+ محدودیت زمان: ۴ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
قواعد **بازی زندگی (Game of Life)** که توسط **جان کانوی** طراحی شده است، ساده هستند اما رفتارهای پیچیدهای را تولید میکنند. این بازی در یک شبکهی دوبعدی انجام میشود که هر خانه میتواند دو حالت داشته باشد: زنده (`1`) یا مرده (`0`). تغییر وضعیت هر خانه براساس وضعیت همسایههای آن رخ میدهد. در ضمن در نظر داشته باشید که دو خانه را همسایه میگوییم اگر در یک نقطه یا یک ضلع مشترک باشند.
### قواعد بازی
1. **هر سلول زنده با کمتر از دو همسایهی زنده میمیرد** (تنهایی).
2. **هر سلول زنده با دو یا سه همسایهی زنده، زنده میماند** (ثبات).
3. **هر سلول زنده با بیش از سه همسایهی زنده میمیرد** (ازدحام).
4. **هر سلول مرده با دقیقاً سه همسایهی زنده، زنده میشود** (تولد).
5. **هر سلول مرده با غیر از سه همسایهی زنده، مرده میماند** (مرگ).
برنامهای بنویسید که یک جدول $n \times n$ بگیرد، که هر خانهی آن `0` (مرده) یا `1` (زنده) است. این برنامه باید پس از هر مرحله، وضعیت جدید سلولها را با توجه به قواعد بازی زندگی به روز کند و نتیجه را چاپ کند.
# ورودی
در سطر اول ورودی، یک صحیح $n$ داده میشود که اندازه جدول را مشخص میکند.
$$1 \leq n \leq 100$$
در $n$ سطر بعدی، یک جدول $n \times n$ شامل `0` و `1` که وضعیت اولیهی بازی را مشخص میکند.
# خروجی
در $n$ سطر مانند ورودی، یک جدول از `0` و `1` چاپ کنید که وضعیت جدید جدول پس از یک مرحله بازی را مشخص کند.
# مثالها
## ورودی نمونه ۱
```
4
0 1 0 0
0 0 1 0
1 1 1 0
0 0 0 0
```
## خروجی نمونه ۱
```
0 0 0 0
1 0 1 0
0 1 1 0
0 1 0 0
```
## ورودی نمونه ۲
```
3
0 0 1
0 1 0
0 1 0
```
## خروجی نمونه ۲
```
0 0 0
0 1 1
0 0 0
```
بازی زندگی
+ محدودیت زمان: ۴ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
کیوکافه که به تازگی آغاز به کار کرده با مشکلات مالی زیادی روبرو است. ما در این کافه $n$ مشتری داریم که هرکدام سفارشی دارند. سفارشهای مشتریان شامل مخلوطی از اسپرسو، شیر با درصدهای مختلف است. برای اینکه حجم نهایی نوشیدنیها ثابت باشد، باقیماندهی حجم آن را با آب پر میکنیم. برای مثال سفارش یک نفر شامل $30\%$ شیر و $60\%$ اسپرسو است و باقی آن با آب پر میشود. یا فرد دیگری سفارش شیر $70\%$ و اسپرسو $15\%$ دارد و در نتیجه $15\%$ آب به آن اضافه میکنیم.
افراد، به ترتیب دلخواه ما، به یک صف وارد میشوند و تا جایی که مواد اولیه برای تهیه نوشیدنی داریم، سفارشها را تحویل میدهیم.
هر فردی که سفارش او تحویل داده شود، خوشحال و کسی که به او نوشیدنی نرسد، ناراحت میشود.
میخواهیم کمترین میزان شیر و قهوهی اولیه (در مجموع) را تهیه کنیم که بیش از نصف مشتریان خوشحال باشند. همچنین اگر چند روش مختلف برای تهیه شیر و قهوه وجود دارد روشی را در نظر بگیرید که مقدار شیر مورد نیاز کمینه باشد.
# ورودی
در سطر اول ورودی عدد $n$، تعداد مشتریان، داده میشود. سپس در $n$ سطر بعدی در هر سطر دو عدد $a$ و $b$ داده میشود که به ترتیب نشاندهنده درصد شیر و درصد قهوهی مورد نیاز است.
$$1 \leq n \leq 100 \, 000$$
$$0 \leq a, b \leq 100, \quad 1 \leq a + b \leq 100$$
# خروجی
در تنها سطر خروجی، دو عدد $x$ و $y$ باید چاپ شوند که به ترتیب نشاندهنده میزان شیر اولیه و قهوه اولیه برای تهیه است. اگر چند روش مختلف برای تهیه وجود دارد روشی را در نظر بگیرید که مقدار شیر مورد نیاز کمینه باشد.
# مثالها
## ورودی نمونه ۱
```
3
10 80
75 20
40 60
````
## خروجی نمونه ۱
```
85 100
````
## ورودی نمونه ۲
```
2
100 0
0 100
````
## خروجی نمونه ۲
```
100 100
````
قهوه چی میزنی؟
+ محدودیت زمان: ۴ ثانیه
+ محدودیت حافظه: ۲۵۶ مگابایت
----------
در یک شرکت $n$ برنامهنویس مشغول به کار هستند. هر کدام از این $n$ نفر در برخی از زمینههای `Front-end`، `Back-end` یا `Product Mangement` تخصص دارد.
تخصصهای هر شخص با یک رشته شامل حروف `B`، `F` و `P` به صورت مرتبشده الفبایی به ما داده شده است.
میخواهیم با داشتن این تخصصها، حداکثر تعدادی تیم کامل را تشکیل دهیم. منظور از یک تیم کامل تیمی است که در آن برای هر کدام از این سه زمینه حداقل یک متخصص وجود داشته باشد (ممکن است یک نفر باعث برطرف شدن نیاز چند تخصص باشد). توجه کنید باید در این تیمبندی هر شخص در حداکثر یک تیم آمده باشد.
حال از شما میخواهیم برنامهای بنویسید که این بیشترین تعداد تیم را محاسبه کند. برای بهتر متوجه شدن خواستهی سوال، توضیحات نمونهها را مطالعه کنید.
# ورودی
در سطر اول ورودی، عدد صحیح و مثبت $t$ آمده که تعداد تستها را نشان میدهد.
$$1 \leq t \leq 10 \,000$$
در سطر اول هر تست، عدد صحیح و مثبت $n$ داده میشود که تعداد برنامهنویسها را نشان میدهد.
$$1 \leq n \leq 100$$
در یک سطر $n$ رشته با فاصله داده میشود که رشتهی سطر $i$ام تخصص برنامهنویس $i$ام را نشان میدهد.
# خروجی
در تنها سطر خروجی، یک عدد صحیح برابر بیشترین تعداد تیم کامل را چاپ کنید.
# مثالها
## ورودی نمونه ۱
```
3
5
B F P BFP BF
4
BF BP FP B
2
B BFP
````
## خروجی نمونه ۱
```
2
2
1
````
در نمونهی اول تیمبندی میتواند به صورت زیر باشد:
$$\{B, F, P\},\quad \{BFP\}$$
در نمونهی دوم تیمبندی میتواند به صورت زیر باشد:
$$\{B, FP\}, \quad \{BF, BP\}$$
در نمونهی سوم تیمبندی میتواند به صورت زیر باشد:
$$\{BFP\}$$
تیمهای توسعه سختکوش
**کد شما باید روی PostgreSQL قابل اجرا باشد.**
---
# جزئیات پایگاهداده
دیتابیسی که در این سوال به آن میپردازیم، متشکل از اطلاعات تعدادی کاربر، شرکت و محصولات شرکتها خواهد بود.
دادههای اولیه را از [این لینک](/contest/assignments/73613/download_problem_initial_project/253334/) دانلود کنید.
<details class="yellow">
<summary>
**ایمپورت کردن دادههای اولیه**
</summary>
از نصب بودن *PostgreSQL* روی سیستم خود اطمینان حاصل کنید.
برای ایمپورت کردن دادههای اولیه میتوانید از یکی از دو روش زیر اقدام کنید:
۱- با استفاده _CLI_ دستور زیر را وارد کنید تا دادههای اولیه ایمپورت شوند:
```shell
psql -U postgres -f /path/to/initial.sql
```
که در این دستور مسیر فایل `initial.sql` را به صورت مطلق یا نسبی میتوانید آدرسدهی کنید.
۲- اگر _GUI_ را ترجیح میدهید، پس از نصب دیتاگریپ و اتصال به _PostgreSQL_ با یوزر `postgres`، باید روی دیتاسورس و کانکشن `postgres` راستکلیک کنید و از منوی `SQL Scripts`، گزینهی `Run SQL Script` را انتخاب کنید. سپس فایل `initial.sql` را پیدا و تایید کنید. در انتها روی `Run` کلیک کنید تا اسکریپت اجرا شود و دادهها وارد دیتابیس شوند.
</details>
<details class="grey">
<summary>
**توضیحات جداول دیتاست**
</summary>
### جدول `address` (آدرسها)
این جدول اطلاعات مربوط به آدرسها را ذخیره میکند.
| نام ستون | نوع داده | توضیحات |
|----------------|----------------|------------------------------------|
| `id` | `integer` | شناسهی یکتا برای آدرس (کلید اصلی) |
| `city` | `varchar(100)` | شهر |
| `country` | `varchar(100)` | کشور |
| `country_code` | `varchar(100)` | کد کشور |
| `zip_code` | `integer` | کد پستی |
### جدول `company` (شرکتها)
این جدول اطلاعات مربوط به شرکتها را ذخیره میکند.
| نام ستون | نوع داده | توضیحات |
|--------------|----------------|---------------------------------------------------|
| `id` | `integer` | شناسهی یکتا برای شرکت (کلید اصلی) |
| `name` | `varchar(100)` | نام شرکت |
| `address_id` | `bigint` | شناسهی آدرس مرتبط (کلید خارجی به جدول `address`) |
### جدول `product` (محصولات)
این جدول اطلاعات مربوط به محصولات را ذخیره میکند.
| نام ستون | نوع داده | توضیحات |
|------------|----------------|-------------------------------------|
| `id` | `integer` | شناسهی یکتا برای محصول (کلید اصلی) |
| `name` | `varchar(100)` | نام محصول |
| `category` | `varchar(100)` | دستهبندی محصول |
| `price` | `integer` | قیمت محصول |
### جدول `product_company` (شرکت-محصول)
این جدول یک رابطهی چند به چند بین شرکتها و محصولات ایجاد میکند.
| نام ستون | نوع داده | توضیحات |
|--------------|-----------|----------------------------------------------|
| `id` | `integer` | شناسهی یکتا برای رابطه (کلید اصلی) |
| `company_id` | `bigint` | شناسهی شرکت (کلید خارجی به جدول `company`) |
| `product_id` | `bigint` | شناسهی محصول (کلید خارجی به جدول `product`) |
### جدول `user` (کاربران)
این جدول اطلاعات مربوط به کاربران را ذخیره میکند.
| نام ستون | نوع داده | توضیحات |
|--------------|-----------|---------------------------------------------------|
| `id` | `integer` | شناسهی یکتا برای کاربر (کلید اصلی) |
| `first_name` | `text` | نام کاربر |
| `last_name` | `text` | نام خانوادگی کاربر |
| `email` | `text` | ایمیل کاربر |
| `address_id` | `integer` | شناسهی آدرس مرتبط (کلید خارجی به جدول `address`) |
| `company_id` | `integer` | شناسهی شرکت مرتبط (کلید خارجی به جدول `company`) |
| `username` | `text` | نام کاربری |
این جداول دارای روابطی هستند که به کمک کلیدهای خارجی بین جداول ایجاد شدهاند. برای مثال، هر شرکت میتواند یک آدرس داشته باشد و هر کاربر نیز میتواند یک شرکت و یک آدرس داشته باشد.
</details>
# مطلوبات
کوئریهایی بنویسید که خروجیهای مطلوب زیر را بهدست آورد (توجه کنید که هر کوئری نمرهای جداگانه دارد و اگر کوئری قسمتی را نتوانستید بنویسید، کوئریهایی که حل کردید را بفرستید و کوئری آن قسمت را خالی بگذارید):
1. آیدی، نام کوچک، فامیلی و نام کاربری تمام کاربرانی که نام کوچک (`first_name`) آنها با حرف **s** و فامیلی (`last_name`) آنها با حرف **e** تمام میشود. کوچک یا بزرگ بودن حروف مهم نیست و رکوردها باید براساس آیدی به صورت صعودی مرتب شوند.
<details class="blue">
<summary>
*نمونه خروجی کوئری اول*
</summary>
ساختار نتیجهی کوئری و سطر اول آن، به شکل زیر است:
| id | first_name | last_name | username |
|:-----|:-----------|:----------|:----------|
| 6916 | Sarah | George | patrick32 |
</details>
2. نام شرکت و مجموعهای از محصولاتی که متعلق به آن شرکت هستند. رکوردها براساس تعداد محصولات شرکت به صورت نزولی مرتب میشوند، در صورت برابر بودن تعداد محصولات دو شرکت، ترتیب صعودی آیدی آنها اولویت دارد.
<details class="blue">
<summary>
*نمونه خروجی کوئری دوم*
</summary>
## نمونه خروجی کوئری دوم
ساختار نتیجهی کوئری و سطر اول آن، به شکل زیر است:
| company_name | product_list |
|:-------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Movies | {Hair Care Component,Fitness Equipment,Home Improvement Rig,Truck Item,Furniture Whatchamacallit,Music Widget,Party Gear,Mens Device,Aquarium Instrument,Movie Paraphernalia,Camera Attachment,Skin Care Implement,Makeup Gadget,Party Gadget,Personal Implement,Swimming Rig,Gardening Mechanism,Nutrition Component,Book Machine,Party Mechanism} |
</details>
3. در این کوئری باید آدرس شرکتی که کاربر در آن حضور دارد و نام کاربری او را برگردانید. در صورتی که کاربر در شرکتی حضور نداشت یا شرکتی که کاربر در آن حضور دارد، آدرسی نداشت، آدرسی را که در جدول کاربران برای کاربر مشخص شده است، برگردانید. خروجی باید به ترتیب صعودی آیدی کاربران مرتب شده باشد. ترتیب قرار گیری آدرس در ستون `user_address` به صورت روبرو است: ```Country, City, Zip Code```
<details class="blue">
<summary>
*نمونه خروجی کوئری سوم*
</summary>
ساختار نتیجهی کوئری و سه سطر اول خروجی به شکل زیر است:
| username | user_address |
|:------------|:-------------------------------|
| markbaker | Moenstead, Palestine, 4972 |
| garciaamy | Murphyton, French Guiana, 5765 |
| jonesandrea | Bauchland, Panama, 8125 |
</details>
4. در این کوئری از شما میخواهیم با جستوجو در جدول محصولات، یک جدول با فیلدهای زیر را برگردانید:
+ نام، قیمت و کتگوری محصول
+ نام و شهرِ شرکت محصول
+ در انتها یک فیلد که در آن اگر قیمت محصول از میانگین قیمت کل محصولات بیشتر بود، `expensive` و اگر قیمت آن از میانگین کل محصولات کمتر بود `not expensive` قرار میگیرد.
+ خروجی باید براساس آیدی محصول مرتب شده باشد.
<details class="blue">
<summary>
*نمونه خروجی کوئری چهارم*
</summary>
سه سطر ابتدایی خروجی به شکل زیر خواهد بود:
| product\_name | product\_price | product\_category | company\_name | company\_city | price\_comparison |
|:-------------------|:---------------|:------------------|:--------------|:--------------|:------------------|
| Bedding Attachment | 14 | Home | Shoes | Corkeryland | not expensive |
| Dining Contraption | 112 | Home | Grocery | Hartford | expensive |
| Truck Kit | 27 | Automotive | Tools | North Burley | not expensive |
</details>
# فایل نهایی
پس از پیادهسازی کوئریها، آن را در فایل `queries.sql`، وارد کرده و سپس این فایل را آپلود کنید. کد شما باید به صورت زیر
باشد:
```sql
-- Section1
Your first query here
-- Section2
Your second query here
-- Section3
Your third query here
-- Section4
Your fourth query here
```
اطلاعات کاربران
**برای این سوال، نسخهی جاوای شما باید ۱۷ باشد.**
----------

شما به قبل سال `2000` برگشتهاید، زمانی که فناوری دیتابیسها به تازگی در حال ظهور است و مهندسان در تلاشند تا راهحلهای نوآورانهای برای جستجوی اطلاعات پیدا کنند. بسیاری از آنها از ایدههای جدید شگفتزده شده و دنیای فناوری اطلاعات در آستانهی تغییرات شگرفی است.
شما که از آینده خبر دارید، تصمیم گرفتهاید سیستم ابتدایی `Full-Text Search` را پیادهسازی کنید. با این اختراع، شما نه تنها دنیای جستجو را متحول میکنید بلکه تاریخ را نیز تحت تأثیر قرار خواهید داد و این اختراع را به نام خود ثبت خواهید کرد.
# جزئیات پروژه
پروژهی اولیه را از [این لینک](/contest/assignments/73613/download_problem_initial_project/253333/) دانلود کنید. ساختار فایلهای پروژه بهصورت زیر است:
```java
index
├── Document.java
├── Index.java
└── Query.java
```
شما باید سه کلاس `Document`، `Index` و `Query` را مطابق با مواردی که در ادامه مطرح میشود، کامل کنید.
## کلاس `Document`
اولین کلاسی که باید تکمیل کنید کلاس `Document` است. این کلاس بدنه اصلی داکیومنتهای شما را برای اندیس مشخص میکند و باید شامل ویژگیهای(property) زیر باشد:
| نام | نوع |
|:----------:|:------------------:|
| id | `long` |
| text | `String` |
| date | `LocalDate` |
## کلاس `Query`
این کلاس شامل ویژگیهای کوئری است که قصد دارید طبق این ویژگیها داکیومنتهایی را از درون اندیس بازیابی کنید. این کلاس شامل ویژگیهای زیر میشود:
| نام | نوع |
|:----------:|:------------------:|
| text | `String` |
| date | `LocalDate` |
| endDate | `LocalDate` |
## کلاس `Index`
این کلاس اصلیترین کلاسی است که باید پیادهسازی کنید. این کلاس شامل داکیومنتها و اندیسها(Index) میشود. اندیسهای این کلاس در واقع [اندیسهای معکوس](https://en.wikipedia.org/wiki/Inverted_index) (Inverted index) به هر داکیومنت هستند.
```java Index.java java
public class Index {
private List<Document> documents = new ArrayList<>();
private Map<String, Set<Long>> textIndex = new HashMap<>();
private Map<LocalDate, Set<Long>> dateIndex = new TreeMap<>();
public Index(String filePath) throws Exception {
}
public void indexDocument(Document document) {
}
public void saveIndexToFile(String filePath) throws IOException {
}
public List<Document> search(Query query) {
}
}
```
همانطور که میبینید، دو اندیس `textIndex` و `dateIndex` وجود دارند که نحوه ساخت این اندیسها در ادامه آورده شده است. مطابق این فایل، شما در این کلاس باید یک کانستراکتور و سه متد که در ادامه جزئیات آنها ذکر میشود را پیادهسازی نمایید:
کانستراکتور `Index`: این کانستراکتور فایلی که در مسیر ورودی دریافت کرده را به صورت `ObjectInputStream` خوانده و اندیسهای گفته شده را باید به درستی مقداردهی کند.
متد `saveIndexToFile`: این متد یه مسیر را دریافت و کل کلاس `Index` را با تمام مقادیرش به صورت `ObjectOutputStream` در این مسیر قرار میدهد.
متد `indexDocument`: این متد یک داکیومنت را دریافت میکند و اندیسهای گفته شده را به صورت زیر ایجاد میکند:
+ برای ساخت `textIndex` باید ویژگی `text` هر داکیومنت براساس کاراکترهای غیر کلمهای (حرف، رقم یا `_`) شکسته شود و داکیومنتها اندیس شوند.
+ برای ساخت `dateIndex` هر داکیومنت براساس ویژگی `date` خودش اندیس میشود.
متد `search`: این متد وظیفه دارد تا داکیومنتهایی را براساس کوئری ورودی برگرداند. هر کدام از ویژگیهای کلاس `Query` میتواند نال باشند ولی در صورتی که هر کدام از مقادیر نال نبود باید داکیومنتهایی براساس اولویت زیر برگردانده شوند:
1. متن
2. بازه زمانی (این به این معنی است که اگر در کوئری بازه زمانی وارد شده بود، این بازه اولویت بیشتری دارد)
3. زمان دقیق
# مثال
مثالهایی به صورت تست نمونه در اختیار شما قرار داده شده است که میتوانید از آنها کمک بگیرید. به عنوان مثال به مورد زیر دقت کنید:
```java
Index index = new Index();
index.indexDocument(new Document(1, "Quera online coding contests", LocalDate.now()));
index.indexDocument(new Document(2, "Quera for programmers", LocalDate.now().minusDays(4)));
index.indexDocument(new Document(3, "Practice coding skills", LocalDate.now().minusMonths(11)));
Query query = new Query("Quera", null, null);
List<Document> result = index.search(query);
```
خروجی مثال بالا باید داکیومنتها با آیدی `1`و `2` را برگرداند.
# نکات
+ دو کلاس `Document` و `Query` باید شامل کانستراکتوری با همه ویژگیها باشند.
+ همه ویژگیهای دو کلاس `Document` و `Query` باید دارای `getter` متد با نام پیشفرض در جاوا باشند.
+ **تضمین میشود** داکیومنت با آیدی تکراری وارد نخواهد شد.
+ **دقت کنید** که ساختار ابتدایی کلاسها را تغییر ندهید.
+ **دقت کنید** که کلاسهای شما در صورت لزوم باید قابلیت سریالایز و دسریالایز شدن داشته باشند.
# آنچه باید آپلود کنید
پس از پیادهسازی موارد خواستهشده، فقط این سه کلاس را زیپ کرده و آپلود کنید.
```java
[your-solution-file].zip
├── Document.java
├── Index.java
└── Query.java
```
سفر در زمان (جاوا)
**برای این سوال، نسخهی جاوای شما باید ۱۷ باشد.**
----------
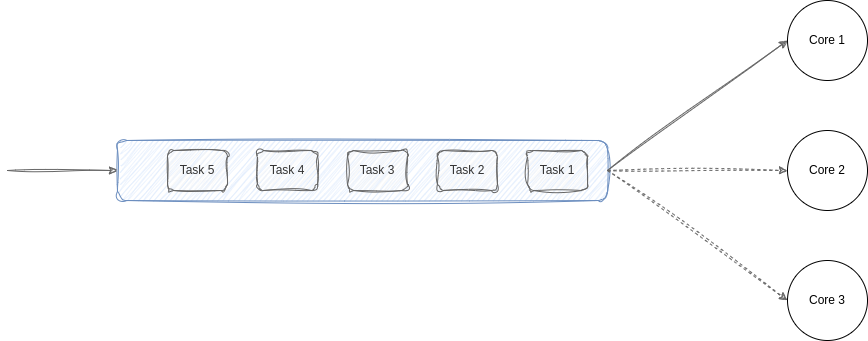
شما به زودی قصد دارید که با یکی از بزرگترین شرکتها در حوزه ساخت تراشه و پردازندههای کامپیوتری همکاری کنید. آنها برای ارزیابی شما تسکی را میدهند. اگر در این تسک موفق شوید، در این شرکت استخدام خواهید شد. آنها از شما میخواهند تا سیستم ابتدایی پردازندههای آنها را طراحی کنید. جزئیات این تسک در ادامه آمده است.
# جزئیات پروژه
پروژهی اولیه را از [این لینک](/contest/assignments/73613/download_problem_initial_project/253332/) دانلود کنید. ساختار فایلهای پروژه بهصورت زیر است:
```java
index
├── Core.java
├── Processor.java
├── SelectStrategy.java
├── Task.java
└── Type.java
```
همانطور که در ساختار فایلهای اولیه مشاهده میکنید، شما با چندین کلاس مرتبط با پردازنده سر و کار دارید. کلاس `Task` دقیقا تسکهایی است که به پردازنده شما وارد میشود و شما باید آنها را مدیریت کنید. هر تسک نوعی دارد که توسط `enum` با نام `Type` مشخص میشود. از سوی دیگر، کلاس `Core`، هر هسته از پردازنده شما را مشخص میکند که میتواند فقط انواع خاصی از تسکها را هندل کند که با ویژگی(property) `types` مشخص میشود. مقدار لود یا همان تعداد تسکی که هر هسته در حال پردازش دارد نیز با `currentLoad` مشخص میشود.
در این ساختار، رابط (Interface) `SelectStrategy` نیز به چشم میخورد که استراتژیهای مختلف انتخاب هسته پردازنده برای انجام تسک را مشخص میکند.
شما باید کلاس `Processor` را به همراه سه کلاس دیگر، مطابق با جزئیاتی که در ادامه ذکر میشود، کامل و ارسال کنید.
## کلاس `Processor`
اولین کلاسی که باید تکمیل کنید کلاس `Processor` است. این کلاس اطلاعات هستهها را نگه میدارد و وظیفه مدیریت تسکها را برعهده دارد. در اولین گام شما باید سه ویژگی زیر را ایجاد کنید:
| نام | نوع |
|:----------:|:------------------:|
| cores | `List<Core>` |
| tasks | `Queue<Task>` |
| selectStrategy | `SelectStrategy` |
همه ویژگیهای این کلاس باید دارای متدهای `getter` و `setter` با نام پیشفرض در جاوا باشد. علاوه بر این متدها، شما باید متدهای زیر را نیز در این کلاس ایجاد کنید:
متد `addCore`: این متد، هسته ورودی را به لیست هستههای این پردازنده اضافه میکند.
متد `addTask`: این متد، تسک ورودی را به صف تسکها اضافه میکند.
**توجه کنید** که در این کلاس، به محض اضافه شدن تسک به صف تسکها، فرایند انتخاب یک هسته آغاز و تسک برای انجام به یک هسته داده میشود.
## فرایند انتخاب یک هسته از پردازنده
همانطور که گفته شد، کلاس `Processor` دارای ویژگی با نام `selectStrategy` است که نگهدارنده استراتژی انتخاب یک هسته است. شما باید سه استراتژی را که در ادامه ذکر میشود را پیادهسازی کنید:
استراتژی `RandomStrategy`: این استراتژی، یک هسته را به صورت رندوم انتخاب و برمیگرداند.
استراتژی `LeastLoadStrategy`: در این استراتژی، هستهای که کمترین لود را دارد انتخاب و برگردانده میشود.
استراتژی `RoundRobinStrategy`: این استراتژی، با استفاده از الگوریتم **روند رابین (Round Robin)** یک هسته را انتخاب و برمیگرداند. در این استراتژی تسکها برای اجرا، به صورت چرخشی به هستههای پردازنده داده میشود.
**دقت کنید** که هر هسته فقط میتواند انواع خاصی از تسکها را پردازش کند.
# مثال
مثالهایی به صورت تست نمونه در اختیار شما قرار داده شده است که میتوانید از آنها کمک بگیرید. به عنوان مثال به مورد زیر دقت کنید:
```java
Processor processor = new Processor();
processor.addCore(new Core(1, List.of(Type.IO, Type.NETWORK)));
processor.addCore(new Core(2, List.of(Type.IO)));
processor.addCore(new Core(3, List.of(Type.STORAGE)));
processor.setSelectStrategy(new LeastLoadStrategy());
processor.addTask(new Task(1, Type.IO));
```
در این نمونه تسک با آیدی `1` به اولین هسته یعنی هسته با آیدی `1`داده میشود.
# نکات
+ شما فقط مجاز به اعمال تغییرات در کلاسهای `Core` و `Processor` به همراه سه کلاسی که باید ایجاد کنید، هستید.
+ حتما باید برای پیادهسازی استراتژیهای انتخاب از اینترفیس `SelectStrategy` استفاده کنید.
+ **دقت کنید** که ساختار ابتدایی کلاسها را تغییر ندهید.
# آنچه باید آپلود کنید
پس از پیادهسازی موارد خواستهشده، فقط فایل همه این کلاسها را زیپ کرده و آپلود کنید.