید مستقیماً در ریشه فایل Zip باشد (در هیچ پوشهای نباشد).
لینوکس، Directory Checksum
فرض کنید برنامهای در یک سرور لینوکس log های خود را در یک فایل به نام `app.log` مینویسد. برای این که حجم این فایل خیلی زیاد نشود، میخواهیم یک اسکریپت Bash برای rotate کردن فایلهای لاگ به نام `rotate.sh` بنویسیم (تا log های هر روز در یک فایل جداگانه ذخیره شود) و سرور را طوری تنظیم کنیم که این اسکریپت هر نیمهشب یک بار اجرا شود.
یک وضعیت از فایلهای پوشه log ها را در زیر میبینید. در انتهای فایلهای rotate شده، یک عدد قرار میگیرد و هرچه این عدد بزرگتر باشد، فایل قدیمیتر است. `app.log` لاگهای امروز را نشان میدهد، `app.log.1` لاگهای دیروز را در خود دارد و به همین ترتیب.
```
app.log
app.log.1
app.log.2
unrelated-file-1.txt
unrelated-file-2.txt
```
در صورت اجرای اسکریپت `rotate.sh` وضعیت پوشه باید به این صورت تغییر کند:
```
app.log
app.log.1
app.log.2
app.log.3
unrelated-file-1.txt
unrelated-file-2.txt
```
فایل `app.log.2` به `app.log.3` تغییر نام داده، فایل `app.log.1` به `app.log.2` تغییر نام داده، فایل `app.log` به `app.log.1` تغییر نام داده و یک فایل خالی به نام `app.log` ایجاد شده تا لاگهای جدید در آن نوشته شود.
اسکریپت `rotate.sh` را بنویسید که آدرس پوشهای که `app.log` در آن قرار دارد را به عنوان آرگومان دریافت کند و عمل rotate را بر روی لاگها انجام دهد. مثلاً:
```bash
$ bash rotate.sh path/to/logs/dir
```
توجه کنید که علاوه بر فایلهای لاگ، ممکن است فایلها و پوشههای دیگری نیز در کنار `app.log` وجود داشته باشد که اسکریپت نباید در آنها تغییری ایجاد کند.
اسکریپت `rotate.sh` را Zip کنید و به عنوان پاسخ ارسال کنید. دقت کنید که اسکریپت باید مستقیماً در ریشه فایل Zip باشد (در هیچ پوشهای نباشد).
لینوکس، Log Rotation
یک اسکریپت Bash با نام `myfind.sh` بنویسید که یک فایل و یک رشته را بگیرد و کل متن فایل را به این صورت در خروجی استاندارد بنویسد:
در ابتدای خطوطی که رشته دادهشده در آن خطوط وجود ندارد، دو کاراکتر فاصله و در ابتدای خطوطی که رشته دادهشده در آن خطوط وجود دارد، یک `+` و سپس یک فاصله بیاید.
تشخیص این که رشته دادهشده در یک خط وجود دارد یا خیر باید به صورت case insensitive باشد.
به عنوان مثال، اگر مختوای فایل `sample.cpp` به صورت زیر باشد:
```
#include <iostream>
using namespace std;
int main() {
int n;
cin >> n;
for (int m=0; m<n; m++)
cout << m << endl;
return 0;
}
```
با اجرای دستور `bash myfind.sh sample.cpp 'iNt m'` خروجی به صورت زیر خواهد بود:
```
#include <iostream>
using namespace std;
+ int main() {
int n;
cin >> n;
+ for (int m=0; m<n; m++)
cout << m << endl;
return 0;
}
```
اسکریپت `myfind.sh` را Zip کنید و به عنوان پاسخ ارسال کنید. دقت کنید که اسکریپت باید مستقیماً در ریشه فایل Zip باشد (در هیچ پوشهای نباشد).
لینوکس، Myfind
شرکت "زمانبندان" قصد دارد سیستم ثبت زمانی را برای کارمندانش پیاده سازی کند از آنجایی که ثبت زمان کارمندان برای همه شرکتها دغدغه مهم به حساب میآید این سیستم را به صورتی پیاده سازی کردهاند که تمامی شرکتها بتوانند با ساختن یک اکانت از آن استفاده کنند. شمای دیتابیس به صورت زیر است.
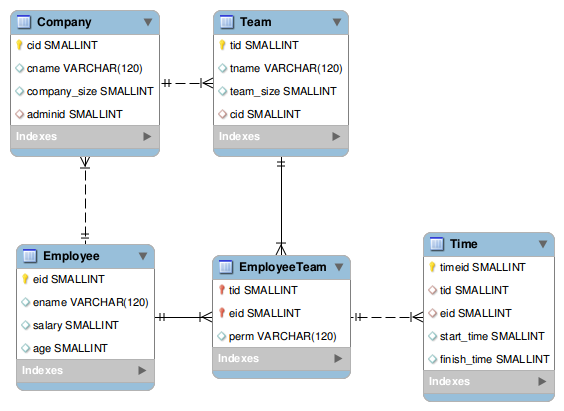
```
CREATE TABLE Employee (
eid SMALLINT NOT NULL AUTO_INCREMENT PRIMARY KEY ,
ename VARCHAR (120) ,
salary SMALLINT,
age SMALLINT
);
CREATE TABLE Company (
cid SMALLINT NOT NULL AUTO_INCREMENT PRIMARY KEY ,
cname VARCHAR (120) ,
company_size SMALLINT ,
adminid SMALLINT ,
FOREIGN KEY (adminid) REFERENCES Employee(eid)
ON DELETE CASCADE
on UPDATE CASCADE
);
CREATE TABLE Team (
tid SMALLINT NOT NULL AUTO_INCREMENT PRIMARY KEY ,
tname VARCHAR (120) ,
team_size SMALLINT,
cid SMALLINT,
FOREIGN KEY (cid) REFERENCES Company(cid)
ON DELETE CASCADE
on UPDATE CASCADE
);
CREATE TABLE EmployeeTeam (
tid SMALLINT ,
eid SMALLINT ,
perm VARCHAR (120),
PRIMARY KEY (tid, eid),
FOREIGN KEY (eid) REFERENCES Employee(eid)
ON DELETE CASCADE
on UPDATE CASCADE,
FOREIGN KEY (tid) REFERENCES Team(tid)
ON DELETE CASCADE
on UPDATE CASCADE
);
CREATE TABLE Time (
timeid SMALLINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
tid SMALLINT ,
eid SMALLINT ,
FOREIGN KEY (tid, eid) REFERENCES EmployeeTeam(tid, eid)
ON DELETE CASCADE
on UPDATE CASCADE,
start_time SMALLINT,
finish_time SMALLINT
);```
حال از شما خواسته شده است با توجه به مهارتتان دستوراتی برای `Mysql` پیاده سازی کنید که خواستههای زیر را برآورده کند.
+ شماره گروههایی را بیابید که یک فردی در آن وجود دارد که در زمان ۱۰۰۰ تا ۱۲۰۰۰ فعال بوده باشد.
+ شماره ادمین هایی را بیابید که یک گروهی برای آنها وجود دارد که این گروه در شرکتِ خودِ ادمین باشد.
+ اگر فردی در یک شرکت در بیش از یک گروه عضو باشد میگوییم شرکت فرد را در برگرفته است. نام افرادی را به صورت یکتا بیابید که سن بزرگتر از ۳۰ است و بیش از یک شرکت آنها را در برگرفتهاند.
*توجه* : در قسمت اول شماره گروهها در قسمت دوم شماره ادمین ها و در قسمت سوم نام افراد را به صورت یکتا باید select کنید.
# روش پیادهسازی
در یک فایل با نام `code.sql` کد خود را قرار دهید و آن را فشرده (`zip` ) کنید و در سایت بارگذاری نمایید.
کد شما باید به صورت زیر باشد(نام فایل zip مهم نیست).
```
-- Section1
your first query here
-- Section2
your second query here
-- Section3
your third query here
```