سلام به تو ترب توربویی عزیز 🚀🌪️
خوشحالیم که در اولین مرحلهی **TorobTurbo: the LLM Rush** یعنی **مسابقهی انتخابی** همراه ما هستی.
امیدواریم این مسابقه برات سرشار از یادگیری و تجربههای مفید باشه و از حل مسئله لذت ببری!
در این مسابقه قراره با کمک LLMها به حل چالشهای مختلف بپردازیم. این مرحله از مسابقه علاوهبر رقابت، یه فرصت عالی برای یادگیری و تمرینه. پس لازم نیست نگران باشی که حتماً متخصص LLM یا ایجنت ساختن باشی. حتی اگر تازه با این دنیا آشنا شدی، اینجا میتونی با آرامش و قدمبهقدم جلو بری و چیزهای زیادی یاد بگیری.
🔹 بیشتر سؤالات این مرحله طوری طراحی شدن که مستقیم با استفاده از LLMها قابل حل باشن.
🔹 تنها یک سؤال به اسم **«بردار کلمات»** هست که مسیرش کمی متفاوتتره و بدون LLM حل میشه!
🔹 برای هر سؤال، کافیه یک راهحل طراحی کنی و اجازه بدی LLM یا ایجنتت اون رو اجرا کنه.
در طول مسابقه یادت باشه:
+ اگر جایی سوال داشتی یا گیر کردی، بخش «[سؤال بپرسید](https://quera.org/contest/clarification/89594/)» در دسترسه.
+ حتما دکمهی «فعال کردن اطلاعیهها» رو بزن تا هیچ نکتهی مهمی رو از دست ندی!
+ و مهمتر از همه، از مسیر یادگیری لذت ببر :)
# توضیحات فنی
برای حل کردن سوالات نیاز به یک LLM Provider و همچنین توکن شارژ شده دارید. در این قسمت به توضیح نحوهی استفاده و دریافت توکن LLM میپردازیم:
### محیط توسعه
+ برای توسعه روی سیستم خودتان میتوانید از هر ارائهدهندهای که در دسترستان است استفاده کنید (البته با رعایت قوانین مسابقه)
+ همچنین از طریق لینک زیر میتوانید یک توکن یک دلاری برای توسعه و تست از طرف ترب دریافت کنید:
https://quera.org/contest/23408/create-torob-ai-account
+ داوری با استفاده از سامانه بالا صورت میگیرد و بهتر است برای شبیه بودن محیط توسعه و داوری از توکن ترب استفاده کنید.
### محیط داوری
+ توجه کنید که **در کل مسابقه فقط ۱ دلار اعتبار در محیط داوری دارید** و این اعتبار رو باید تا پایان مسابقه مدیریت کنید.
+ پس از هر ارسال، با کلیک بر روی **نمرهی خود** در ستون «وضعیت» از بخش «**همهی ارسالها**» میتونید میزان اعتبار باقیماندهی اختصاص یافته به خود را مطابق تصویر زیر مشاهده کنید.

+ دقت کنید که در کد ارسالی حتما مقدار base_url را برابر با
"https://turbo.torob.com/v1" قرار دهید و حتما از توکن داده شده در ورودی سوال استفاده کنید. استفاده از توکنهای لوکال در جوابهای ارسالی ممنوع میباشد.
#### قوانین استفاده از LLM
+ در این مسابقه حتما باید از مدل `gpt-4.1-mini` استفاده کنید.
+ میتوانید tools جدید بنویسید و از آن استفاده کنید اما استفاده از از tool های آمادهی LLM مانند web_search ،file_search و ... مجاز نیست.
+ حالت stream پیشتیبانی نمیشود.
+ در هر درخواست طول کانتکست ورودی به 20K توکن و حداکثر توکن خروجی به 1K توکن محدود شده است.
### اطلاعات سامانهی داوری
نسخهی پایتون: 3.13
کتابخانههای زیر به صورت پیش فرض روی سامانهی داوری نصب هستن:
openai
httpx
requests
pydantic (core)
### نحوهی ارسال پاسخ
برای پاسخ به سوالات شما باید یک فایل zip با محتوای زیر آپلود کنید:
```
answer.zip
├── python_requirements.txt
└── solution.py
```
فرمت فایل solution.py در هر سوال آمده است و یک نمونه هم در پایین این صفحه خواهید دید. در صورتی که در کد خود از کتابخانهی اضافهای استفاده کردید باید آن را با فرمت زیر در فایل `python_requirements.txt` قرار دهید. دقت کنید که برای کتابخانهها نسخه را نباید مشخص کنید و همیشه آخرین نسخه نصب میشود.
```txt python_requirements.txt
pandas
numpy
```
### نمونهی پاسخ با استفاده از کتابخانهی OpenAI
```python solution.py
class TestQuestion:
def __init__(self, api_key):
self.model = "gpt-4.1-mini"
self.client = OpenAI(api_key=api_key, base_url="https://turbo.torob.com/v1")
def test_request(self):
response = client.chat.completions.create(
model=self.model,
messages=[
{"role": "user", "content": "Hello"},
],
)
print(response.choices[0].message.content)
```
### نمونه پاسخ با استفاده از کتابخانهی pydantic-ai
برای استفاده از pydantic-ai باید خط زیر را در فایل `python_requirements.txt` قرار دهید:
```txt python_requirements.txt
pydantic-ai-slim[openai]
```
سپس به صورت زیر از آن استفاده کنید.
**توجه: هنگام ایجاد `OpenAIProvider` مقدار http_client را حتما به صورت دستی در آن ست کنید وگرنه کد شما در سامانهی داوری به درستی اجرا نمیشود!**
```python solution.py
class TestQuestion:
def __init__(self, api_key):
self.chat_model = OpenAIChatModel(
"gpt-4.1-mini",
provider=OpenAIProvider(
base_url="https://turbo.torob.com/v1",
api_key=api_key,
http_client=httpx.AsyncClient() # Don't forget!
),
)
self.agent = Agent(self.chat_model)
def test_request(self):
response = self.agent.run_sync("Hello")
return response.output
```
------
موفق باشی و امیدواریم تجربهای پر از یادگیری، خلاقیت و هیجان از این مرحله برای خودت بسازی. 💙
توضیحات مسابقه
در این سوال اسم یک محصول و نام فروشگاهی که آن محصول را میفروشد به برنامهی شما داده شده و از شما میخواهیم دستهبندی آن محصول را تشخیص دهید.
دستهبندیهای موجود به صورت زیر هستند:
+ `SMARTPHONE`
+ `LAPTOP`
+ `WATCH`
+ `FLOWER`
+ `CLOTH`
+ `UNKNOWN`
در صورتی که دستهبندی با اطمینان مناسب قابل تشخیص نبود یا نام فروشگاه با نام کالا همخوانی نداشت باید جواب UNKNOWN برگردانده شود.
### مثال اول
ورودی
```
shop_name: موبایل پارسا
product_name: Xiaomi 12
```
خروجی
```
SMARTPHONE
```
### مثال دوم
ورودی
```
shop_name: قالیشویی عباسآقا
product_name: Apple IPhone 13
```
خروجی
```
UNKNOWN
```
### مثال سوم
ورودی
```
shop_name: RoseFlower
product_name: لباس پشمی ریز
```
خروجی
```
UNKNOWN
```
نمونه کد مورد انتظار:
```python solution.py
from openai import OpenAI
class Solution:
def __init__(self, api_key):
self.client = OpenAI(api_key=api_key,base_url="https://turbo.torob.com/v1")
def run(self, text_input: str) -> str:
return "[result]"
```
دستهبندی
> RUN!
**ورودی:**
```
https://turbo.torob.com/escaperoom/start.txt
```
**خروجی مورد انتظار:**
```
23615
```
نمونه کد مورد انتظار:
```python solution.py
from openai import OpenAI
class Solution:
def __init__(self, api_key):
self.client = OpenAI(api_key=api_key,base_url="https://turbo.torob.com/v1")
def run(self, question: str) -> str:
[Your code]
return [the final result]
```
اسکیپ روم
خزشگر(crawler) موتور جستوجوی ترب صفحهی محصولات مختلف را به صورت دورهای crawl کرده و اطلاعات محصول مثل قیمت، نام و ... آن محصول را از صفحهی HTML آن محصول استخراج میکند.
برای اینکه بتوانیم اطلاعات محصول یک فروشگاه را بهدرستی استخراج کنیم، لازم است جایگاه دقیق اطلاعات محصول در صفحهی HTML را داشته باشیم. در ترب، این اطلاعات با کمک هوشمصنوعی استخراج میشود.
برای اینکه موقعیت یک متن در صفحهی HTML را به صورت دقیق نشان دهیم، از زبانی به اسم XPath استفاده میکنیم. XPath یک Query Language است که با اجرای آن بر روی یک صفحهی HTML میتوان متن قسمتی از صفحه را مشخص کرده و برگرداند. برای مثال، تصویر زیر یک صفحهی HTML و یک XPath را نشان می دهد:
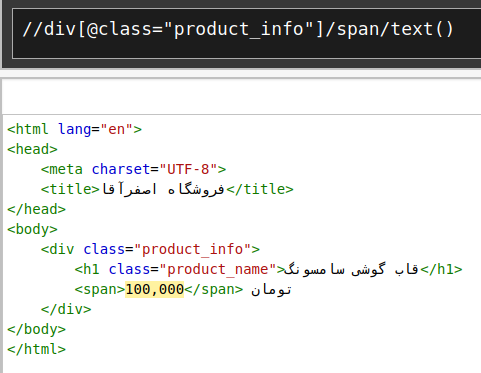
در این سوال شما یک نمونهی ساده شدهی این فرایند را پیادهسازی خواهید کرد. آدرس صفحهی یک محصول موجود و یک محصول ناموجود از فروشگاه به شما دادهشده و از شما میخواهیم که با کمک LLM برای آن فروشگاه XPath های مناسب برای نام، قیمت و موجودی آن را ارائه دهید. در نهایت کد شما باید یک dict با کلیدهای زیر را برگرداند.
#### نتایج مورد انتظار:
- **کلید availability_xpath:** این XPath در صفحهی محصول ِناموجود، با هیچ عنصری در صفحه نباید match شود و در صفحهی محصول ِموجود، حداقل باید یک جواب داشته باشد.
- **کلید name_xpath**: باید در هر دو صفحه دقیقا با یک عنصر match شده و نام محصول را انتخاب کند.
- **کلید final_price_xpath:** فقط در صفحهی محصول موجود، باید دقیقاً با یک عنصر match شود و قیمت نهایی را نشان دهد.
**نکته:** ممکن است چندین جواب صحیح وجود داشته باشد. هر ارسالی که به جواب صحیح برسد قابل قبول است.
نمونه کد مورد انتظار:
```python
from openai import OpenAI
class XPathExtractor:
def __init__(self, api_key):
self.client = OpenAI(api_key=api_key,base_url="https://turbo.torob.com/v1")
def run(self, available_link, unavailable_link):
return {
"name_xpath": "[Your result]",
"final_price_xpath": "[Your result]",
"availability_xpath": "[Your result]"
}
```
# مثال
ورودی:
```
extractor = XPathExtractor(api_key)
extractor.run("https://turbo.torob.com/xpath/sample_1_available.html",
"https://turbo.torob.com/xpath/sample_1_unavailable.html")
```
خروجی:
```
{
"final_price_xpath": "//span[@class='final-price']/text()",
"availability_xpath": "//div/span[@class='availability']",
"name_xpath": "/html/body/div/h1"
}
```
مسیر ایکس
| فایل اولیهی دادگان آموزش و آزمون را میتوانید از [این لینک](/contest/assignments/89594/download_problem_initial_project/304433/) دانلود کنید. |
|:-:|
**توجه: در این سوال نیازی به استفاده از LLM ندارید!**
### توضیحات داده
در این سوال شما قراره نسبت کلمهها به هم دیگه رو پیدا کنید.
به شما سه کلمه به فرمت `A : B :: C : ?` داده میشه و شما باید کلمهی چهارم رو پیدا کنید.
(یعنی نسبت `A` به `B`، مثل نسبت `C` هست به `؟`)
### هدف
- ورودی شما فایل متنی است که در هر سطر سه توکن (کلمه) داره: A B C ? و دستهبندی مربوط به آن هست.
- برای هر سطر باید یک کلمهٔ پاسخ (D) تولید کنید؛ خروجی شما فایلی است که در هر سطر دقیقاً همان یک پاسخ نوشته شده.
- شما باید بر روی سیستم خود از یک مدل لوکال word embedding استفاده کرده و نتیجه را محاسبه کنید. سپس نتیجه و کدی که نتیجه را تولید کرده است را ارسال کنید.
مثلا:
- `boy : king :: girl : ? → queen`
- `Athens : Greece :: Tokyo ? → Japan`
- `Canada : dollar :: Europe ? → euro`
- `dancing : danced :: swim ? → swam`
- `write : writes :: go ? → goes`
فایل **word-analogy-train.txt** را میتوانید برای صحتسنجی کد خود استفاده کنید.
ولی ارزیابی اصلی بر روی خروجی که از فایل **word-analogy-test.csv** ارسال میکنید، انجام میشود.
دقت شود که در این فایلها تعدادی از خطوط کتگوری کلمات را مشخص میکنند. این خطوط با # شروع میشوند.
توکنها را دقیق و بدون تغییر چاپ کنید. (حساسیت به آندرلاین و کوچکی/بزرگی حروف وجود دارد.)
همچنین عبارات چندکلمهای با آندرلاین آماده است؛ مثلاً United_States. حروف را همانطور که در فایل هست، نگه دارید.
دقت کنید که برای حل سوال، استفاده از مدلهای زبانی مجاز نمیباشد و میبایست از مدل لوکال استفاده کنید.
برای ارزیابی، کد شما اجرا میشود و میبایست خروجیای را که به عنوان submission.csv آپلود کردهاید، تولید کند.
**نحوه امتیازدهی**
- معیار اصلی، دقت Top-1 روی کل دادهی تست هست؛ یعنی چند درصد پاسخهای شما دقیقاً درستاند.
# آنچه باید آپلود کنید
**فایل `result.zip`** شامل موارد زیر باشد:
1. **`submission.csv`** — خروجی اصلی برای مقایسهٔ خودکار.
**فرمت دقیق و اجباری:**
| ستون | توضیح |
| ----------- | ----- |
| category| دستهبندی مربوطه|
| word4|کلمهی تولید شده|
دقت شود که نام ستونهای این فایل category و word4 میباشند.
مثال:
```
category,word4
capital-common-countries,Germany
capital-common-countries,England
```
2. شما باید فایل `solution.py` را ارسال کنید که در آن کلاس `WordAnalogy` را پیادهسازی کنید که حاوی تابعی به اسم `run` باشد که یک آرگومان بهعنوان ورودی میگیرد. برای مثال:
```python solution.py
class WordAnalogy:
def run(self, input):
```
ورودی تابع(یعنی input) لیستی تودرتو از سطرهای فایل csv ورودی است. خروجی کد شما نیز میبایست فایل تولید شدهی submission.csv باشد.
3. فایل requirements.txt
اگر از کتابخانهای استفاده کردهاید که نیاز به نصب دارد، نام آنها و ورژن موردنظر را در این فایل بیاورید.(در هر خط، یک کتابخانه)
4. فایل model.txt
در این فایل در صورت نیاز، لینک دانلود مدل خود را قرار دهید.
بردار کلمات
دیتاهای محرمانه یک گروه سایبری فاش شده است. حالا شما باید این داده را بررسی کنید تا میزان بزرگی و شدت حمله آینده این گروه را بفهمید. برای این کار هر بار که یک کلمهی مشکوک (Keyword) مرتبط با عملیات میبینید، آن را بشمارید تا شدت حملهای را که قرار است رخ دهد، محاسبه کنید.
برای این کار نیاز است ایجنتی بنویسید که یک متن و قوانین متن را دریافت کند و با بررسی متن و بر اساس قوانین متن، به جواب دست پیدا کند و عدد شدت تهدید محاسبهشده را خروجی بدهد.
محاسبه به این ترتیب است که در متن داده شده، هر کلمه یک وزن خاص دارد و تکرار بیشتر یا وجود کلمات سنگینتر، نشانه خطر بالاتر است. باید مجموع این خطر را بهعنوان عدد نهایی گزارش بدهید.
فرمول محاسبه امتیاز تهدید (Threat Score) اینگونه است:
```
Threat Score = مجموعِ (تعداد مشاهده هر کلمه × وزن آن)
```
# آنچه باید آپلود کنید
شما باید فایل `solution.py` را ارسال کنید و در آن کلاس `ThreatScore` را پیادهسازی کنید که حاوی تابعی به اسم `run` باشد که یک آرگومان بهعنوان ورودی میگیرد. همچنین میتوانید در کنار برنامهتان ماژولهای مورد نیاز برای اجرا را در `python_requirements.txt` قرار دهید. برای مثال:
```python solution.py
class ThreatScore:
def __init__(self, api_token):
self.api_token = api_token
def run(self, text, rules):
return "Your Answer"
```
**توجه**
ورودیهای text و rules هر دو متنی میباشند و به تابع run داده میشوند. انتظار میرود خروجی کد شما یک عدد (int) باشد.
در ادامه میتوانید یک تستکیس حلشده را مشاهده کنید.
## نمونه
``` python
text = "در طول هفته گذشته، اسکنهای بیوقفه در شبکه ثبت شد و پاسخهای سریعی در پی آن بود. کنترل کامل توسط مهاجم برقرار گشت، تماسهای مشکوک برقرار شد و کاشت ایمپلنت موفقیتآمیز اعلام شد. گروهی از زامبیها فعال شدند و اولین تریگر خطر فعال گردید. آلودگی در سیستم تأیید شد و شواهدی از سازش و تزریق کد به منظور اجرای فوری وجود داشت. فرآیند استقرار بدافزار و همچنین سوءاستفادههایی که منجر به بارگذاری یک پیلود شد، مشاهده شد. یک در پشتی به شکل ماهرانهای در سیستم قرار گرفت و نشانههایی از روز صفر و اضافه شدن به باتنت دیده شد."
rules = "اسکن: ۱، پاسخ: ۲، کنترل: ۳، تماس مشکوک: ۴، ایمپلنت: ۵، زامبی: ۶، تریگر: ۷، آلودگی: ۸، سازش: ۹، تزریق: ۱۰، اجرا: ۱۱، استقرار: ۱۲، بدافزار: ۱۳، سوءاستفاده: ۱۴، پیلود: ۱۵، در پشتی: ۱۶، روز صفر: ۱۷، باتنت: ۱۸"
ts = ThreatScore(your_api_key)
print(ts.run(text, rules)) # 171
```
در مثال ورودی بالا امتیاز تهدید اینطور محاسبه میشود:
```
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18
```
یعنی جواب نهاییای که کد بازمیگرداند میشود:
```
171
```
تذکر: ممکن است کلمات بهصورت جمع هم باشند(مثلا تماسهای مشکوک نیز چون تماس مشکوک کلمهی کلیدی است، یکبار محسوب میشود.
شدت حمله
کارآگاه احمد، یکی از بهترین ذهنهای حل معما، با یک چالش جدید روبرو شده است. یک اوراکل (Oracle) دیجیتال و مرموز، کلمهای را در اعماق کدهای خود پنهان کرده است. این اوراکل به سؤالات شما پاسخ میدهد، بدون اینکه آن را مستقیماً فاش کند.
احمد تنها ۸ فرصت برای پرسیدن سؤال دارد تا هویت این کلمهی اسرارآمیز را کشف کند. او برای این مأموریت به کمک شما نیاز دارد. شما باید مغز متفکر عملیات باشید و یک ایجنت هوشمند طراحی کنید که بتواند بهجای احمد سؤال بپرسد، پاسخها را تحلیل کند و در نهایت، کلمه را حدس بزند. آیا میتوانید به احمد کمک کنید تا این معما را حل کند؟
## شرح مأموریت
مأموریت شما ساخت یک ایجنت هوشمند است که با استفاده از یک API، کلمهی مخفی را در بازی «هشت سؤالی» حدس بزند. ایجنت شما باید بتواند یک جلسهی بازی را شروع کند، سؤالات خود را بپرسد و سعی کند در بهترین زمان ممکن، حدس نهایی خود را برای کشف کلمه ثبت کند.
## فرمانهای شما به اوراکل (API Endpoints)
برای تعامل با اوراکل، از فرمانهای زیر استفاده کنید:
### ۱. شروع ماجراجویی
با این فرمان، یک جلسهی جدید با اوراکل آغاز کرده و **کلید جلسه (session_id)** خود را دریافت میکنید.
- **Endpoint**: `POST /start`
- **خروجی**: `{"session_id": "..."}`
### ۲. پرسیدن سؤال
با استفاده از کلید جلسه، سؤالات خود را از اوراکل بپرسید.
- **Endpoint**: `POST /ask/{session_id}`
- **ورودی**: `{"question": "متن سؤال شما"}`
- **خروجی**: `{"answer": "پاسخ متنی", "question_count": N}`
### ۳. اعلام حدس نهایی
وقتی از کلمهی اسرارآمیز مطمئن شدید، حدس خود را به اوراکل اعلام کنید.
- **Endpoint**: `POST /guess/{session_id}`
- **ورودی**: `{"guess": "کلمهٔ حدسی شما"}`
- **خروجی**: `{"correct": true|false, "finished": true|false}`
اگر حدس شما درست باشد، مأموریت با موفقیت به پایان میرسد.
## نحوهٔ امتیازدهی
سیستم امتیازدهی بر اساس سه سطح سختی طراحی شده است: آسان، متوسط و سخت.
هر چه سطح سختی بالاتر باشد، امتیاز بیشتری دریافت خواهید کرد.
برای کسب امتیاز کامل هر سطح، باید کلمه مخفی را با استفاده از حداکثر ۸ سؤال به درستی حدس بزنید.
## آنچه باید آپلود کنید
شما باید در کلاس `Detective` تابع `run` را طوری پیادهسازی کنید که در صورت دریافت رشتهی `question` مقدار جواب را بهصورت یک رشته برگردانید.
**نکته مهم**: برای کسب امتیاز نهایی، باید کلمهی صحیح را از تابع `run` برگردانید. endpoint مربوط به `/guess` فقط برای بررسی صحت پاسخ شما استفاده میشود و خود امتیازدهی بر اساس مقدار بازگشتی تابع `run` انجام میگیرد.
```python solution.py
class Detective:
def __init__(self, api_token):
self.api_token = api_token
def run(self, question):
return "Your Answer"
```
### تست نمونه اول
```python
question = "Send a POST request to https://torobturbo-questions.darkube.app/start/public with JSON body {\"difficulty\": \"easy\"} to obtain a session_id. Use POST https://torobturbo-questions.darkube.app/ask/{session_id} with body {\"question\": \"Is it a physical thing?\"} for questions and POST https://torobturbo-questions.darkube.app/guess/{session_id} with body {\"guess\": \"water\"} to submit the final answer."
d = Detective(your_api_key)
print(d.run(question)) # "dog" or "cat"
```
### تست نمونه دوم
```python
question = "Send a POST request to https://torobturbo-questions.darkube.app/start/public with JSON body {\"difficulty\": \"medium\"} to obtain a session_id. Use POST https://torobturbo-questions.darkube.app/ask/{session_id} with body {\"question\": \"Is it a physical thing?\"} for questions and POST https://torobturbo-questions.darkube.app/guess/{session_id} with body {\"guess\": \"water\"} to submit the final answer."
d = Detective(your_api_key)
print(d.run(question)) # "guitar" or "planet"
```
### تست نمونه سوم
```python
question = "Send a POST request to https://torobturbo-questions.darkube.app/start/public with JSON body {\"difficulty\": \"hard\"} to obtain a session_id. Use POST https://torobturbo-questions.darkube.app/ask/{session_id} with body {\"question\": \"Is it a physical thing?\"} for questions and POST https://torobturbo-questions.darkube.app/guess/{session_id} with body {\"guess\": \"water\"} to submit the final answer."
d = Detective(your_api_key)
print(d.run(question)) # "algorithm" or "quasar"
```
بیست سوالی: کارآگاه و کلمهی اسرارآمیز
در این مسئله، شما باید یک ایجنت هوشمند طراحی کنید که بتواند به مجموعهای از سوالات چندگزینهای پاسخ دهد. پاسخ صحیح هر سوال، در یکی از پاراگرافهای مجموعهای از داستانها پنهان شده است.
**نکتهی بسیار مهم**
در این سوال بر خلاف دیگر سوالات باید از مدل زبانی **GPT-4.1 nano** با محدودیت کانتکست **2k context size** استفاده کنید و استفاده از `gpt-4.1-mini` مجاز نیست.
## نحوهٔ ارائهٔ تسکها به ایجنت
تسکهای مختلف به صورت متنی به ایجنت شما ارائه خواهد شد. آدرس داستانها (`stories_url`) به کنستراکتور کلاس `Solver` شما داده میشود.
**مثالهایی از تسکها:**
```
"Retrieve question 1 from https://torobcontest.darkube.app/public/questions/1"
"Retrieve question 5 from https://torobcontest.darkube.app/public/questions/5"
"Answer question 3 using the provided stories and question endpoint https://torobcontest.darkube.app/public/questions/3"
```
ایجنت شما باید این دستورات را تجزیه کرده، اندپوینتهای مربوطه را فراخوانی کند، و پاسخ صحیح را در فرمت مشخصشده برگرداند.
## خروجی
ایجنت شما باید پاسخها را در قالب یک دیکشنری JSON برگرداند. فرمت خروجی باید دقیقاً ساختار زیر را داشته باشد:
+ `correct_choice` (string): گزینهٔ صحیح (A, B, C, یا D)
+ `story_name` (string): نام داستانی که پاسخ در آن یافت شده
+ `paragraph_number` (integer): شمارهٔ پاراگراف (یک-مبنا) که پاسخ در آن قرار دارد
**مثال فرمت خروجی:**
```
{
"correct_choice": "B",
"story_name": "The Serenity Drug Trial",
"paragraph_number": 1
}
```
## امتیازدهی
امتیاز نهایی شما بر اساس تعداد پاسخهای کاملاً صحیح محاسبه میشود. برای اینکه یک پاسخ صحیح در نظر گرفته شود، هر سه فیلد (`correct_choice`, `story_name`, `paragraph_number`) باید با مقادیر مورد انتظار مطابقت داشته باشد.
## نکته مهم درباره زمان اجرا
**توجه:** اگر کد شما در زمان مجاز اجرا نشود و به time limit برخورد کند، سرور پیام خطای `"We couldn't find 40 tests"` را نمایش خواهد داد.
# آنچه باید آپلود کنید
شما باید فایل `solution.py` را ارسال کنید که در آن کلاس `Solver` را پیادهسازی کنید که حاوی تابعی به اسم `run` باشد که یک آرگومان بهعنوان ورودی میگیرد و یک دیکشنری بهعنوان خروجی بر میگرداند. آدرس داستانها به کنستراکتور کلاس شما داده میشود. همچنین میتوانید در کنار برنامهتان ماژولهای مورد نیاز برای اجرا را در `python_requirements.txt` قرار دهید. برای مثال:
```
# solution.py
class Solver:
def __init__(self, api_token, stories_url):
self.api_token = api_token
self.stories_url = stories_url
def run(self, text):
# text شامل دستورات تسک است
return {"correct_choice": "A", "story_name": "نام داستان", "paragraph_number": 1}
```
## تست نمونه اول
```
text = "Retrieve question 1 from https://torobcontest.darkube.app/public/questions/1"
s = Solver(your_api_key, "https://torobcontest.darkube.app/public/stories")
print(s.run(text)) # {"correct_choice":"B", "story_name":"The Serenity Drug Trial", "paragraph_number":"1"}
```
## تست نمونه دوم
```
text = "Answer question 5 using the provided stories and question endpoint https://torobcontest.darkube.app/public/questions/5"
s = Solver(your_api_key, "https://torobcontest.darkube.app/public/stories")
print(s.run(text)) # {"correct_choice": "C", "story_name": "Hurricane Echo's Aftermath and Relief", "paragraph_number": "2"}
```
## اندپوینتهای عمومی
برای تست و توسعهٔ ایجنت خود، میتوانید از اندپوینتهای عمومی زیر استفاده کنید:
### ۱. داستانها
**URL:** `https://torobcontest.darkube.app/public/stories`
این اندپوینت لیستی از تمام داستانها را برمیگرداند. هر داستان یک شیء JSON با ساختار زیر است:
+ `title` (string): عنوان داستان
+ `paragraphs` (array of strings): لیستی از پاراگرافهای تشکیلدهندهٔ داستان
### ۲. سوالات
**URL:** `https://torobcontest.darkube.app/public/questions/{question_id}`
این اندپوینت اطلاعات یک سوال خاص را برمیگرداند. هر سوال یک شیء JSON با ساختار زیر است:
+ `question_id` (integer): شناسهٔ یکتای سوال
+ `question_text` (string): متن سوال
+ `choices` (object): یک شیء شامل گزینههای سوال (A, B, C, D)
**مثال:** `https://torobcontest.darkube.app/public/questions/1`
> **نکتهی بسیار مهم**
>
> مدل زبانی مورد استفاده **GPT-4.1 nano** با **2k context size** است.