سلام
به مسابقه **یادگیری ماشین** از **مسیر داده** لیگ **کُدکاپ ۱۴۰۰** خوش آمدید.
برای آشنایی با سیستم داوری مسابقات مسیر تحلیل داده، ویدئو زیر را مشاهده کنید.
%video:/video/player/eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ2aWRlb191cmwiOiJodHRwczovL3N0cmVhbS5xdWVyYXZpZGVvLmlyL2NvbGxlZ2UvNzgzYjM0YTYtNzE0NC00ZjM0LTk1ODUtMWQ3OWZhNDRkMmY5L3BsYXlsaXN0Lm0zdTgiLCJ0aHVtYm5haWxfdXJsIjoiIiwiZXhwaXJlc19hdCI6MTc4NTU1OTc1NX0.H74Ow7WTmUfM3wFrEeNjQCliR__mBhGlyYwOpdYLPR4%
قبل از شروع مسابقه، ابتدا موارد زیر را مطالعه کنید:
+ این مسابقه، دارای ۵ سوال با استفاده از دادگان جدولی، متنی و عکس برای ۳ روز میباشد.
+ برای حل سوالات این مسابقه، **میتوانید** از روشهای زیر استفاده کنید:
+ تحیل داده
+ داده کاوی
+ سیستمهای پیشنهاددهنده
+ تحلیل سریزمانی
+ پردازش متن
+ پردازش تصویر (بینایی ماشین)
+ یادگیری ماشین
+ یادگیری عمیق
+ محدودیتی برای شما در انتخاب ابزار نرمافزاری یا زبان برنامهنویسی وجود ندارد.
+ این مسابقه در ساعت ۱۶:۰۵ روز دوشنبه (۲۲ آذر) به پایان میرسد.
+ برای مطالعه قوانین شرکت در مسابقه به [اینجا](https://quera.ir/course/assignments/2693/problems/33523) مراجعه کنید.
+ در طول زمان مسابقه میتوانید سوالهای خود را از قسمت "سوال بپرسید" مطرح کنید. با توجه به این که زمان این مسابقه ۳ روز میباشد فقط سر ساعتهای ۱۱، ۱۴، ۱۷ و ۱۹ روزهای مسابقه، به سوالاتی که تا آن لحظه دریافت کردهایم، پاسخ خواهیم داد (هر چند ما تمامی تلاش خود را میکنیم تا در ساعات دیگر نیز پاسخگوی سوالات شما باشیم).
+ پیش از پایان زمان مسابقه، **باید** کُد سوالات خود را در بخش "بارگذاری کد" قرار دهید. در صورت عدم انجام این کار، از این مسابقه **حذف** میشوید و امتیازی نیز دریافت نخواهید کرد (مدیریت کردن زمان، بر عهده **شما** میباشد و زمان مسابقه برای بارگذاری کُد، تمدید نخواهد شد).
+ داوری هر سوال تا قبل از پایان مسابقه، تنها بر اساس ۳۰ درصد از دادگان آزمایش (`test`) خواهد بود. پس از اتمام مسابقه، برای بهروزرسانی نهایی جدول امتیازات، فقط از ۷۰ درصد مابقی دادگان آزمایش بر روی **ارسال نهایی** شما استفاده خواهد شد؛ این کار برای جلوگیری از بیشبرازش (`overfitting`) انجام میشود.
+ این مسابقه در مجموع ۱۰۰۰ امتیاز دارد و افراد برتر، آنهایی هستند که بیشترین امتیازها را در مجموع کسب کنند.
+ بعد از پایان زمان مسابقه، امتیاز افرادی که از روشهای غیرمتناسب با هدف مسابقه (مانند تابع تصادفی) استفاده کرده باشند، صفر میشود و این امر تخلف به حساب میآید.
+ توجه داشته باشید که شما **۳ روز کامل** برای حل سوالات این مسابقه فرصت دارید. در نتیجه، حتی اگر مطلبی را بلد نیستید، شما فرصت دارید که در این بازه زمانی، آن را فراگرفته و نسبت به حل سوال مربوطه اقدام کنید، پس ناامید نشوید. 😉
+ شما مجاز به استفاده از دادگان به اشتراک گذاشته شده در این مسابقه، برای سایر اهداف (آموزشی و غیرآموزشی) **نیستید**.
+ وبینار آموزشی این مسابقه در روز دوشنبه ۲۲ آذر ساعت ۱۸ برگزار خواهد شد که ابتدا آمار مسابقه را بررسی میکنیم و در ادامه راهحل سوالات را خواهیم دید. برای شرکت در وبینار، به صورت کاربر *مهمان* از طریق [اینجا](https://evand.com/events/%D9%88%D8%A8%DB%8C%D9%86%D8%A7%D8%B1-%D8%AD%D9%84-%D8%B3%D9%88%D8%A7%D9%84%D8%A7%D8%AA-%D9%85%D8%B3%D8%A7%D8%A8%D9%82%D9%87-deep-learning-%DA%A9%D8%AF%DA%A9%D8%A7%D9%BE-6-27579?icn=organizer&ici=4) اقدام به ورود کنید.
+ لینک وبینار و فایلهای توضیح داده شده در وبینار، بعد از گذشت چند روز از پایان مسابقه در آدرس https://github.com/QueraTeam/data-contests قرار داده میشوند.
+ بعد از برگزاری وبینار آموزشی، یک نظرسنجی در مورد مسابقه برای **شما** ارسال میگردد. لطفا با پُر کردن این نظرسنجی به ما در بهبود کیفیت مسابقات آینده تحلیل داده کمک کنید.
# زیرساخت و نحوه دریافت دادگان
دادگان هر سوال را در صورت سوال مربوطه، میتوانید دریافت نمایید. اما پیش از آن، بایستی که محیط برنامهنویسی لازم برای محاسبات خود را آماده کنید. اگر میخواهید که با استفاده از زبان برنامهنویسی پایتون و کتابخانههای موجود در آن، در این مسابقه شرکت کنید. میتوانید از سامانه [گوگل کُلَب](https://colab.research.google.com) استفاده کنید.
بدین صورت نیازی نیست که شما دادگان حجیم این مسابقه (در حد گیگابایت) را روی کامپیوتر خود دانلود کنید. همچنین گوگل کُلَب این امکان را به شما میدهد که از قابلیتهای `GPU` و `TPU` آن به رایگان استفاده کرده و سرعت محاسبات خود را به طور قابل ملاحظهای افزایش دهید. **پیشنهاد** میشود که ابتدا کُد خود را در حالت `CPU` توسعه دهید و **فقط** هنگامی که می خواهید شروع به آموزش دادن مُدل خود کنید، قابلیت `GPU` یا `TPU` را در صورت **نیاز** فعال کنید، بدین صورت به صورت بهینه از منابع استفاده میکنید.
اگر اولین باری است که با گوگل کُلَب آشنا میشوید. پیشنهاد میشود راهنمای فارسی کار با آن را از [اینجا](https://virgool.io/@baran.science/%DA%86%DA%AF%D9%88%D9%86%D9%87-%D8%A8%D8%A7-google-colab-%DA%A9%D8%A7%D8%B1-%DA%A9%D9%86%DB%8C%D9%85-mihfp5n8mdta) به دقت مطالعه کنید. توجه داشته باشید که برای استفاده از گوگل کُلَب، شما نیازمند به داشتن ایمیل `gmail` میباشید و قابلیتهای ارائه شده در نسخه رایگان آن، برای انجام این مسابقه کافی است. همچنین **فعلا** برای دسترسی به آن نیازی به استفاده از فیلترشکن نیست.
برای سوالهای "پیشبینی تعداد سفر" و "تحلیل احساس نظرات"، **بایستی** که دادگان آن را خود مستقیم دریافت کرده و از قسمت `Files` و از طریق `Upload to session storage`، داخل گوگل کُلَب بارگذاری کنید.
از آنجایی که دادگان باقی سوالات حجم بالاتری دارند؛ پیشنهاد میکنیم که آنها را با کمک دستور `wget` و به صورت مستقیم در گوگل کُلَب، قرار دهید. برای مطالعه بیشتر در مورد این دستور، [اینجا](https://www.pair.com/support/kb/paircloud-downloading-files-with-wget) را ببینید.
توجه داشته باشید که داخل گوگل کُلب، باید قبل از اجرای دستور `wget`، علامت `!` قرار دهید. به مثالهای زیر نگاه کنید.
```
! wget <URL>
! unzip <ZIP file>
```
همچنین در صورتی که نمی خواهید از گوگل کُلب استفاده کنید و میخواهید محاسبات را در کامپیوتر شخصی خود یا زیرساخت دیگری انجام دهید، میتوانید دادگان را دانلود و از حالت فشرده خارج کنید. توجه داشته باشید که اگر اینترنت شما، از ترافیک نیمبها برای سایتهای داخلی استفاده میکند، بهتر است که در هنگام دریافت دادگان، `VPN` خود را خاموش کنید.
توجه داشته باشید که محدودیتی در زبان برنامهنویسی مورد استفاده برای این مسابقه وجود **ندارد**.
مقدمه
اگر از تاکسیاینترنتی اسنپ برای حمل و نقل استفاده کرده باشید و به قول معروف «اسنپ زده باشید!»، حتما با تصویر زیر آشنا هستید. 😉

در این تصویر، تعداد رانندگان اطراف یک درخواست کننده سفر، نشان داده شدهاند. اما شما (طبیعتا!) تعداد مسافرانی که در آن لحظه از اسنپ درخواست سفر کردهاند را نمیبینید.
# دادگان
در این سوال، مجموعه [اسنپکب](https://snapp.ir/taxi-ride?utm_source=snapp-website)، ارائه دهنده خدمت تاکسی اینترنتی اسنپ، تاریخچه تعداد مسافرانی که در هر دقیقه، درخواست سفر کردهاند را از [این لینک](/contest/assignments/35056/download_problem_initial_project/118270/) ، در اختیار شما قرار دادهاست.
هنگامی که این فایل را از حالت فشرده خارج کنید. پوشه `cab` را میبینید. در صورتی که وارد این پوشه شوید، فایلهای آموزش (`train.csv`) و آزمایش (`test.csv`) در اختیار شما خواهند بود. فایل آموزش، اطلاعات درخواست مسافران به ازای هر دقیقه را در یک بازه ۲ ماهه، در اختیار شما قرار میدهد که جزییات آن، در جدول زیر آمدهاست:
| نام ستون | توضیحات ستون |
|:----------|:------------------:|
| time | زمان ثبت درخواستها (با دقت دقیقه) |
| y | تابعی از تعداد مسافران منتظر راننده|
# صورت مسئله
معیار `y`، نشاندهنده وضعیت جاری کسب و کار و میزان مشتریان ورودی در لحظه است. به همین دلیل، این [معیار (KPI)](https://fa.wikipedia.org/wiki/%D8%B4%D8%A7%D8%AE%D8%B5_%D8%B9%D9%85%D9%84%DA%A9%D8%B1%D8%AF) و رصد آن در طول زمان، دارای اهمیت بسیار ویژهای برای مجموعه اسنپکب است. 🤗
یکی از عوامل ناخواسته و خارج از کنترلی که این معیار را تحت تاثیر منفی قرار میدهد، مشکلات فنی یا به قولی `Technical Incident`ها هستند که گاهی باعث از دسترس خارج شدن مقطعی و یا حتی کامل سامانه دریافت درخواست اسنپکب میشوند. 😢
در نتیجه اگر نمودار سری زمانی این دادگان را رسم کنید؛ با افتادگیهایی ناشی از همین اتفاقات (مانند شکل زیر) روبرو خواهید شد:

در شکل بالا، نمودار قرمز رنگ، نحوه تغییر معیار `y` را در طول زمان نشان میدهد. همانگونه که در تصویر معلوم است، از دقایقی قبل از ساعت ۱۵:۳۰ تا حدود ۱۶:۴۰، سامانه دچار مشکل شده و درخواستهای سفر کاهش پیدا کرده بودند. در همین نمودار، خطچین زردرنگ نشانگر **انتظار** ما از رفتار سیستم است اگر خطایی رخ نداده بود و از آن با نام **مقدار ایدهآل** `y` یاد میکنیم.
بهعبارت دیگر، مقدار ایدهآل `y` در زمانهایی که مشکل فنی نیست برابر است با مقدار `y` و در زمانهایی که مشکل فنی وجود دارد، بایستی مقدار آن به شکلی باشد که بین سریزمانی قبل و بعد از حادثه، یک نمودار `smooth` و یا به اصطلاح صاف مانند شکل بالا، ایجاد شود.
حال، اسنپکب از شما انتظار دارد که با استفاده از روشهای یادگیریماشین، یادگیری عمیق و یا سریهای زمانی، اقدام به پیشبینی **مقدار ایدهآل** `y` در دادگان آزمایش بکنید. 😎
<details class="yellow">
<summary>
**توجه**
</summary>
لطفا به نکات زیر توجه داشته باشید:
+ شناسایی زمانهای بروز مشکل فنی، جزوی از چالش این مسئله است و تعریف دقیقی برای آنها ارائه نشدهاست.
+ شما در دادگان آموزش، مقدار ایدهآل `y` را در لحظات رخدادن حادثه ندارید. در نتیجه، چالشهای مرتبط با آن نیز، جزوی از این مسئله است.
</details>
<details class="pink">
<summary>
**راهنمایی**
</summary>
**شاید** نکات زیر، بتوانند به شما در حل این مسئله کمک بکنند:
+ شناسایی بازههای مشکلات فنی و اصلاح آنها در دادگان آموزش و یا در پیشبینیهای دادگان آزمایش با استفاده از روشهای مرتبط مانند `Moving Average`
+ استفاده از یادگیری نظارتشده (`supervised`)
+ استفاده از الگوریتمهای مرتبط با سری زمانی
+ یا استفاده از هر روش دیگر مرتبط با تحلیل داده، یادگیری ماشین و عمیق
</details>
# ارزیابی
برای ارزیابی مُدل شما از معیار (`metric`) زیر استفاده میشود:
$$metric = \frac{\sum_{i=1}^{i=n} |y_i-prediction_i|}{\sum_{i=1}^{i=n} y_i} $$
در فرمول بالا، $y_i$ مقدار ایدهآل معیار $y$ برای زمان $i$ است و $prediction_i$ نیز مقدار پیشبینی شده مُدل شما برای آن زمان میباشد. همچنین تعداد نمونههای دادگان را از شماره ۱ تا $n$ در نظر میگیریم. در نهایت، امتیاز شما از این مرحله بر اساس فرمول زیر محاسبه میگردد:
$$score = (0.2 - metric) \times1000$$
هدف شما، بایستی ساختن مُدلی با $metric<0.2$ باشد.
<details class="green">
<summary>
**توضیحات**
</summary>
با توجه به این که `metric` برابر یا بزرگتر از ۰.۲ به عنوان مدل مناسب این مسئله، از سمت تیم اسنپکب مورد قبول قرار نمیگیرد. پس هرمدلی که چنین عملکردی را روی دادگان آزمایش داشتهباشد، **صفر** امتیاز از این سوال کسب میکند.
</details>
<details class="yellow">
<summary>
**توجه**
</summary>
لطفا در هنگام کار با این دادگان، به نکات زیر توجه داشته باشید:
+ مقدار `metric` مدل شما، تا سه رقم اعشار محاسبه (رُند) و در فرمول امتیازدهی بالا، قرار داده میشود.
+ این سوال، امتیاز منفی ندارد. حتی اگر `score` شما، منفی شود. از این سوال حداقل **صفر** امتیاز میگیرید. 😜
+ بیشترین امتیاز ممکن از این سوال ۲۰۰ و کمترین امتیاز ممکن، صفر است.
</details>
# خروجی
پیشبینیهای مدل خود بر روی دادگان آزمایش (`test.csv`) را در فایلی با نام `output.csv` قرار دهید. این فایل باید دارای یک ستون با نام `prediction` باشد که ردیف iام آن، پیشبینی شما برای سطر iام دادگان آزمایش باشد (دقت کنید که این ستون باید حتما دارای `header` باشد).
بعد از آمادهسازی فایل `output.csv`، آن را برای ما بارگذاری کنید.
## نمونه خروجی فایل `output.csv` (فقط سه خط اول به همراه نام ستون)
```
prediction
7835
6431
8304
```
<details class="yellow">
<summary>
**توجه**
</summary>
حتما فایل `output.csv` باید دارای ۴,۳۲۰ سطر (بدون در نظر گرفتن `header`) و یک ستون باشد.
همچنین نام ستون بایستی بدون `space` در قبل و بعد از نام آن، باشد. در غیر این صورت، سیستم داوری نمرهای به شما نخواهد داد.
</details>
<details class="red">
<summary>
**هشدار 😱**
</summary>
فراموش نکنید که **قبل از پایان زمان مسابقه**، **بایستی** تمامی کدهای این مسابقه را از قسمت **بارگذاری کُد** برای ما ارسال کنید. در غیر این صورت، شما از این مسابقه، امتیازی کسب نمی کنید.
توجه داشته باشید که اگر از `jupter notebook` استفاده می کنید بایستی همانند توضیحات قسمت **بارگذاری کُد**، خروجی `.py` را دریافت و برای ارسال در نظر بگیرید. ارسال فایلهای `jupyter` همانند `.ipynb` مورد قبول واقع نخواهند شد.
</details>
پیشبینی تعداد سفر
[اسنپتریپ](https://www.snapptrip.com)، به عنوان ارائه دهنده خدمات و سرویسهای مورد نیاز برای سفر، در کنار امکان رزرو هتل، اقامتگاه و مهمانسرا در سراسر ایران، مجموعهای کامل از خدمات مسافری مانند خرید بلیط اتوبوس، هواپیما و قطار را به یک مسافر ارائه می دهد.
احتمالا هنگامی که شما بخواهید برای تعطیلات نوروز به یک شهر مانند ارومیه سفر کنید، از طریق موبایل و یا لپتاپ و از مسیر جستجوی گوگل، پیامک تبلیغاتی و یا به صورت مستقیم، وارد سایت اسنپتریپ میشوید و بعد از ساخت حساب کاربری، اقدام به جستجو میکنید:
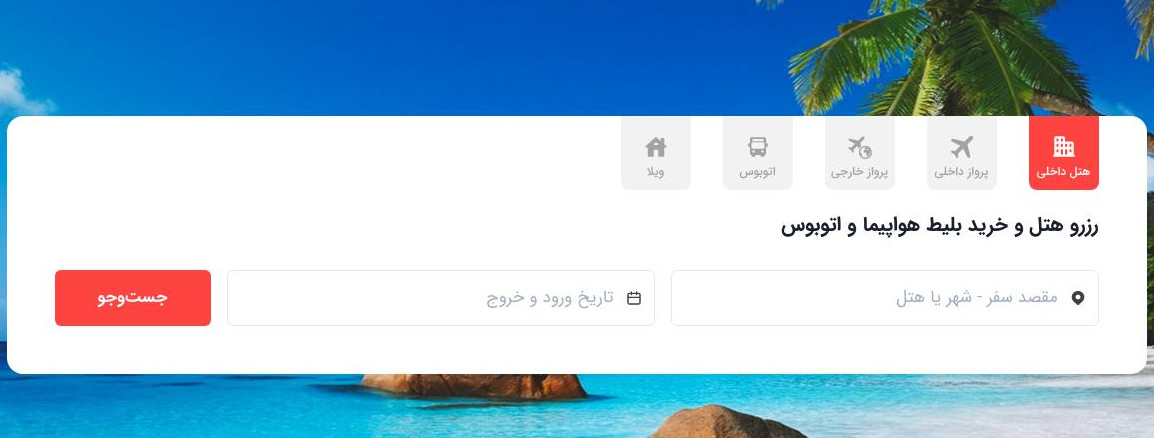
سپس، شما اقدام به انتخاب مقصد و تاریخ ورود/خروج خود میکنید. در نتیجه لیستی از هتلها برای شما مانند شکل زیر، نشان داده میشود.
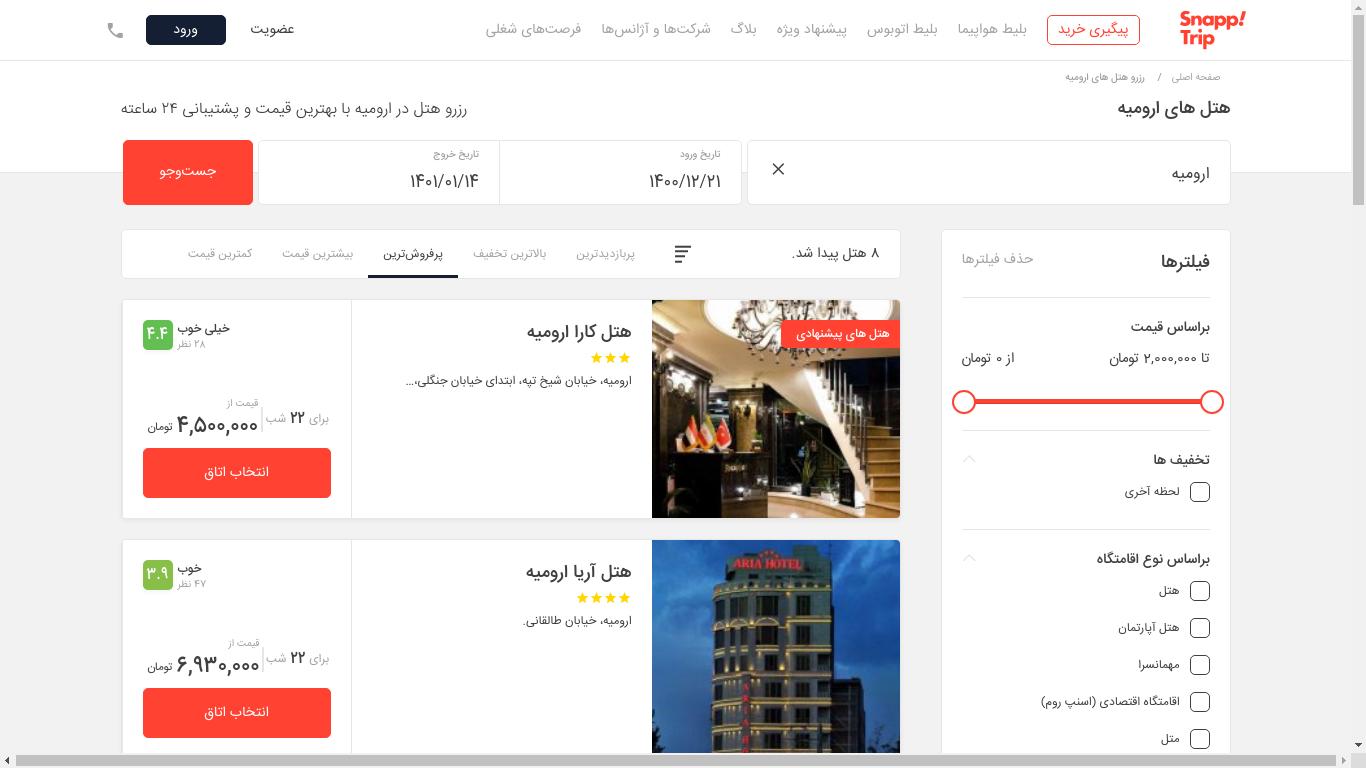
در نهایت، شما با کلیک بر روی هتلهای مختلف، اقدام به مقایسه آنها میکنید و **شاید** در نهایت یکی از آنها را رزرو کنید.
# دادگان
در این سوال، شما به دادگان جستجوی کاربران [از اینجا](https://static.quera.ir/dl/hotels.zip) دسترسی دارید. هنگامی که این فایل را از حالت فشرده خارج کنید. پوشه `hotels` را میبینید. در صورتی که وارد این پوشه شوید، فایلهای آموزش (`train.csv`) و آزمایش (`test.csv`) در اختیار شما خواهند بود.
فایل آموزش، نتایج جستجوی کاربران را در یک بازه حدودا ۲ ساله شامل میشود و حدود ۳۰ میلیون سطر دارد. فایل آزمایش، دارای ۱۰۰ هزار سطر از اطلاعات جستجوی کاربران در بازه حدود ۱ ماه پس از آخرین جستجوی موجود در فایل آزمایش است (این سطرها، به صورت تصادفی از بین چند میلیون سطر آن ماه، انتخاب شدهاند).
جدول زیر، ستونهای موجود در فایل آموزش را توضیح میدهد. توجه داشته باشید که هر ردیف این دادگان، نشاندهنده جستجوی یک کاربر جهت رزرو هتل است.
| نام ستون | توضیحات ستون |
|:----------|:------------------:|
| user | شناسه کاربر |
| search_date | زمان انجام جستجو |
| channel | کاربر از چه کانالی وارد سایت شدهاست (تبلیغات پیامکی، تبلیغات شبکه اجتماعی، ورود مستقیم و ...) |
| is_mobile | آیا کاربر با دستگاه موبایل وصل شدهاست؟ |
| is_package | آیا کاربر در حال جستجوی هتل به همراه بلیط اتوبوس یا هواپیما یا قطار است؟|
| destination | شناسه مقصد مورد نظر کاربر |
| checkIn_date | تاریخ ورود به هتل |
| checkOut_date | تاریخ خروج از هتل |
| n_adults | تعداد افراد بالغ اعلام شده جهت رزرو هتل |
| n_children | تعداد کودکان اعلام شده جهت رزرو هتل |
| n_rooms | تعداد اتاق مورد نظر برای رزرو |
| hotel_category | گروهبندی هتلی که جزییاتش را مشاهده میکنند. این گروهبندی میتواند بر اساس مواردی مانند چندستاره بودن و یا نوع هتل باشد. |
| is_booking | آیا کاربر در نهایت، هتل مشاهده شده را رزرو کرد؟ |
<details class="yellow">
<summary>
**توجه**
</summary>
لطفا در هنگام کار با این دادگان، به نکات زیر توجه داشته باشید:
+ فایل آزمایش، ستون `is_booking` را ندارد.
+ مجموع فایلهای `unzip`شده دادگان آموزش و آزمایش روی هم، دارای اندازه حدود ۳ گیگابایتی میباشند. نحوه روبهرو شدن شما با دادگان با این حجم، جزو یکی از چالشها و اهداف طراحی این سوال بودهاست.
</details>
# صورت مسئله
با استفاده از دادگان توضیح داده شده در بالا، اسنپتریپ از شما انتظار دارد که بر اساس فایل آموزش، مُدلی آموزش دهید که بر اساس جستجوی کاربران و سایر ویژگیهای مرتبط با آن، بتواند پیشبینی کند که آیا یک کاربر، هتل مشاهده شده را رزرو خواهد کرد یا نه (فایل آزمایش، مشخصات جستجوهایی را شامل میشود که بایستی احتمال رزرو شدن هتل را برای آنها، پیشبینی کنید). بدین ترتیب، مجموعه اسنپتریپ، میتواند برای هرکاربر، متناسب با پیشبینی رزرو، تصمیم متناسبی همانند ارائه تخفیف و یا پیشنهاد سایر هتلها، در لحظه اتخاذ کند.
در این سوال باید احتمال رزرو شدن هتل را پیشبینی کنید. به عبارت بهتر احتمال `True` شدن ستون `is_booking` را تخمین بزنید.
<details class="pink">
<summary>
**راهنمایی**
</summary>
**شاید** نکات زیر، بتوانند به شما در حل این مسئله کمک بکنند:
+ اگر که تمامی دادگان آموزش در حافظه (`RAM`) جا نمیشوند، شاید بتوانید به صورت بخشبخش آن را بخوانید و یا فقط از بخشی از دادگان آموزش به انتخاب **خود** و نه همه آن، استفاده کنید. همچنین طراحی یک ساختمان داده مناسب همچون لیست ولی با تفاوتهایی در بارگذاری دادگان، میتواند یک راهحل دیگر باشد.
+ محاسبه ویژگی (`feature`)های مناسب
+ استفاده از یادگیری تحت نظارت (`supervised`)
+ یا استفاده از هر روش مرتبط دیگر با تحلیل داده، یادگیری ماشین و عمیق
</details>
## ارزیابی
برای ارزیابی مُدل شما از سطح زیر ناحیه نمودار ``ROC`` استفاده میشود. برای مطالعه بیشتر در مورد این نمودار میتوانید [ویکیپدیا](https://en.wikipedia.org/wiki/Receiver_operating_characteristic) یا [راهنمای کوتاه نکات و ترفندهای یادگیری ماشین](https://stanford.edu/~shervine/l/fa/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks) را مطالعه کنید.
امتیاز نهایی مدل شما طبق فرمول زیر محاسبه میشود:
$$ score = ((AUCROC\times100)-50)\times4$$
<details class="green">
<summary>
**توضیحات**
</summary>
علت استفاده از این فرمول برای امتیازدهی، این است که اگر به صورت تصادفی برای جستجوها عددی پیشبینی کنید، ``auc_roc`` مدل شما ۰.۵ خواهد بود. بنابراین تنها مدلهایی پذیرفته میشوند که دارای ``auc_roc`` بیشتر از ۰.۵ باشند. توجه داشته باشید که بیشترین امتیاز ممکن از این سوال ۲۰۰ و کمترین امتیاز ممکن، صفر است.
</details>
## خروجی
پیشبینیهای مدل خود بر روی دادگان آزمایش (`test.csv`) را در فایلی با نام `output.csv` قرار دهید. این فایل باید دارای یک ستون با نام `prediction` باشد که ردیف i ام ستون `prediction`، پیشبینی شما برای سطر ردیف i ام فایل آزمایش باشد (دقت کنید که این ستون باید حتما دارای `header` باشد).
بعد از آمادهسازی فایل `output.csv`، آن را برای ما بارگذاری کنید.
## نمونه خروجی فایل `output.csv` (فقط سه خط اول به همراه نام ستون)
```
prediction
0.723
0.516
0.281
```
<details class="yellow">
<summary>
**توجه**
</summary>
حتما فایل `output.csv` باید دارای ۱۰۰,۰۰۰ سطر (بدون در نظر گرفتن `header`) و یک ستون باشد.
همچنین نام ستون بایستی بدون `space` در قبل و بعد از نام آن، باشد. در غیر این صورت، سیستم داوری نمرهای به شما نخواهد داد.
</details>
<details class="red">
<summary>
**هشدار 😱**
</summary>
فراموش نکنید که **قبل از پایان زمان مسابقه**، **بایستی** تمامی کدهای این مسابقه را از قسمت **بارگذاری کُد** برای ما ارسال کنید. در غیر این صورت، شما از این مسابقه، امتیازی کسب نمی کنید.
توجه داشته باشید که اگر از `jupter notebook` استفاده می کنید بایستی همانند توضیحات قسمت **بارگذاری کُد**، خروجی `.py` را دریافت و برای ارسال در نظر بگیرید. ارسال فایلهای `jupyter` همانند `.ipynb` مورد قبول واقع نخواهند شد.
</details>
پیشبینی رزرو هتل
با اپلیکیشن [اسنپفود](https://snappfood.ir) به راحتی میتوانید با چند کلیک ساده، رستورانها، کافهها و شیرینیفروشیهای نزدیک خودتان را جستوجو و از تجربه سفارش آسان اسنپفود لذت ببرید. 😋
فروشندگان میتوانند اقلام خوراکی خود را در اسنپفود قرار دهند تا کاربران با بررسی قیمت و عکس خوراکیها و نظرات کاربران دیگر، خوراکی مورد نظر خود را انتخاب کنند.
**شما** به عنوان یک سفارشدهنده غذا، میتوانید از نظرات دیگر مشتریان راجع به کیفیت یک رستوران آگاه شوید. بهعنوان مثال، میتوانید میزان لذیذ و خوشمزه بودن قرمهسبزی یک یا چند رستوران را با توجه به نظرات ثبتشده سفارشدهندگان پیشین بسنجید.

سپس، خودتان نیز میتوانید تجربهتان راجع به سفارش را با دیگران به اشتراک بگذارید. پس از دیدگاه سفارشدهنده، نظرات بسیار پراهمیت هستند.
از دیدگاه اسنپفود نیز نظرات بسیار مهم هستند زیرا میتواند عملکرد همکاران (رستورانها، تولیدکنندگان غذا و پیک) را از طریق آن رصد کند تا بتواند میزان رضایت مشتریان را افزایش دهد. 😎
در این سوال میخواهیم به اسنپفود در تحلیل احساس موجود در نظرات، کمک کنیم. 🤗
# دادگان
دادگان این مسئله را میتوانید از [این لینک](/contest/assignments/35056/download_problem_initial_project/118269/) دانلود کنید. هنگامی که این فایل را از حالت فشرده خارج کنید. پوشه `comments` را میبینید. در صورتی که وارد این پوشه شوید، فایل آموزش (`train.csv`) و آزمایش (`test.csv`) را مشاهده میکنید. فایل آموزش، دارای ساختار زیر (با دو ستون) اس:
| نام ستون | توضیحات ستون |
|:----------|:------------------:|
| comment | نظر یک مشتری راجع به یک سفارش |
| date | زمان ثبت نظر |
عمده نظرات موجود در ستون `comment` به زبان فارسی هستند؛ اما تعداد محدودی از نظرات وجود دارند که به زبان انگلیسی ثبت شدهاند. مدیریت این چالش بخشی از فرایند حل مسئله است.
همچنین تنها تفاوت دادگان آموزش با آزمایش در این است که دادگان آزمایش، ستون `date` ندارند.
<details class="yellow">
<summary>
**نداشتن برچسب**
</summary>
دادگان آموزش و آزمایش هیچگونه برچسبی ندارند. همانطور که در بخش بعدی (صورت مسئله) خواهید دید، شما خودتان باید برچسب هر نظر را مشخص کنید.
</details>
<details class="blue">
<summary>
**محرمانگی**
</summary>
به دلیل رعایت محرمانگی دادگان، از انتشار نام فرد نظردهنده، شناسه سفارش و اطلاعات رستوران/کافه/شیرینیفروشی مربوطه، معذوریم! 😉
</details>
<details class="yellow">
<summary>
**توجه**
</summary>
به علت فارسی بودن متن نظرات، **ممکن** است نرمافزار اکسل در نمایش آن با مشکل مواجه شود. بر فرض اینکه از زبان پایتون استفاده میکنید، کتابخانه پانداس در بارگذاری متون فارسی به شما میتواند کمک کند.
</details>
# صورت مسئله
اسنپفود از شما میخواهد `positive` یا `negative` بودن نظرات را مشخص کنید. دسته `positive` نظراتی را نشان میدهد که ثبتکننده نظر، از سفارش خود راضی بوده و **احساس مثبتی** از تعامل با اسنپفود و همکارانش بهدست آوردهاست. در مقابل، دسته `negative` نظراتی را نشان میدهد که ثبتکننده آن احساس خوبی از سفارش خود نداشتهاست.
**شما** بایستی که با استفاده از دادگان آموزش، بتوانید مُدلی بسازید که **احتمال** `positive` بودن احساس نظرات موجود در دادگان آزمایش (`test.csv`) را شناسایی کند.
<details class="pink">
<summary>
**راهنمایی**
</summary>
**شاید** یکی از روشهای زیر، بتواند به شما در حل این مسئله کمک بکند:
+ ابتدا با استفاده از یادگیری بدوننظارت (`unsupervised`)، نظرات فایل `train.csv` را به دو دسته `positive` و `negative` گروهبندی کنید، سپس با روشهای یادگیری نظارتشده (`supervised`)، مدلی را آموزش دهید که بتواند **احتمال** `positive` بودن یک نظر را تخمین بزند.
+ خودتان و یا با استفاده از روشهای قانونمند (`rule-based`) مانند `weak supervision` اقدام به برچسبزدن همه یا قسمتی از دادگان آموزش بکنید، سپس با روشهای یادگیری نظارتشده (`supervised`)، مدلی را آموزش دهید که بتواند **احتمال** `positive` بودن یک نظر را تخمین بزند.
+ یا استفاده از هر روش دیگر که مرتبط با تحلیل داده/متن، یادگیری ماشین و عمیق است.
</details>
# ارزیابی
امتیاز نهایی مُدل شما تابعی از سطح زیر ناحیه نمودار `ROC` است. برای مطالعه بیشتر در مورد این نمودار میتوانید [ویکیپدیا](https://en.wikipedia.org/wiki/Receiver_operating_characteristic) یا [راهنمای کوتاه نکات و ترفندهای یادگیری ماشین](https://stanford.edu/~shervine/l/fa/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks) را مطالعه کنید.
امتیاز نهایی مدل شما، طبق فرمول زیر محاسبه میشود:
$$ score = ((AUCROC\times100)-50) \times4$$
<details class="green">
<summary>
**توضیحات**
</summary>
علت استفاده از این فرمول برای امتیازدهی، این است که اگر به صورت تصادفی برای نظرات عددی پیشبینی کنید، `auc_roc` مدل شما ۰.۵ خواهد بود. بنابراین تنها مدلهایی پذیرفته میشوند که دارای `auc_roc` بیشتر از ۰.۵ باشند. توجه داشته باشید که بیشترین امتیاز ممکن از این سوال ۲۰۰ و کمترین امتیاز ممکن، صفر است.
</details>
# خروجی
پیشبینیهای مدل خود بر روی دادگان آزمایش (`test.csv`) را در فایلی با نام `output.csv` قرار دهید. این فایل باید دارای یک ستون به اسم `prediction` باشد که ردیف i ام ستون `prediction`، پیشبینی شما (**احتمال **`positive` بودن نظر - عددی بین صفر و یک) برای نظر ردیف i ام از فایل `test.csv` باشد (دقت کنید که ستون باید حتما دارای `header` باشد). بعد از آمادهسازی فایل `output.csv`، آن را برای ما بارگذاری کنید.
## نمونه خروجی فایل `output.csv` (فقط سه خط اول به همراه نام ستون)
```
prediction
0.723
0.516
0.281
```
<details class="yellow">
<summary>
**توجه**
</summary>
حتما فایل `output.csv` باید دارای ۱۴,۰۰۰ سطر (بدون در نظر گرفتن `header`) و یک ستون باشد.
همچنین نام ستون بایستی بدون `space` در قبل و بعد از نام آن، باشند. در غیر این صورت، سیستم داوری نمرهای به شما نخواهد داد.
</details>
<details class="red">
<summary>
**هشدار 😱**
</summary>
فراموش نکنید که **قبل از پایان زمان مسابقه**، **بایستی** تمامی کدهای این مسابقه را از قسمت **بارگذاری کُد** برای ما ارسال کنید. در غیر این صورت، شما از این مسابقه، امتیازی کسب نمی کنید.
توجه داشته باشید که اگر از `jupter notebook` استفاده می کنید بایستی همانند توضیحات قسمت **بارگذاری کُد**، خروجی `.py` را دریافت و برای ارسال در نظر بگیرید. ارسال فایلهای `jupyter` همانند `.ipynb` مورد قبول واقع نخواهند شد.
</details>
تحلیل احساس نظرات
با اپلیکیشن [اسنپفود](https://snappfood.ir/) به راحتی میتوانید با چند کلیک ساده، رستورانها، کافهها و شیرینیفروشیهای نزدیک خودتان را جستوجو و از تجربه سفارش آسان اسنپفود لذت ببرید. 😋

فروشندگان میتوانند اقلام خوراکی خود را در اسنپفود قرار دهند تا کاربران با بررسی قیمت و عکس خوراکیها و نظرات کاربران دیگر، خوراکی مورد نظر خود را انتخاب کنند.
با بررسی تصاویری که مردم در شبکههای اجتماعی به اشتراک میگذارند، میتوان ترتیب قرار گرفتن خوراکیها را ارتقا داد. برای مثال، خوراکیهایی که در شبکههای اجتماعی مورد توجه قرار گرفتهاند را در ابتدای سایت یا اپلیکیشن قرار داد. همچنین برای هر کاربر، یک لیست شخصیسازی شده از خوراکیهای مورد علاقهاش را پیشنهاد داد.
برای استقاده از این امکانات، در قدم اول باید بتوانیم نوع غذای موجود در یک عکس را شناسایی کنیم و این دقیقا کاری است که ما انتظار داریم شما در این سوال انجام دهید.
# دادگان
در این سوال شما به دادگان عکس خوراکیها دسترسی دارید. در این مجموعه، بیش از ۱۷ هزار عکس از ۲۱ نوع خوراکی وجود دارند که تعدادی از آنها را در عکس زیر میبینید:

برای دریافت دادگان این سوال، از [اینجا](https://drive.google.com/file/d/1sr-3p_1GqCuXStSaz3__Lw4s3lbBtwSD/view?usp=sharing) اقدام کنید. بعد از `unzip` کردن آن، داخل پوشه `food` بروید و دادگان آموزش را در پوشه `train`، پیدا کنید. داخل این پوشه، برای هر نوع خوراکی، یک پوشه جدا وجود دارد که شامل تصاویر آن میباشد. همچنین تصاویر دادگان آزمایش این سوال، در پوشه `test` قرار دارند. روی هم رفته حجم کل عکسها حدود **یک گیگابایت** میباشد.
<details class="pink">
<summary>
**راهنمایی**
</summary>
**شاید** یکی از روشهای زیر (یا ترکیب آنها)، بتواند به شما در حل این مسئله کمک بکند:
+ **استفاده از روشهای یادگیری عمیق مانند `transfer learning` و `CNNs`**
+ **استفاده از روشهای افزایش تعداد عکس (`data augmentation`)**
+ **استفاده از هر روش مرتبط با بینایی ماشین، یادگیری ماشین و عمیق**
</details>
<details class="yellow">
<summary>
**توجه**
</summary>
در هنگام کار با این دادگان، به نکات زیر توجه داشته باشید:
+ هر عکس، تنها شامل یک نوع خوراکی میباشد.
+ ابعاد عکسها یکسان نیستند و طول و عرض هر عکس حداکثر ۵۱۲ پیکسل میباشد.
+ برچسبهای دادگان آموزش، توسط نیروی انسانی انجام شدهاست. به همین دلیل، شاید تعدادی از عکسهای هر نوع غذا، به اشتباه برچسب خورده باشند. مدیریت این مسئله، جزوی از چالش این سوال و بر عهده شما میباشد.
</details>
# ارزیابی
برای ارزیابی نتیجه کار، از معیار دقت (`accuracy`) در اعلام **نوع خوراکی** موجود در یک عکس استفاده میشود. یعنی تعداد عکسهای درست پیشبینی شده تقسیم بر تعداد کل تصاویر موجود میشود.
امتیاز نهایی مدل شما نیز، طبق رابطه زیر محاسبه میشود:
$$ score = ((accuracy\times100)-20)\times2.5$$
<details class="green">
<summary>
**توضیحات**
</summary>
با استفاده از رابطه بالا، افرادی که دقت مدلشان، ۲۰ درصد و یا کمتر از آن است، از این سوال، امتیازی کسب نمیکنند. توجه داشته باشید که بیشترین امتیاز ممکن از این سوال ۲۰۰ و کمترین امتیاز ممکن، صفر است.
</details>
# ارسال پاسخ
پیشبینیهای مدل خود بر روی دادگان آزمایش را در فایلی با نام `output.csv` قرار دهید. این فایل باید دارای دو ستون با نامهای `file` و `prediction` به ترتیب باشند. در هر ردیف، نام فایل را در `file` و پیشبینی خود از **نوع خوراکی** را در ستون `prediction` قرار دهید (دقت کنید که فایل `CSV` باید حتما دارای `header` باشد).
بعد از آمادهسازی فایل `output.csv`، آن را برای ما بارگذاری کنید.
## نمونه خروجی فایل `output.csv` (فقط سه خط اول به همراه نام ستونها)
```
file,prediction
005YYST06V93A.jpg,ice_cream
011VG8PFN3W2W.jpg,spaghetti
014XUHGNX7Z1M.jpg,spaghetti
```
<details class="yellow">
<summary>
**توجه**
</summary>
حتما فایل `output.csv` باید دارای ۴,۲۷۶ سطر (بدون در نظر گرفتن `header`) و دو ستون باشد.
همچنین نام ستونها بایستی بدون `space` در قبل و بعد از نام آن، باشند. در غیر این صورت، سیستم داوری نمرهای به شما نخواهد داد.
</details>
<details class="red">
<summary>
**هشدار 😱**
</summary>
فراموش نکنید که **قبل از پایان زمان مسابقه**، **بایستی** تمامی کدهای این مسابقه را از قسمت **بارگذاری کُد** برای ما ارسال کنید. در غیر این صورت، شما از این مسابقه، امتیازی کسب نمی کنید.
توجه داشته باشید که اگر از `jupter notebook` استفاده می کنید بایستی همانند توضیحات قسمت **بارگذاری کُد**، خروجی `.py` را دریافت و برای ارسال در نظر بگیرید. ارسال فایلهای `jupyter` همانند `.ipynb` مورد قبول واقع نخواهند شد.
</details>
دستهبندی خوراکی

شرکتهای مختلف مجموعه اسنپ نیاز به استفاده از [سیستمهای پیشنهاددهنده](https://fa.wikipedia.org/wiki/%D8%B3%D8%A7%D9%85%D8%A7%D9%86%D9%87_%D8%AA%D9%88%D8%B5%DB%8C%D9%87%E2%80%8C%DA%AF%D8%B1)، جهت پیشنهاد محصول به مشتریان خود دارند. آنها میتوانند با استفاده از تاریخچه امتیاز مشتریان به محصولات مختلف، اقدام به پیشنهاد محصول بکنند، به گونهای که مشتری از محصول پیشنهاد شده استقبال بکند. 😎
بهعنوان مثال:
+ [اسنپتریپ](https://www.snapptrip.com) میتواند هتلهایی را به مسافران پیشنهاد دهد که مسافران مشابه، از آنها راضی بودهاند.
+ [اسنپفود](https://bayanbox.ir/view/2316820097983697622/snappfood.png) میتواند بر اساس امتیاز مشتریان به رستورانها و یا غذاها اقدام به پیشنهاد رستوران/غذا به مشتریان دیگر بکند.
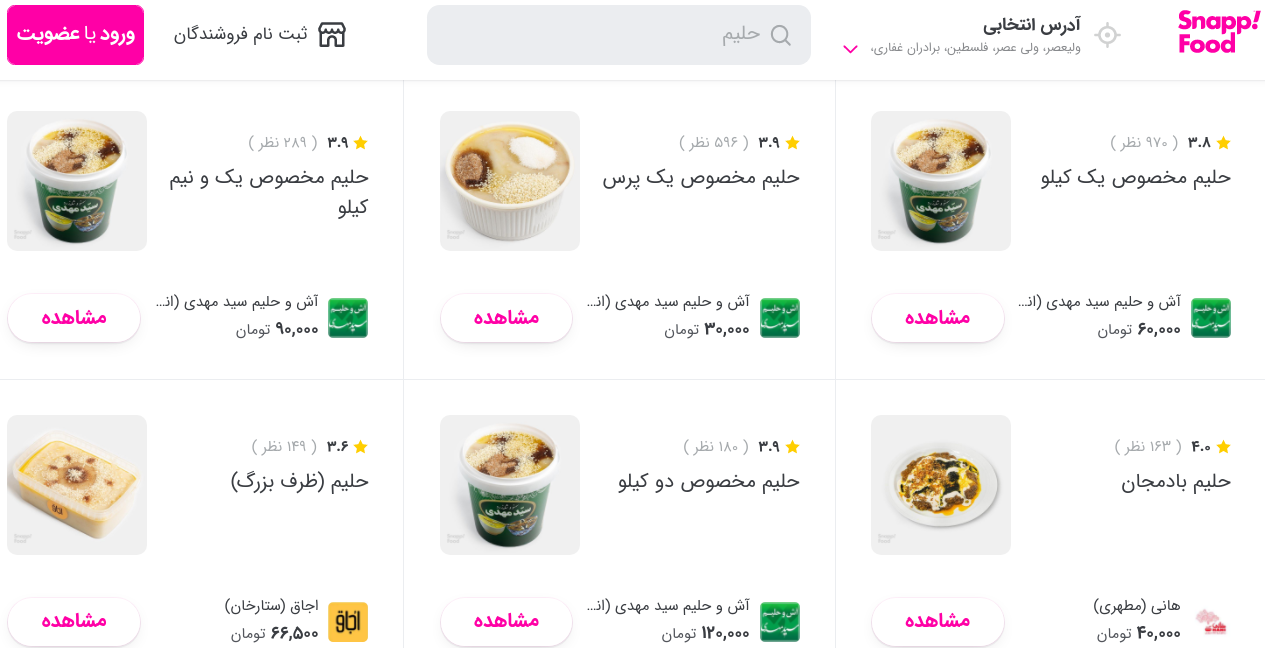
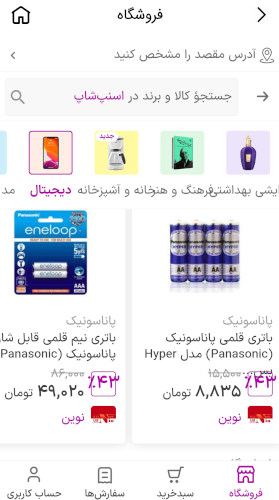
+ [اسنپشاپ](https://snapp.ir/shop?utm_source=snapp-website) میتواند محصولاتی که سیستم پیشنهاددهنده احتمال میدهد امتیاز بالایی از سمت یک سری از مشتریان کسب کند را به آنها با تخفیف شخصیسازی شده، پیشنهاد بدهد.
<details class="pink">
<summary>
**چند دقیقه برای تفکر** 🤔
</summary>
به نظر شما، هر یک از شرکتهای دیگر مجموعه اسنپ که در زیر آورده شدهاند، چه استفادهای از یک سیستم پیشنهاددهنده میتوانند داشته باشند؟
+ [اسنپدکتر](https://snapp.ir/medical-services?utm_source=snapp-website)
+ [اسنپکب](https://snapp.ir/taxi-ride?utm_source=snapp-website)
+ [اسنپمارکت](https://snapp.market)
جواب سوال بالا، جزوی از سوال مسابقه نیست و **صرفا** جهت تفکر و آشنایی شماست. 🤗
</details>
توجه داشته باشید که حتی میتوان از روی تحلیل احساس نظرات (سوال ۳ این مسابقه)، برای محاسبه امتیازی که هر مشتری به یک محصول میدهد، استفاده کرد. 😉
<details class="blue">
<summary>
**بیشتر بدانید** 📚
</summary>
سیستمهای پیشنهاددهنده دارای سابقه طولانی هستند. به عنوان مثال، میتوانید [از اینجا](https://en.wikipedia.org/wiki/Netflix_Prize) در مورد مسابقه سیستم پیشنهاددهنده شرکت پخش فیلم [Netflix](https://fa.wikipedia.org/wiki/%D9%86%D8%AA%D9%81%D9%84%DB%8C%DA%A9%D8%B3) که در سال ۲۰۰۶ شروع شد، مطالعه کنید.
</details>
# دادگان
در این سوال، شما به تاریخچه امتیازهای مشتریان به محصولات مختلف در طول زمان [از اینجا](https://drive.google.com/file/d/1-BivapOkCSDZclmOGAonw3jxRD4Fm4s5/view?usp=sharing) دسترسی دارید. هنگامی که این فایل را از حالت فشرده خارج کنید. پوشه `data` را میبینید. در صورتی که وارد این پوشه شوید، فایلهای آموزش (`train.csv`) و آزمایش (`test.csv`) در اختیار شما خواهند بود. فایل آموزش، اطلاعات امتیازدهی مشتریان به محصولات مختلف در یک بازه حدودا ۷.۵ سال را نشان میدهد.
جزییات فایل آموزش، در جدول زیر آمدهاست:
| نام ستون | توضیحات ستون |
|:----------|:------------------:|
| userId |شناسه مشتری|
| itemId |شناسه محصول|
| rating |امتیازی که مشتری به محصول مربوطه دادهاست که میتواند یکی از اعداد ۴،۳،۲،۱ یا ۵ باشد|
| date |زمانی که مشتری به محصول مربوطه، امتیاز دادهاست|
فایل آزمایش، برای یک بازه حدودا ۶ ماهه، بعد از زمان دادگان فایل آموزش است و دارای اطلاعات مشتریانی است که به محصولات مختلف در آن بازه، امتیاز دادهاند. توجه داشته باشید که این فایل دارای ستون `rating` نیست و همچنین تنها مشتریان و محصولاتی در آن موجودند که هر دوی آنها، قبلا در دادگان آموزش وجود داشته باشند.
# صورت مسئله
با استفاده از دادگان آموزش، یک مُدل برای یک سیستم پیشنهاددهنده بسازید که برای سهتایی (شناسهمشتری، شناسه محصول و زمان امتیاز دادن) دادگان آزمایش، امتیازی که مشتری میدهد را پیشبینی کند. بدین صورت، مجموعه شرکتهای اسنپ میتوانند محصولی را به یک مشتری پیشنهاد دهند که مطمئن هستند امتیاز بالایی را از سمت مشتری دریافت خواهد کرد. 🥳
<details class="pink">
<summary>
**راهنمایی**
</summary>
**شاید** روشهای زیر، بتوانند به شما در حل این مسئله کمک بکنند:
+ استفاده از روشهای مستقل از زمان/ترتیب مانند `collaborative filtering` و `content based` و یا ترکیبی از هر دو
+ استفاده از الگوریتمهای وابسته به زمان/ترتیب مانند `sequence neural networks` و `convolutional neural networks`
+ استفاده از هر روش مرتبط دیگر با تحلیل داده، سیستمهای پیشنهاددهنده، یادگیری ماشین و یادگیری عمیق
</details>
# ارزیابی
برای ارزیابی مُدل شما از معیار `Root Mean Square Error` یا به اختصار `RMSE` به شرح زیر استفاده میشود:
$$RMSE=\sqrt{\frac{\sum_{i=1}^{n}(r_i-\hat{r}_i)^2}{n}}$$
در فرمول بالا، $r_i$ مقدار واقعی `rating` برای سطر $i$ است و $\hat{r}_i$ نیز مقدار پیشبینی شده مُدل شما برای آن `rating` است. همچنین تعداد نمونههای دادگان را از شماره ۱ تا $n$ در نظر بگیرید. در نهایت، امتیاز شما از این مرحله بر اساس فرمول زیر محاسبه میگردد:
$$score=(1.04-RMSE)\times\frac{100}{104}\times200$$
<details class="green">
<summary>
**توضیحات**
</summary>
یک تابع تصادفی یا تابعی که همیشه یک امتیاز ثابت را پیش بینی میکند، حداقل `RMSE` برابر با ۱.۰۴ برای دادگان این سوال دارد. پس، مدلهایی که `RMSE` آنها ۱.۰۴ یا بزرگتر از آن باشد، به عنوان مدل مناسب این مسئله، مورد قبول قرار نمیگیرند و هرمدلی که چنین عملکردی را روی دادگان آزمایش داشتهباشد، امتیازی از این سوال کسب نمیکند.
</details>
<details class="yellow">
<summary>
**توجه**
</summary>
لطفا در هنگام کار با این دادگان، به نکات زیر توجه داشته باشید:
+ مقدار `RMSE` مدل شما، تا سه رقم اعشار محاسبه (رُند) و در فرمول امتیازدهی بالا، قرار داده میشود.
+ این سوال، امتیاز منفی ندارد. حتی اگر `score` شما، منفی شود. از این سوال حداقل **صفر** امتیاز میگیرید. 😜
+ بیشترین امتیاز ممکن از این سوال ۲۰۰ و کمترین امتیاز ممکن، صفر است.
</details>
# خروجی
پیشبینیهای مدل خود بر روی دادگان آزمایش (`test.csv`) را در فایلی با نام `output.csv` قرار دهید. این فایل باید دارای یک ستون با نام `prediction` باشد که ردیف iام آن، پیشبینی شما برای سطر iام دادگان آزمایش باشد (دقت کنید که این ستون باید حتما دارای `header` باشد).
بعد از آمادهسازی فایل `output.csv`، آن را برای ما بارگذاری کنید.
## نمونه خروجی فایل `output.csv` (فقط سه خط اول به همراه نام ستون)
```
prediction
5
1
3
```
<details class="yellow">
<summary>
**توجه**
</summary>
حتما فایل `output.csv` باید دارای ۱۳۱,۳۵۸ سطر (بدون در نظر گرفتن `header`) و یک ستون باشد.
همچنین نام ستون بایستی بدون `space` در قبل و بعد از نام آن، باشد. در غیر این صورت، سیستم داوری نمرهای به شما نخواهد داد.
پیشبینیهای شما از `rating`ها، میتوانند به صورت عدد اعشاری نیز ارسال بشوند.
</details>
<details class="red">
<summary>
**هشدار 😱**
</summary>
فراموش نکنید که **قبل از پایان زمان مسابقه**، **بایستی** تمامی کدهای این مسابقه را از قسمت **بارگذاری کُد** برای ما ارسال کنید. در غیر این صورت، شما از این مسابقه، امتیازی کسب نمی کنید.
توجه داشته باشید که اگر از `jupter notebook` استفاده می کنید بایستی همانند توضیحات قسمت **بارگذاری کُد**، خروجی `.py` را دریافت و برای ارسال در نظر بگیرید. ارسال فایلهای `jupyter` همانند `.ipynb` مورد قبول واقع نخواهند شد.
</details>
پیشنهاد محصول
به منظور جلوگیری از هر گونه تقلب و شبهه احتمالی که منجر به ضایع شدن حق شما شود، شما بایستی که فایل کد برنامهنویسی (مثلا برای پایتون فایل `.py`، برای زبان `R` فایل `.R`، برای متلب فایل `.m` و برای جاوا فایل `.java`) را در قالب یک فایل زیپ در اینجا بارگذاری نمایید. در صورتی که پس از پایان زمان مسابقه، این فایل توسط شما بارگذاری نشده باشد، شما از این مسابقه، امتیازی کسب نمی کنید.
توجه داشته باشید که اگر از `jupter notebook` استفاده می کنید بایستی همانند توضیح بالا، خروجی مورد نظر را دریافت کنید. به عنوان مثال، شما بایستی که از قسمت `file` و زیرقسمت `Download` خروجی `.py` را دریافت و برای ارسال در نظر بگیرید. ارسال فایلهای `jupyter` همانند `.ipynb` مورد قبول واقع نخواهند شد.
برای هر سوال که جواب دادید، یک پوشه به نام آن سوال ایجاد و تمامی کدهای خود را در آن قرار دهید. در نهایت، همه پوشهها را تحت یک پوشه نهایی زیپ کرده و برای ما **فقط یک فایل زیپ** ارسال کنید.
به عنوان مثال اگر که از زبان پایتون استفاده کردید، فایل زیپ ارسالی شما، بایستی که ساختار زیر را داشته باشد:
```
solution
└───timeseries
│ │ code.py
└───tabular
│ │ code.py
└───text
│ │ code.py
└───image
│ │ code.py
└───recommendation
│ │ code.py
```
<details class="blue">
<summary>
**توجه**
</summary>
میتوانید به جای فایلهای `code.py`، هر تعداد فایل با پسوندهای مجاز و توضیح داده شده زبانهای برنامهنویسی قرار دهید.
</details>
# توجه: از ارسال دادگان بپرهیزید!
با تشکر فراوان