| فایل اولیهی سوال را میتوانید از [این لینک](/contest/assignments/84378/download_problem_initial_project/306361/) دانلود کنید.|
| :--: |
در سرزمین همیشه در صحنه برره، اطلاعات کارمندان دولتی در یک دیتابیس قدیمی و پر از هرجومرج نگهداری میشود. سازمان مرموز «تَساب - تحلیل سایبری اهالی برره» ادعا میکند که میتواند با تحلیلهای پیشرفته، نبض قدرت و سیاستهای پشت پرده این سرزمین را در دست بگیرد.
آنها بهترین هکر خود، **طاها**، را برای این ماموریت استخدام میکنند. طاها با موفقیت به دیتابیس نفوذ کرده و یک کپی کامل از آن را به دست آورده است. اما حالا با یک مشکل بزرگ روبروست: مدیران «تَساب» از او گزارشهای تحلیلی و آماری پیچیدهای میخواهند که فراتر از تخصص اوست.
|  |
| :---: |
| جلسه سرّی تساب|
طاها که نمیخواهد این ماموریت پردرآمد را از دست بدهد، به صورت مخفیانه با شما، یک متخصص تحلیل داده، تماس میگیرد. او دادههای خام را در اختیار شما قرار داده و از شما خواسته تا پاسخ سه سوال کلیدی را برایش پیدا کنید. موفقیت او کاملاً به تحلیلهای دقیق شما بستگی دارد.
## نحوهی ارسال پاسخ
برای پاسخ به این سوال ابتدا فایل نوتبوک قرار گرفته در فایل اولیه را باز کنید و سپس مراحل را مطابق آنچه که از شما خواسته شده انجام دهید. در نهایت، پس از اجرای سلول جوابساز (آخرین سلول فایل نوتبوک) فایل `result.zip` ساخته شده را ارسال نمایید.
<details class="red">
<summary>
**هشدار مهم**
</summary>
توجه داشته باشید که پیش از اجرای سلول جوابساز، تغییرات اعمال شده در نوتبوک را با استفاده از کلید میانبر `ctrl+s` ذخیره کرده باشید در غیر این صورت، در پایان مسابقه **نمره** شما به **صفر** تغییر خواهد کرد.
همچنین اگر از کولب برای اجرای این فایل نوتبوک استفاده میکنید، قبل از ارسال فایل `result.zip`، آخرین نسخهی نوتبوک خود را دانلود کرده و داخل فایل ارسالی قرار دهید.
</details>
فایلهای تَساب
| فایل اولیهی پروژه را میتوانید از [این لینک](/contest/assignments/84378/download_problem_initial_project/306363/) دانلود کنید.|
| :--: |
در این سوال با **دادههای صنعتی** سروکار داریم. قطعات صنعتی به مرور زمان فرسوده میشوند و کارایی خود را از دست میدهند. خرابی این قطعات میتواند کل فرآیند تولید را تحت تأثیر قرار دهد. یکی از پارامترهای مهم در بررسی وضعیت قطعات، **دمای محیط اطراف آنها** است. دما میتواند اطلاعات زیادی درباره سلامت قطعه، فشارهای وارده یا شرایط کاری آن ارائه دهد.
وظیفه شما در این بخش از مسابقه، **پیشبینی دمای قطعات صنعتی** با استفاده از دیگر ویژگیهای آنهاست، تا بتوانید روند عملکرد و وضعیت قطعات را بهتر تحلیل و مدیریت کنید.

-----------------------
## معیار ارزیابی
برای ارزیابی مدل شما از معیار `R2 Score` استفاده میشود. برای نمرهگیری در این سوال مدل شما باید دارای `R2 Score` حداقل ۰.۶ باشد و در این حالت نمرهی نهایی بر اساس فرمول زیر محاسبه میگردد:
$$round(r2score, 3) \times 100$$
اگر مدل شما به حدنصاب نرسد، نمرهی دریافتی **صفر** خواهد بود.
<details class="red">
<summary>
**توجه**
</summary>
در طول مسابقه امتیازی که مشاهده میکنید، فقط نتیجهی ارزیابی مدل شما روی ۳۰ درصد از دادههای آزمون است. بعد از پایان زمان مسابقه، **امتیاز نهایی** شما روی ۷۰ درصد مابقی محاسبه میشود.
این کار به منظور جلوگیری از بیشبرازش (`overfitting`) و حفظ عمومیت مدل انجام میشود تا مطمئن شویم مدلهایی که دچار بیشبرازش شدهاند، در امتیازدهی نهایی، افت میکنند
</details>
---------------------------------
## نحوهی ارسال پاسخ
پاسخ نهایی شما باید در قالب فایلی با نام **submission.csv** ارائه شود. این فایل باید شامل یک ستون با نام **Air temperature [K]** باشد. در این ستون، برای هر نمونه از دادههای آزمون مشخص میکنید که دمای هوا برای آن نمونه تا چه حد بوده است.
جدول زیر نمونهای از سه سطر اول فایل خروجی مورد انتظار را نشان میدهد:
| **Air temperature [K]** |
|:---------:|
| 300.854 |
| 295.561 |
| 297.285 |
برای پاسخ به این سوال ابتدا فایل نوتبوک قرار گرفته در فایل اولیه را باز کنید و سپس مراحل را مطابق آنچه که از شما خواسته شده انجام دهید. در نهایت، پس از اجرای سلول جوابساز (آخرین سلول فایل نوتبوک) فایل `result.zip` ساخته شده را ارسال نمایید.
<details class="red">
<summary>
**هشدار مهم**
</summary>
توجه داشته باشید که پیش از اجرای سلول جوابساز، تغییرات اعمال شده در نوتبوک را با استفاده از کلید میانبر `ctrl+s` ذخیره کرده باشید در غیر این صورت، در پایان مسابقه **نمره** شما به **صفر** تغییر خواهد کرد.
همچنین اگر از کولب برای اجرای این فایل نوتبوک استفاده میکنید، قبل از ارسال فایل `result.zip`، آخرین نسخهی نوتبوک خود را دانلود کرده و داخل فایل ارسالی قرار دهید.
</details>
حرارتیار
| فایل اولیهی سوال را میتوانید از [این لینک](/contest/assignments/84378/download_problem_initial_project/306364/) دانلود کنید.|
| :--: |
شرکت مخابراتی «**آوا تلکام**»، یکی از بازیگران قدیمی و خوشنام بازار ارتباطات ایران، در چند فصل اخیر با چالش جدیدی روبرو شده است. با ورود یک رقیب تهاجمی به بازار که با پیشنهادهای وسوسهانگیز و کمپینهای تبلیغاتی گسترده، سعی در جذب مشتریان شرکتهای دیگر دارد، **نرخ ریزش مشتریان** در آوا تلکام به شکل نگرانکنندهای افزایش یافته است.
تیم بازاریابی و فروش، استراتژیهای مختلفی مانند ارائه تخفیف و بستههای جدید را امتحان کردهاند، اما به نظر میرسد این راهحلها مقطعی بوده و مشکل اصلی را حل نمیکند. مدیران ارشد شرکت معتقدند که کلید حل این معما، در دادههای ارزشمندی نهفته است که تا به امروز به درستی از آنها استفاده نشده است: **صدای مشتریان**.
آوا تلکام هزاران ساعت مکالمه ضبطشده از تماسهای مشتریان با مرکز پشتیبانی را در اختیار دارد. این تماسها، که اخیراً با استفاده از تکنولوژیهای پیشرفته به متن تبدیل شدهاند، گنجینهای از شکایات، درخواستها، نیازها و احساسات واقعی مشتریان هستند.
**چالش اصلی اینجاست:** آیا میتوانیم قبل از اینکه مشتری تصمیم به رفتن بگیرد، با تحلیل ترکیبی از دادههای کلاسیک مشتری و متن گفتگوهای او با مرکز پشتیبانی، زنگ خطر را بشنویم و جلوی ریزش او را بگیریم؟
شما به عنوان دانشمند داده در تیم هوش تجاری آوا تلکام، مسئولیت این پروژه حیاتی را بر عهده گرفتهاید. موفقیت شما میتواند میلیونها تومان از هزینههای جذب مشتری جدید را صرفهجویی کرده و وفاداری مشتریان فعلی را به شرکت بازگرداند.
شما در نهایت باید سیستمی طراحی کنید که با توجه به ویژگیهای جمعآوری شده از مشتریان، **احتمال ریزش یا خروج مشتری** را پیشبینی کند؟
<details class="yellow">
<summary>**دادگان**</summary>
مجموعه داده مورد استفاده شامل ویژگیهای جمعآوری شده از مشتریان است که عبارتاند از:
| *نام ستون (Column Name)* | *توضیح مختصر* |
|:----------------------------:|:-------------------------------------------------------------------------:|
| *custId* | شناسه منحصر به فرد هر مشتری |
| *sex* | جنسیت مشتری |
| *isElderly* | مشخص میکند که آیا مشتری سالمند است یا خیر |
| *partner* | مشخص میکند که آیا مشتری متاهل است یا خیر |
| *dependents* | مشخص میکند که آیا مشتری افراد تحت تکفل دارد یا خیر |
| *membershipDuration* | مدت زمان عضویت مشتری (معمولاً به ماه) |
| *agreementTerm* | نوع قرارداد مشتری (مثلاً ماهانه، یک ساله، دو ساله) |
| *acquisitionChannel* | کانالی که مشتری از طریق آن جذب شده است (مثلاً آنلاین) |
| *phoneService* | آیا مشتری سرویس تلفن دارد یا خیر |
| *multipleLines* | آیا مشتری بیش از یک خط تلفن دارد یا خیر |
| *internetService* | نوع سرویس اینترنت مشتری (مثلاً DSL یا فیبر نوری) |
| *monthlyDataUsageGb* | میانگین حجم اینترنت مصرفی ماهانه مشتری (به گیگابایت) |
| *cyberProtectionService* | آیا مشتری سرویس محافظت سایبری دارد یا خیر |
| *onlineBackup* | آیا مشتری سرویس پشتیبانگیری آنلاین دارد یا خیر |
| *deviceProtection* | آیا مشتری سرویس محافظت از دستگاه دارد یا خیر |
| *techSupport* | آیا مشتری سرویس پشتیبانی فنی دارد یا خیر |
| *streamingTv* | آیا مشتری سرویس پخش آنلاین تلویزیون دارد یا خیر |
| *streamingMovies* | آیا مشتری سرویس پخش آنلاین فیلم دارد یا خیر |
| *recurringFee* | هزینه ثابت ماهانه مشتری |
| *cumulativeSpend* | مجموع تمام هزینههایی که مشتری پرداخت کرده است |
| *transactionMethod* | روش پرداخت مشتری |
| *paperlessBilling* | آیا مشتری از صورتحساب الکترونیکی استفاده میکند یا خیر |
| *billingIssues* | تعداد مشکلات مربوط به صورتحساب که مشتری داشته است |
| *supportTickets* | تعداد تیکتهای پشتیبانی که مشتری ثبت کرده است |
| *lastContactRating* | امتیازی که مشتری به آخرین تماس خود با پشتیبانی داده است |
| *serviceSatisfactionScore* | امتیاز کلی رضایت مشتری از خدمات |
| *mobileAppSatisfaction* | امتیاز رضایت مشتری از اپلیکیشن موبایل |
| *networkStabilityScore* | امتیاز پایداری شبکه برای مشتری |
| *avgNetworkLatencyMs* | میانگین تاخیر شبکه (پینگ) برای مشتری به میلیثانیه |
| *dataLimitWarnings* | تعداد هشدارهای اتمام حجم اینترنت که مشتری دریافت کرده |
| *loyaltyPoints* | امتیاز وفاداری مشتری |
| *customerFeedback* | بازخورد کیفی ثبت شده توسط مشتری |
| *competitorOffers* | آیا مشتری پیشنهادهایی از شرکتهای رقیب دریافت کرده است |
| *custExit* | متغیر هدف؛ مشخص میکند که آیا مشتری ریزش کرده یا خیر |
</details>
# ارزیابی
برای ارزیابی مُدل شما از سطح زیر ناحیه نمودار ROC استفاده میشود. برای مطالعه بیشتر در مورد این نمودار میتوانید [ویکیپدیا](https://en.wikipedia.org/wiki/Receiver_operating_characteristic) یا [راهنمای کوتاه نکات و ترفندهای یادگیری ماشین](https://stanford.edu/~shervine/l/fa/teaching/cs-229/cheatsheet-machine-learning-tips-and-tricks) را مطالعه کنید.
نتیجه AUC ROC مُدل شما بر روی دادگان آزمایش در عدد ۱۰۰ ضرب شده و به عنوان امتیاز این مرحله در نظر گرفته میشود (بالاترین امتیاز ممکن از این مرحله ۱۰۰ میباشد).
داوری این سوال قبل از پایان مسابقه، تنها بر اساس ۳۰ درصد از دادگان آزمایش (`test`) خواهد بود. پس از اتمام مسابقه، برای بهروزرسانی نهایی جدول امتیازات از ۱۰۰ درصد دادگان آزمایش استفاده خواهد شد؛ این کار برای جلوگیری از بیشبرازش (`overfit`) روی دادگان آزمایش انجام میشود.
# خروجی
شما باید پس از ساخت سیستم خود، فایل `test.csv` را خوانده و به ازای هر آیدی یا کاربر موجود در آن مجموعه داده، **احتمال** ریزش هر کاربر را با توجه به ویژگیهای آن تخمین بزنید. در نهایت شما باید فایل *CSV* با نام `submission.csv` که هر سطر آن تخمین شما برای ریزش مشتری است را ساخته و ارسال کنید.
| *custId* | *custExit* |
|:---------:|:----------:|
| m64861 | 0.22 |
| ... | ... |
| zk62733 | 0.53 |
نجات مشتریان در «آوا تلکام»
| فایل اولیهی پروژه را میتوانید از [این لینک](/contest/assignments/84378/download_problem_initial_project/306356/) دانلود کنید.|
| :--: |
در این بخش از مسابقه، هدف ما **دستهبندی لوازم مصرفی خودرو** بر اساس تصاویر آنها است. این لوازم میتواند شامل مواردی مانند **روغن موتور**، **فیلتر هوا**، **لنت ترمز** و سایر قطعات و اقلام مشابه باشد.
شما باید یک **مدل هوش مصنوعی** طراحی و آموزش دهید که قادر باشد با دریافت تصویر هر قطعه، آن را در دستهبندی صحیح قرار دهد. برای این منظور، مجموعهای از تصاویر نمونه از هر دسته در اختیار شما قرار داده خواهد شد تا مدل خود را بر اساس آنها آموزش دهید.

----------------------------
## مجموعهداده
این مجموعهداده شامل تصاویر شش گروه از لوازم مصرفی خودرو است که عبارتاند از:
+ فیلتر هوا (air_filter)
+ لنت ترمز (brake_pad)
+ ضد یخ (coolant)
+ فیلتر روغن (oil_filter)
+ روغن موتور (oil_motor)
+ مایع شیشهشور (windshield_washer)
در مجموع، این پایگاه داده شامل **۱۳۲۵ تصویر** با ابعاد **۶۴۰×۶۴۰ پیکسل** است. از این تعداد:
+ **۹۶۹ تصویر** در بخش آموزش قرار دارند.
+ **۳۵۶ تصویر** در بخش آزمایش استفاده میشوند.
--------------------------------
## معیار ارزیابی
برای ارزیابی مدل شما از معیار `F1 Score` استفاده میشود. برای نمرهگیری در این سوال مدل شما باید دارای `F1 Score` حداقل ۰.۷ باشد و در این حالت نمرهی نهایی بر اساس فرمول زیر محاسبه میگردد:
$$round(f1 score, 3) \times 100$$
اگر مدل شما به حدنصاب نرسد، نمرهی دریافتی **صفر** خواهد بود.
<details class="red">
<summary>
**توجه**
</summary>
در طول مسابقه امتیازی که مشاهده میکنید، فقط نتیجهی ارزیابی مدل شما روی ۳۰ درصد از دادههای آزمون است. بعد از پایان زمان مسابقه، **امتیاز نهایی** شما روی ۷۰ درصد مابقی محاسبه میشود.
این کار به منظور جلوگیری از بیشبرازش (`overfitting`) و حفظ عمومیت مدل انجام میشود تا مطمئن شویم مدلهایی که دچار بیشبرازش شدهاند، در امتیازدهی نهایی، افت میکنند.
</details>
------------
## نحوهی ارسال پاسخ
وظیفه شما این است که یک **مدل مبتنی بر یادگیری عمیق** طراحی و آموزش دهید که بتواند تشخیص دهد هر تصویر متعلق به کدام دسته است.
توجه داشته باشید که **استفاده از هیچ مدل از پیشآموزشدیدهای مجاز نیست**. در صورتی که در نوتبوک شما استفاده از یک مدل از پیشآموزشدیده مشاهده شود، این عمل **به عنوان تخلف** تلقی خواهد شد.
تصاویر در دو پوشه **train** و **test** قرار دارند. در پوشه آموزش یک فایل به نام **train.csv** قرار دارد که در این فایل برچسب هر تصویر مشخص شده است. در پوشه آزمایش نیز یک فایل به نام **test.csv** وجود دارد اما برچسبهای نمونههای تست مشخص نیستند و شما وظیفه دارید آنها را پیشبینی کنید.
وظیفه شما این است که با استفاده از دادههای آموزش، مدلی بسازید که بتواند دسته هر تصویر که در مجموعه آزمایش قرار دارد را پیشبینی کند. خروجی نهایی شما باید یک فایل با نام **submission.csv** باشد. این فایل باید قالبی داشته باشد که **ترتیب سطرهای فایل خروجی باید دقیقاً مطابق با ترتیب نام تصاویر در فایل test.csv** باشد. نمونهای از فایل خروجی نهایی به شرح زیر است:
|filename|air_filter|brake_pad|coolant|oil_filter|oil_motor|windshield_washer|
|------|---|------|---|------|---|---|
|123.jpg | 0|0|1|0|0|0|
|124.jpg|0|0|0|0|0|1|
برای پاسخ به این سوال ابتدا فایل نوتبوک قرار گرفته در فایل اولیه را باز کنید و سپس مراحل را مطابق آنچه که از شما خواسته شده انجام دهید. در نهایت، پس از اجرای سلول جوابساز (آخرین سلول فایل نوتبوک) فایل `result.zip` ساخته شده را ارسال نمایید.
<details class="red">
<summary>
**هشدار مهم**
</summary>
توجه داشته باشید که پیش از اجرای سلول جوابساز، تغییرات اعمال شده در نوتبوک را با استفاده از کلید میانبر `ctrl+s` ذخیره کرده باشید در غیر این صورت، در پایان مسابقه **نمره** شما به **صفر** تغییر خواهد کرد.
همچنین اگر از کولب برای اجرای این فایل نوتبوک استفاده میکنید، قبل از ارسال فایل `result.zip`، آخرین نسخهی نوتبوک خود را دانلود کرده و داخل فایل ارسالی قرار دهید.
</details>
ماشین بازی
| فایل اولیهی پروژه را میتوانید از [این لینک](/contest/assignments/84378/download_problem_initial_project/306357/) دانلود کنید.|
| :--: |
در این بخش از مسابقه، قرار است مجموعهای از کارتپستالهای زیبا از نقاط مختلف ایران بسازیم. ما تصاویری از مکانهای دیدنی شهرهایی مانند تهران، اصفهان، کاشان و... گردآوری کردهایم. حالا نوبت شماست که روی هر تصویر، نام شهر مربوطه را درج کنید.
البته این کار به سادگی که به نظر میرسد نیست! وظیفه شما این است که نام هر شهر را به شکل **watermark** روی تصویر مربوط به یکی از مکانهای آن شهر قرار دهید.
در ادامه، ساختار فایلها و جزئیات پیادهسازی این بخش از مسابقه توضیح داده خواهد شد.

-----------------
## واترماک
**واترمارکینگ (Watermarking)** یک تکنیک برای **جاسازی اطلاعات دیجیتال** (مانند لوگو، متن یا شناسه) در یک تصویر است، به گونهای که این اطلاعات به صورت آشکار یا پنهان بخشی از تصویر شوند.
در این فرآیند معمولاً دو تصویر نقش اصلی دارند:
+ **تصویر پیام (Message)**: محتوای دیجیتالی که باید در تصویر جاسازی شود، مانند یک لوگو یا متن.
+ **تصویر کاور (Cover)**: تصویر اصلی که قرار است پیام در آن مخفی یا درج شود.
در مثال زیر، سه تصویر اصلی در فرآیند واترمارکینگ معرفی میشوند: تصویر پیام، تصویر کاور و تصویر واترمارکشده که حاصل ترکیب پیام با کاور است.

-----------------
## پیکربندی فایلها
در این بخش از مسابقه، سه دسته فایل در اختیار شما قرار دارد. این فایلها در پوشه `Data` قرار دارند که جز فایلهای اولیه این سوال میباشد.
+ **پوشه Cover**: سه تصویر اصلی که در پوشه `Cover` قرار گرفتهاند.
+ **پوشه Message**: سه تصویر حاوی محتوای متنی یا گرافیکی که باید روی کاورها درج شوند. این تصاویر در پوشه `Message` موجود هستند.
+ **پوشه Watermark**: نتیجه ترکیب هر تصویر پیام با تصویر کاور متناظر آن، که در پوشه `Watermark` قرار دارد.
توجه داشته باشید که اندازه هر سه تصویر کاور، پیام و واترمارک باید یکسان باشد. در ساختار فایلهای ارائه شده نیز این موضوع رعایت شده است؛ یعنی هر سه تصویر پیام، کاور و واترمارک متناظر، دقیقاً دارای ابعاد برابر هستند. از تصاویر موجود در پوشه `watermark` استفاده کنید تا بتوانید راهحل خود را ارزیابی کنید. دقت کنید هر چه نتیجه واترمارک شما به تصاویر این پوشه شباهت بیشتری داشته باشد، کیفیت راهحل شما بالاتر خواهد بود.
--------------------
## معیار ارزیابی
برای ارزیابی مدل شما از معیار `SSIM Score` استفاده میشود. برای نمرهگیری در این سوال مدل شما باید دارای `SSIM` حداقل ۰.۸ باشد و در این حالت نمرهی نهایی بر اساس فرمول زیر محاسبه میگردد:
$$round(SSIM, 3) \times 100$$
اگر مدل شما به حدنصاب نرسد، نمرهی دریافتی **صفر** خواهد بود.
<details class="yellow">
<summary>
**شاخص SSIM**
</summary>
**شاخص شباهت ساختاری (Structural Similarity Index Measure یا SSIM)** یک معیار پیشرفته برای مقایسه شباهت بین دو تصویر است. **SSIM** ساختار کلی تصویر را هم در نظر میگیرد و تلاش میکند شباهت را به گونهای اندازهگیری کند که با درک بینایی انسان همخوانتر باشد.
این مقدار عددی بین $1-0$ است که به شکل زیر تفسیر میشود:
+ مقدار $1$ نشاندهنده **تشابه کامل** است.
+ مقدار نزدیک به $0$ یا کمتر از آن نشاندهنده **تفاوت زیاد** است.
</details>
---------------
## نحوهی ارسال پاسخ
شما باید پاسخ خود را به صورت یک تابع پایتونی ارائه دهید. ابتدا یک فایل پایتونی با نام `watermark.py` ایجاد کنید. سپس در این فایل، تابعی به نام `apply_watermark` پیادهسازی کنید که دو ورودی میگیرد: نام فایل تصویر کاور و نام فایل تصویر پیام.
نمونه اعمال و استفاده از تابع به شرح مثال زیر میباشد:
```python
result_image = apply_watermark(cover_name='cover_Isfahan.jpg', message_name='message_Isfahan.jpg')
```
خروجی این تابع یک تصویر **خاکستری** خواهد بود که نتیجه اعمال واترمارک بین تصویر کاور و پیام است.
در نهایت فایل `watermark.py` را در کوئرا آپلود کنید.
کارت پستال
| فایل اولیهی تمرین را میتوانید از [این لینک](/contest/assignments/84378/download_problem_initial_project/306358/) دانلود کنید. |
| :--: |
در دنیای مدرن فوتبال، هوش مصنوعی به بازوی اصلی مربیان و آنالیزورها تبدیل شده است. از تحلیل تاکتیکی حریف گرفته تا بررسی عملکرد بازیکنان، همهچیز به سمت هوشمند شدن پیش میرود. تصور کنید شما معمار هوش مصنوعی یک باشگاه سطح اول هستید و اولین ماموریت شما، ساختن سیستمی است که بتواند در یک لحظه، توازن عددی دو تیم در زمین را تحلیل کند. آیا تیم شما در یک ضد حمله برتری نفری دارد؟ آیا در دفاع تحت فشار است؟ پاسخ به این سوالات با تحلیل آنی تصاویر بازی ممکن میشود.
در این چالش، شما این سیستم هوشمند را خواهید ساخت!
----------
ماموریت شما ساخت یک مدل هوش مصنوعی است که بتواند با دریافت یک تصویر از مسابقه فوتبال، **تعداد بازیکنان هر یک از دو تیم** حاضر در زمین را به طور خودکار شمارش کند. مدل شما باید بتواند با تحلیل ویژگیهای بصری، بازیکنان را به دو تیم مجزا تفکیک کرده و تعداد دقیق آنها را گزارش دهد.
این چالش برای سنجش توانایی شما در **طراحی یک خط لوله (Pipeline) هوشمند و خودکار** برای حل یک مسئله واقعی طراحی شده است. هدف، صرفاً استفاده از یک مدل آماده نیست، بلکه ترکیب خلاقانه الگوریتمهای پردازش تصویر و یادگیری ماشین برای رسیدن به نتیجه در شرایطی است که دادههای آموزشی لیبلدار وجود ندارد.
<details class="red">
<summary>
**قوانین و نکات**
</summary>
به شما یک مجموعه شامل تقریباً ۱۰۰۰ تصویر از مسابقات فوتبال، **بدون هیچگونه لیبل**، ارائه میشود. تمام پردازشها و نتایج باید صرفاً بر اساس همین مجموعه تصاویر (و منابع مجازی که در ادامه ذکر میشود) استخراج گردد.
1. **استفاده از منابع خارجی:** شما مجاز به استفاده از مدلهای پایهی **عمومی** هستید که بر روی دیتاستهای بزرگ و غیرمرتبط با این مسئله خاص (مانند **COCO** یا **ImageNet**) آموزش دیدهاند.
✅مثل استفاده از وزنهای استاندارد YOLOv8 (`yolov8s.pt`) که برای تشخیص ۸۰ کلاس عمومی دیتاست COCO آموزش دیده است.
**❌ غیرمجاز:** استفاده از مدلهایی که به طور خاص برای مسئله "تشخیص بازیکن فوتبال"، "تفکیک لباس تیم" یا موارد مشابه توسط دیگران آموزش داده شده و در پلتفرمهایی مانند Roboflow Universe، Kaggle، یا GitHub به اشتراک گذاشته شدهاند، **اکیداً ممنوع است.**
❌مثل دانلود مدلی از Roboflow که از قبل میتواند بازیکنان دو تیم آبی و قرمز را تفکیک کند.
> استفاده از هرگونه دیتاست خارجی (شامل تصاویر، لیبلها، و...) برای آموزش، فاینتیون کردن، یا هر هدف دیگری **ممنوع است.** راهحل شما باید فقط با استفاده از دیتاست ارائهشده در مسابقه و مدلهای پایهی عمومی مجاز، کار کند.
2. **محیط اجرا:** کد نهایی شما باید در یک نوتبوک **Google Colab** ارائه شود. این نوتبوک باید با یک بار اجرا (گزینه "Run all")، تمام مراحل از بارگذاری دادهها و مدلها گرفته تا تولید فایل `submission.csv` نهایی را بدون نیاز به دخالت دستی و بدون خطا انجام دهد.
</details>
## خروجی
شما باید یک فایل به نام `submission.csv` تولید کنید که شامل سه ستون است: `image_name`, `count_1`, و `count_2`.
+ `image_name`: نام تصویر مورد نظر از پوشه `test`.
+ `count_1`: تعداد بازیکنان تیمی که در آن تصویر **تعداد بیشتری** دارد.
+ `count_2`: تعداد بازیکنان تیمی که در آن تصویر **تعداد کمتری** دارد.
**نکته مهم:** اگر تعداد بازیکنان دو تیم مساوی بود، تفاوتی ندارد کدام در ستون اول بیاید.
برای مثال در تصویر زیر، ردیف مربوط به فایل خروجی به شکل زیر است:
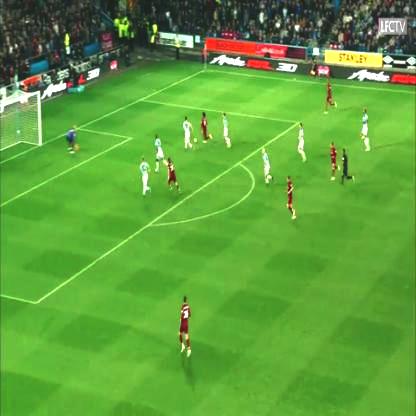
| image_name | count_1| count_2|
| :--- | :--- | :--- |
| jpg | 7 | 6 |
<details class="green">
<summary>
**راهنمایی تصویر**
</summary>
تیم سفید 7 بازیکن و تیم قرمز 6 بازیکن را در تصویر دارد. دقت کنید که دروازهبان و طبیعتا داور به عنوان بازیکنان شمارش **نشدهاند.**
</details>
## معیار ارزیابی (Evaluation Metric)
امتیاز نهایی شما بر اساس یک معیار به نام **«امتیاز مبتنی بر میانگین خطای مطلق»** محاسبه خواهد شد. این معیار نه تنها شمارشهای کاملاً درست را تشخیص میدهد، بلکه به پیشبینیهایی که به مقدار واقعی نزدیک هستند نیز امتیاز مناسبی اختصاص میدهد تا کیفیت واقعی مدل شما سنجیده شود.
فرآیند امتیازدهی در سه مرحله انجام میشود:
۱. **محاسبه خطای مطلق:** برای هر یک از دو تیم (`team1` و `team2`) در هر تصویر، اختلاف بین تعداد پیشبینیشده توسط شما و تعداد واقعی بازیکنان محاسبه میشود. به این اختلاف قدر مطلق، **خطای مطلق** میگوییم.
۲. **محاسبه میانگین خطای مطلق (MAE):** در مرحله بعد، از تمام خطاهای مطلق به دست آمده در کل تصاویر آزمون، میانگین گرفته میشود. عدد نهایی که **Mean Absolute Error (MAE)** نام دارد، نشان میدهد که الگوریتم شما به طور متوسط در هر پیشبینی چقدر خطا داشته است.
۳. **تبدیل خطا به امتیاز نهایی:** در نهایت، عدد *MAE* (که هرچه کمتر باشد بهتر است) با استفاده از یک فرمول نمایی به یک **امتیاز نهایی بین ۰ تا ۱۰۰** تبدیل میشود. این فرمول به خطاهای کوچک جریمه کم و به خطاهای بزرگ جریمه سنگینی اختصاص میدهد.
\[
\text{Score} = 100 \times e^{-\text{MAE}}
\]
| **نکته مهم**: دوباره تاکید میشود برای جلوگیری از تقلب و برای اطمینان از صحت فایل ارسالی، نوتبوک نهایی شما باید پس از اجرا در محیطی استاندارد (مانند *Google Colab* یا *Jupyter*) بتواند فایل `submission.csv` را مجدداً تولید کند. در صورت وجود هرگونه مغایرت بین فایل تولیدی جدید و فایل ارسالی شما، این عمل **تقلب** محسوب شده و نه تنها امتیاز این سؤال را از دست خواهید داد، بلکه نمره منفی برای شما منظور خواهد شد که بر امتیاز کل شما تأثیر خواهد گذاشت. |
| :--: |