> یک مسابقهی انتخابی **سخت** و **پرچالش** بعد...
**آمین چیپسخور** *(Aaaamin Chipskhor)،* از دیگر **آمینهای** تاثیرگذار کوئرا که این روزها **پس از بازگشت زودهنگام از خدمت مقدس سربازی،** هنوز وظایف قبلی خود را در کوئرا دوباره تحویل نگرفتهاست، **میزور** *(Mizzor)* این سری از [**#المپیکفناوری پردیس**](https://quera.org/events/techolympics-0407) شدهاست. از آنجایی که تعداد تیمهای شرکتکننده امسال چندین برابر سال گذشته شده، او باید برای همهی آنها **میز مشخصی** تعیین کند تا نظم مسابقه حفظ شود. با این حال، **آمین** علاقهای به استفاده از روشهای ساده و تصادفی **ندارد** و تصمیم میگیرد از **یک روش محاسباتی خاص** و **منحصربهفرد** برای محاسبهی **شماره میز تیمها** استفاده کند. این روش عجیب که در کوئرا شهرهی خاص و عام است، **سیستم میزور** *(Mizzor System)* نام دارد.
در این سیستم، **هر کدام از تیمهای شرکتکننده** در سری جدید [**#المپیکفناوری پردیس**](https://quera.org/events/techolympics-0407)، از **تعدادی عضو** تشکیل شده و **نام** هر عضو در **محاسبهی شمارهی میز** تأثیر دارد. آمین میزور برای این کار ابتدا **برای هر عضو گروه** یک **مقدار هششده** محاسبه میکند که از ترکیب کد عددی کاراکترها و [**دنبالهی فیبوناچی** *(Fibonacci sequence)،*](https://en.wikipedia.org/wiki/Fibonacci_sequence) *که در مدت زمان سربازی مطالعات زیادی بر روی این سری اعداد داشته،* به دست میآید. سپس با جمع کردن این مقادیر و **درنظر گرفتن تعداد اعضا،** یک عدد نهایی برای هر تیم محاسبه میکند. در نهایت، **شمارهی میز تیم** برابر با **باقیماندهی این عدد بر تعداد میزهای موجود در سالن** خواهد بود.

# **پروژهی اولیه**
برای دانلود **پروژهی اولیه** روی [این لینک](/contest/assignments/91477/download_problem_initial_project/310249/) کلیک کنید.
# **جزئیات پروژه**
**تابعی** که شما باید در این سوال پیادهسازی کنید، **تابع** `assign_tables` میباشد و **دو آرگومان ورودی** میگیرد؛ یکی `groups` که **دیکشنریای از نام تیمها و اعضایشان** است و دیگری `tables_num` **تعداد کل میزهای موجود.** همچنین این تابع در خروجی به ترتیب دو مقدار بر خواهد گرداند: **دیکشنریای شامل شمارهی میز اختصاصیافته به هر تیم** و لیستی از **برخوردهایی** *(Collisions)* که **در طی تخصیص میز** رخ دادهاند. اگر برخوردی پیش بیاید، باید در خروجی مشخص شود **کدام تیم جدید** با **کدام تیم قبلی** روی یک میز افتادهاست.
برای مثال، فرض کنید **دیکشنری تیمها شامل سه گروه باشد** که بعضی از آنها **هش یکسان** دارند. پس از اجرای تابع، خروجی شامل **شمارهی میز هر تیم** خواهد بود. اگر دو تیم مقدار **هش** *(Hash)* یکسانی داشته باشند **در یک میز مشترک قرار میگیرند.** سیستم در این حالت آن را بهعنوان یک **برخورد** ثبت میکند و در خروجی نمایش میدهد تا **آمین** بتواند موقتاً با مشغول کردن اعضای این تیمها با بستههای طعمهای مختلف چیپس، **تصمیم بگیرد کدامیک باید به میز دیگری منتقل شود!**
- **تابع هش برای نام اعضای تیمها:**
$$H(\text{name}) = \sum_{i=1}^{L} \big( \text{ord}(c_i) \times F(i) \big)$$
- **که در آن** $ord(c_i)$ [**کد عددی یونیکد** *(Unicode code point)*](https://quera.org/qbox/view/PwFzRF07yR/List_of_Unicode_characters.pdf) **کاراکتر** $i$**-ام نام عضو تیم،** مقدار $L$ **طول نام آن عضو** مشخص و $F(i)$ **عنصر** $i$**-ام سری فیبوناچی** $F$ **است که به شکل زیر تعریف میشود:**
$$F(0) = 0,\quad F(1) = 1,\quad F(n) = F(n-1) + F(n-2) \quad \forall n \ge 2$$
- **حال برای محاسبه شماره میز برای هر تیم به شکل زیر اقدام میکنیم که در آن مقدار** $k$ **برابر با تعداد اعضای تیم است و در این رابطه مجموع مقدار هش شدهی اسامی اعضای تیم را با هم جمع کرده، در تعداد اعضای تیم ضرب و در نهایت باقیمانده آن را بر** $N$ *(تعداد میزهای مسابقه)* **محاسبه میکنیم:**
$$T(G) = \Bigg( \big( \sum_{j=1}^{k} H(M_j) \big) \times k \Bigg) \bmod N$$
- **همچنین تعریف برخورد به شکل زیر خواهد بود:**
$$T(G_1) = T(G_2) \implies \text{Collision} = (\, G_2,\, T(G_2),\, G_1 \,)$$
# **ورودی**
**توجه داشته باشید که این مسئله ورودی استاندارد ندارد.**
بهجای آن، تابع زیر را در **فایل** `solution.py` پیادهسازی کنید. این تابع ورودیها را بهصورت آرگومان توسط سیستم داوری، دریافت خواهد کرد.
```python solution.py python
def assign_tables(groups: dict[str, list[str]], tables_num: int) -> tuple[dict[str, int], list[tuple[str, int, str]]]:
return {}, []
```
- **پارامتر** `groups`**:** یک دیکشنری است که در آن **کلیدها به صورت نام تیمهای شرکتکننده** و **مقدار** هر کلید**، فهرستی از اسامی اعضای آن تیم** است. هر عضو با رشتهای نمایش داده میشود و ترتیب اعضا در فهرست اهمیتی **ندارد.** تابع باید بر اساس ترکیب نام اعضا برای هر تیم، شمارهی میز اختصاصی را محاسبه کند.
- **پارامتر** `tables_num`**:** یک عدد صحیح است که **نشاندهندهی تعداد کل میزهای موجود** در سالن برگزاری مسابقه است. تمامی شمارههای میز باید در بازهی `[0, tables_num - 1]` قرار داشته باشند. شمارهی میز هر تیم با استفاده از عملیات باقیمانده نسبت به این عدد محاسبه میشود.
**نکته:** اگر در فرایند تخصیص میز، دو تیم به یک شمارهی میز مشابه برسند، به این وضعیت **برخورد میز** *(Table Collision)* گفته میشود. در این صورت، تابع باید آن برخورد را در خروجی گزارش دهد تا مشخص شود کدام تیمها روی یک میز افتادهاند. **برخوردها باید در قالب فهرستی از سهتاییها شامل** `(نام تیم جدید، شمارهی میز، نام تیم قبلی)` **بازگردانده شوند.**
# **خروجی**
تابع به ترتیب باید یک **تاپل** *(Tuple)* با دو مقدار برگرداند. **مقدار اول،** یک دیکشنری است که کلیدهای آن نام تیمها و مقادیرشان شمارهی میز اختصاصیافته است و **مقدار دوم،** فهرستی از برخوردهای احتمالی است که در فرایند تخصیص میز شناسایی شدهاند.
# **مثال**
### **ورودی نمونه ۱**
```python solution.py python
groups = {
"Team1": ["Ali", "Sara"],
"Team2": ["Reza", "Nina"],
"Team3": ["Ali", "Sara"]
}
assign_tables(groups, 4)
```
### **خروجی نمونه ۱**
```python solution.py python
({'Team1': 0, 'Team2': 0, 'Team3': 0}, [('Team2', 0, 'Team1'), ('Team3', 0, 'Team2')])
```
<details class="blue">
<summary>
**توضیحات نحوه محاسبه مقادیر برای ورودی ۱**
</summary>
محاسبات را **مرحله به مرحله** برای دادهها به شکل زیر انجام میدهیم:
```python solution.py python
groups = {
"Team1": ["Ali", "Sara"],
"Team2": ["Reza", "Nina"],
"Team3": ["Ali", "Sara"]
}
```
ابتدا برای **نام** `Ali` سه حرف (`A`, `l`, `i`) داریم. **مقدار** `ord` برای آنها به ترتیب `65`، `108` و `105` است. با توجه به دنبالهٔ فیبوناچی $(F(i$ داریم:
$$65 \times F(1) = 65 \times 1 = 65$$
$$108 \times F(2) = 108 \times 1 = 108$$
$$105 \times F(3) = 105 \times 2 = 210$$
جمع این سه مقدار برابر است با:
$$65 + 108 + 210 = 383$$
بنابراین:
$$H("Ali") = 383$$
برای **نام** `Sara` چهار حرف (`S`, `a`, `r`, `a`) داریم. **مقدار** `ord` برای آنها به ترتیب `83`، `97`، `114` و `97` است. محاسبات به شکل زیر است:
$$83 \times F(1) = 83 \times 1 = 83$$
$$97 \times F(2) = 97 \times 1 = 97$$
$$114 \times F(3) = 114 \times 2 = 228$$
$$97 \times F(4) = 97 \times 3 = 291$$
جمع چهار حاصلضرب:
$$83 + 97 + 228 + 291 = 699$$
در نتیجه:
$$H("Sara") = 699$$
برای **نام** `Reza` **چهار حرف** (`R`, `e`, `z`, `a`) داریم که **مقدار** `ord` آنها به ترتیب `82`، `101`، `122` و `97` است. بنابراین:
$$82 \times F(1) = 82 \times 1 = 82$$
$$101 \times F(2) = 101 \times 1 = 101$$
$$122 \times F(3) = 122 \times 2 = 244$$
$$97 \times F(4) = 97 \times 3 = 291$$
جمع این چهار مقدار برابر است با:
$$82 + 101 + 244 + 291 = 718$$
پس:
$$H("Reza") = 718$$
برای **نام** `Nina` چهار حرف (`N`, `i`, `n`, `a`) داریم که **مقادیر** `ord` آنها به ترتیب `78`، `105`، `110` و `97` است. محاسبات به شکل زیر است:
$$78 \times F(1) = 78 \times 1 = 78$$
$$105 \times F(2) = 105 \times 1 = 105$$
$$110 \times F(3) = 110 \times 2 = 220$$
$$97 \times F(4) = 97 \times 3 = 29$$
و جمع آنها برابر است با:
$$78 + 105 + 220 + 291 = 694$$
بنابراین:
$$H("Nina") = 694$$
اکنون مقدار شماره میز هر تیم را با استفاده از $(T(G$ محاسبه میکنیم. طبق فرمول:
$$T(G) = \Big( \big(\sum_{j=1}^{k} H(M_j) \big) \times k \Big) \bmod N$$
برای `Team1` با **اعضای** `Ali` و `Sara` داریم:
$$T(Team1) = ((383 + 699) \times 2) \bmod N = (1082 \times 2) \bmod N = 2164 \bmod 4 = 0$$
برای `Team2` با **اعضای** `Reza` و `Nina` داریم:
$$T(Team2) = ((718 + 694) \times 2) \bmod N = (1412 \times 2) \bmod N = 2824 \bmod 4 = 0$$
برای `Team3` که اعضایش همانند `Team1` هستند:
$$T(Team3) = ((383 + 699) \times 2) \bmod N = 2164 \bmod 4 = 0$$
در نتیجه مقدار نهایی شماره میز هر گروه (پیش از محاسبهٔ باقیمانده بر $N$) برابر است با:
$$T(Team1) = 0, \quad T(Team2) = 0, \quad T(Team3) = 0$$
چون `(T(Team1) = T(Team3))`، این دو تیم به یک میز اختصاص داده میشوند و در نتیجه یک برخورد رخ میدهد:
$$Collision = ('Team2', 1, 'Team1')$$
$$Collision = ('Team3', 1, 'Team2')$$
</details>
+ در این ورودی خاص، هر سه تیم در نهایت **عدد صفر** را بهعنوان شمارهی میز خود به دست میآورند. دلیل این موضوع این است که مجموع هشهای تولیدشده برای اعضا، پس از ضرب در اندازهی تیم و گرفتن باقیمانده بر ۴، برابر با **صفر** شده است. به همین خاطر، **تمام تیمها روی یک میز** *(میز شماره ۰)* قرار گرفتهاند و تابع در خروجی، علاوهبر دیکشنری شماره میزها، لیستی از **برخوردها** را نیز برمیگرداند. در این لیست مشخص است که **تیم دوم** با **تیم اول** برخورد کرده (`('Team2', 0, 'Team1')`) و **تیم سوم** هم با **تیم دوم** (`('Team3', 0, 'Team2')`) به یک میز اختصاص داده شدهاند، که نشاندهندهی تداخل در تخصیص میزها است.
### **ورودی نمونه ۲**
```python solution.py python
groups = {
"QuantumCoders": ["Amir", "Reza", "Sara"],
"AIWarriors": ["Nina", "Ali", "Mina"],
"DataTitans": ["Omid", "Reza", "Sina", "Tara"],
"BugHunters": ["Amir", "Reza"],
"CyberFalcons": ["Nina", "Ali"],
"PixelLords": ["Mina", "Sina", "Tara"]
}
assign_tables(groups, 6)
```
### **خروجی نمونه ۲**
```python solution.py python
({'QuantumCoders': 3, 'AIWarriors': 0, 'DataTitans': 4, 'BugHunters': 2, 'CyberFalcons': 0, 'PixelLords': 0}, [('CyberFalcons', 0, 'AIWarriors'), ('PixelLords', 0, 'CyberFalcons')])
```
<details class="blue">
<summary>
**توضیحات نحوه محاسبه مقادیر برای ورودی ۲**
</summary>
محاسبات را **مرحله به مرحله** برای دادهها به شکل زیر انجام میدهیم:
```python solution.py python
groups = {
"QuantumCoders": ["Amir", "Reza", "Sara"],
"AIWarriors": ["Nina", "Ali", "Mina"],
"DataTitans": ["Omid", "Reza", "Sina", "Tara"],
"BugHunters": ["Amir", "Reza"],
"CyberFalcons": ["Nina", "Ali"],
"PixelLords": ["Mina", "Sina", "Tara"]
}
```
ابتدا برای **نام** `Amir` چهار حرف (`A`, `m`, `i`, `r`) داریم. **مقدار** `ord` آنها به ترتیب `65`, `109`, `105`, `114` است. محاسبات با دنباله فیبوناچی:
$$65 \times F(1) = 65 \times 1 = 65$$
$$109 \times F(2) = 109 \times 1 = 109$$
$$105 \times F(3) = 105 \times 2 = 210$$
$$114 \times F(4) = 114 \times 3 = 342$$
جمع مقادیر:
$$65 + 109 + 210 + 342 = 726$$
بنابراین:
$$H("Amir") = 726$$
برای **نام** `Reza` همانند قبل:
$$H("Reza") = 718$$
برای **نام** `Sara`:
$$H("Sara") = 699$$
حال برای تیم `QuantumCoders` با اعضای `Amir`, `Reza`, `Sara` داریم ((k=3)):
$$T(QuantumCoders) = ((726 + 718 + 699) \times 3) \bmod 6 = (2143 \times 3) \bmod 6 = 6429 \bmod 6 = 3$$
برای **تیم** `AIWarriors` با اعضای `Nina`, `Ali`, `Mina`:
$$H("Nina") = 694$$
$$H("Ali") = 383$$
$$H("Mina") = 693$$
$$T(AIWarriors) = ((694 + 383 + 693) \times 3) \bmod 6 = (1770 \times 3) \bmod 6 = 5310 \bmod 6 = 0$$
برای **تیم** `DataTitans` با اعضای `Omid`, `Reza`, `Sina`, `Tara`:
$$H("Omid") = 698$$
$$H("Reza") = 718$$
$$H("Sina") = 699$$
$$H("Tara") = 700$$
$$T(DataTitans) = ((698 + 718 + 699 + 700) \times 4) \bmod 6 = (2815 \times 4) \bmod 6 = 11260 \bmod 6 = 4$$
برای **تیم** `BugHunters` با اعضای `Amir`, `Reza`:
$$T(BugHunters) = ((726 + 718) \times 2) \bmod 6 = (1444 \times 2) \bmod 6 = 2888 \bmod 6 = 2$$
برای **تیم** `CyberFalcons` با اعضای `Nina`, `Ali`:
$$T(CyberFalcons) = ((694 + 383) \times 2) \bmod 6 = (1077 \times 2) \bmod 6 = 2154 \bmod 6 = 0$$
برای **تیم** `PixelLords` با اعضای `Mina`, `Sina`, `Tara`:
$$T(PixelLords) = ((693 + 699 + 700) \times 3) \bmod 6 = (2092 \times 3) \bmod 6 = 6276 \bmod 6 = 0$$
در نتیجه مقدار نهایی شماره میز هر گروه برابر است با:
$$T(QuantumCoders) = 3, \quad T(AIWarriors) = 0, \quad T(DataTitans) = 4, \quad T(BugHunters) = 2, \quad T(CyberFalcons) = 0, \quad T(PixelLords) = 0$$
چون شماره میز بعضی تیمها یکسان است، **برخوردها** *(Collision)* به شکل زیر رخ میدهد:
$$Collision = ('CyberFalcons', 0, 'AIWarriors')$$
$$Collision = ('PixelLords', 0, 'CyberFalcons')$$
</details>
+ برای مثال، **تیم** `QuantumCoders` متشکل از سه عضو است و هش نامهای آنها طوری محاسبه شده که مجموع نهایی پس از اعمال عملیات مشخصشده در تابع، منجر به تخصیص میز شماره **۳** میشود. در همین حال، **تیمهای** `AIWarriors`، `CyberFalcons` و `PixelLords` همگی به میز شماره **۰** اختصاص داده شدهاند، چون مقدار محاسبهشدهی نهایی آنها در تقسیم بر ۶، باقیماندهی **صفر** دادهاست. از آنجا که چند تیم به یک میز مشترک تخصیص یافتهاند، تابع علاوهبر دیکشنری اصلی از شمارهی میزها، لیستی از **برخوردها** را نیز بازمیگرداند. در این لیست مشخص است که **تیم** `CyberFalcons` با `AIWarriors` بر سر میز شماره ۰ برخورد داشته و پس از آن **تیم** `PixelLords` نیز با `CyberFalcons` در همان میز تداخل پیدا کردهاست.
# **زیرمسئلهها**
سیستم داوری برای این سوال به **زیرمسئلههای** زیر برای نمرهدهی تقسیمبندی شده است که میتوانید **امتیاز** مربوط به هر کدام را در جدول زیر مشاهده کنید. **زیرمسئلههای** این جدول **ابتدا بر اساس اولویت و پیشنیازی پیادهسازی** و سپس **بر اساس امتیاز** آنها مرتبسازی شدهاند. **لذا پیشنهاد میشود در پیادهسازی از زیرمسئلهی ابتدایی آغاز کنید.**
| **زیرمسئله** | **امتیاز** |
| ----------------------------- | ------ |
| **پیادهسازی تابع** `assign_tables` | `100` |
# **آنچه باید آپلود کنید**
+ **توجه**: پس از پیادهسازی تابع خواستهشده، **فایل** `solution.py` را برای سیستم داوری ارسال کنید.
+ **توجه**: شما مجاز به افزودن فایل جدیدی در این ساختار **نیستید** و تنها باید تغییرات را در **فایل** `solution.py` اعمال کنید.
+ **توجه**: ایجاد هرگونه **تغییرات اضافی** در **امضا** *(Signature)* و **خروجی تابع** `assign_tables` که خارج از تعریف سؤال باشد، در سیستم داوری **مورد پذیرش قرار نگرفته** و نمرهای دریافت **نخواهد** کرد.
+ **توجه:** **فایل** `solution.py` **نباید** هیچ **عملکرد اضافهای** برای گرفتن **ورودی استاندارد** *(stdin)* و دادن **خروجی استاندارد** *(stdout)* مانند `print` کردن پاسخ را شامل باشد، در غیر این صورت نمرهای دریافت **نخواهد** کرد. سیستم داوری خود مسئول **فراخوانی تابع** `assign_tables`، دادن آرگومانهای ورودی به آن و بررسی خروجی است.
آمین میزور
> تو معجون گل و مخمل و نوری **سعیدهی** قصههای حوری
> تموم **محصولا** بی تو میمیرن که تو حوصله سنگ صبوری
> تو رو میطلبم لحظه به لحظه تویی تاب و تبم لحظه به لحظه
> **محصولات** شهر منه که شهر قصه است برای **کوئرا** لحظه به لحظه
**سعیده** *(Saeedeh)* از مدیران محصول خسته و کمی عجیب کوئرا است که تازهترین شیوههایش برای مدیریت **مشکلات** *(Problems)،* **تیمهای فنی کوئرا** را حسابی گیج کرده است. او به جای استفاده از ابزارهای حرفهای و رایج برای مدیریت پروژه، تصمیم گرفته تا سیستمی جدید **هرم مشکلگشا** را برای **اولویتبندی مشکلات تیم** طراحی کند. سیستمی که در آن، هر مشکل به شکل بخشی از یک **هرم متنی** نمایش داده میشود. با شروع سری جدید [**#المپیکفناوری پردیس،**](https://quera.org/events/techolympics-0407) سعیده به خاطر مشغلهی زیادش در جلسات و علاقهی شدیدش به نمودارهای دیداری، هرم مشکلگشا را بهگونهای طراحی میکند که با هر رفتن از بالا به پایین، بخشی از رشتهی ورودی (که نماد مشکلات مختلف تیم است) درون هرم قرار بگیرد. اما در پایان، این هرم باید **وارونه** چاپ شود تا ترتیب درست اولویت حل و فصل مشکلات از بالا به پایین مشخص شود.
از آنجا که سعیده، که **دانش کمی** در برنامهنویسی دارد، **تنها یک خط کد را میتواند بخواند** *(بیشتر از آن برایش غیرضروری و گیجکننده است)،* از شما میخواهد برنامهای بنویسید که در **تنها و تنها یک خط**، برگرداندن هرم مشکلگشا را پیادهسازی کند. برنامه باید **رشتهای را از آرگومان تابع** دریافت کند و سپس بهصورت وارونه، بخشبهبخش هرم را چاپ کند؛ بهطوری که **در هر سطر بخشی از رشته قرار بگیرد** و در صورت **ناکافی بودن طول رشته،** جای خالی مشکلات با `#` پر شود.
# **پروژهی اولیه**
برای دانلود **پروژهی اولیه** روی [این لینک](/contest/assignments/91477/download_problem_initial_project/310248/) کلیک کنید.
# **جزئیات پروژه**
**تابعی** که شما باید در این سؤال پیادهسازی کنید، **تابع** `saeedeh_pyramid` است. این **تابع تنها یک آرگومان ورودی** `s` دریافت میکند که **رشتهای از کاراکترها** *(حروف، اعداد یا نمادها)* است. هدف تابع، تبدیل این **رشته** *(که مجموعهای مشکلات در کوئراست)* به **ساختاری هرمی شکل معکوس** است که در آن هر سطر، **بخشی از رشته را با طولی مشخص نمایش میدهد.** تعداد کاراکترهای هر سطر بر اساس **مجموع دنبالهی اعداد طبیعی** *(یعنی ۱، ۱+۲، ۱+۲+۳، و به همین ترتیب)* تعیین میشود. اگر در یک سطر، **طول رشته برای پر کردن کامل آن کافی نباشد،** با **کاراکتر** `#` **جای خالیها پر میشود تا شکل منظم هرم حفظ گردد.**
در انتهای پردازش، **تمام سطرها به ترتیب معکوس به هم متصل شده** و با **کاراکتر** `\n` از هم جدا میشوند تا خروجی بهصورت یک رشتهی چندخطی **بازگردانده** *(return)* شود. بدین ترتیب، خروجی نهایی از **بالا به پایین کوچکتر میشود،** گویی **رأس هرم در پایین قرار دارد.** برای مثال، اگر **رشتهای مانند** `"abcdefg"` به تابع داده شود، تابع ابتدا آن را به بخشهایی با طولهای ۱، ۲، ۳ و ... تقسیم میکند **تا زمانی که طول رشته کافی باشد.** سپس این بخشها را برعکس کرده و با استفاده از `#` **جای خالیها را پر میکند** تا **خروجی نهایی الگویی منظم و بصری از یک هرم معکوس ایجاد کند.**
# **ورودی**
**توجه داشته باشید که این مسئله ورودی استاندارد ندارد.** بهجای آن، تابع زیر را در **فایل** `solution.py` پیادهسازی کنید. این تابع ورودیها را بهصورت آرگومان توسط سیستم داوری دریافت خواهد کرد.
```python solution.py python
def saeedeh_pyramid(s: str) -> str: return None
```
**پارامتر** `s`**:** **یک رشتهی متنی شامل مجموعهای از حروف،** اعداد یا نمادهاست که قرار است به **ساختاری هرمی** تبدیل شود. این **رشته** میتواند **طول دلخواهی داشته باشد** و هیچ محدودیتی از نظر نوع کاراکترها **ندارد.** تابع باید بر اساس الگوی از پیش تعیینشده، کاراکترهای این رشته را در چندین سطر به ترتیبهای خاص قرار دهد **تا خروجی نهایی به شکل یک هرم معکوس نمایش داده شود.**
در فرایند ساخت هرم، **طول هر سطر** با استفاده از **مجموع متوالی اعداد طبیعی** *(۱، ۱+۲، ۱+۲+۳ و به همین ترتیب)* تعیین میشود. برای هر مرحله، از موقعیت حاصل از این مجموع برای بریدن بخش موردنظر از رشته استفاده میشود. اگر در انتهای رشته کاراکتر کافی برای پر کردن کامل آن سطر **وجود نداشته باشد،** باید با **کاراکتر**`#` جای خالیها پر شود **تا ساختار منظم باقی بماند.**
**نکته:** ترتیب سطرها در نهایت باید **برعکس** شود، یعنی **آخرین بخش ساختهشده در بالای خروجی** و **اولین بخش در پایین** قرار گیرد. این موضوع باعث میشود که **هرم بهصورت معکوس** نمایش داده شود. **خروجی نهایی باید رشتهای باشد که سطرها با کاراکتر** `\n` **از هم جدا شدهاند.**
# **خروجی**
**برگرداندن** *(return کردن)* وارونهی **هرم مشکلگشای سعیده،** بهطوری که در هر خط بخشی از رشته *(به اندازهی طول خط از بالا به پایین)* قرار گیرد و **اگر طول رشته برای پر کردن خط کافی نبود،** جای خالی با `#` پر شود.
# **مثال**
### **ورودی نمونه ۱**
```python solution.py python
saeedeh_pyramid("AaBbCc123")
```
### **خروجی نمونه ۱**
```python solution.py python
'123#\nbCc\naB\nA'
# 123#
# bCc
# aB
# A
```
+ در این مثال، **رشتهی** `'123bCcaBA'` به تابع داده شدهاست تا به شکل **یک هرم مشکلگشا** نمایش داده شود. هر خط از خروجی شامل تعداد حروفی از رشته است که **بر اساس دنبالهی دنبالهی اعداد طبیعی تا آن خط انتخاب شده** و در صورت کوتاهی با `#` پر میشود. در هنگام چاپ، خروجی نهایی با `\n` جدا شده و بهصورت **معکوس** چاپ میشود، به طوری که **آخرین قطعهی رشته** در بالا قرار میگیرد و **اولین قطعه در پایین.** این باعث میشود رشته به شکل **یک هرم وارونه با لایههای متفاوت طول ظاهر شود.** در خروجی نمونه، **اولین خط** `'123#'` **بزرگترین** لایه است که با `#` پر شده، **دومین خط** `'bCc'` لایهی بعدی است، **سومین** `'aB'` و **آخرین خط** `'A'` **کوچکترین** و **بالاترین** لایهی هرم را تشکیل میدهد. ترتیب خطوط و پر کردن با `#` باعث میشود ساختار بصری هرم واضح و قابل تشخیص باشد. همچنین در انتها خروجی در صورت چاپ شدن به صورت بخش کامنتشده در قسمت بالا خواهد بود.
### **ورودی نمونه ۲**
```python solution.py python
saeedeh_pyramid("abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ")
```
### **خروجی نمونه ۲**
```python solution.py python
'TUVWXYZ####\nJKLMNOPQRS\nABCDEFGHI\n23456789\nvwxyz01\npqrstu\nklmno\nghij\ndef\nbc\na'
# TUVWXYZ####
# JKLMNOPQRS
# ABCDEFGHI
# 23456789
# vwxyz01
# pqrstu
# klmno
# ghij
# def
# bc
# a
```
+ در این مثال، **رشتهی ورودی شامل تمام حروف الفبا به همراه اعداد** و **حروف بزرگ انگلیسی** است و به تابع داده شده تا **به شکل هرم مشکلگشا تجزیه و چاپ شود.** هر لایهی هرم شامل تعداد مشخصی از کاراکترهاست که بر اساس دنبالهی اعداد طبیعی انتخاب شده و در صورت کوتاهی با `#` پر میشود. خروجی به صورت معکوس تولید میشود، به طوری که **بزرگترین لایه در پایین** هرم قرار دارد و **کوچکترین لایه در بالای هرم.** اولین خط خروجی `'TUVWXYZ####'` شامل کاراکترهای انتهای رشته و پر شدن با `#` است تا طول لایه کامل شود، **خط دوم** `'JKLMNOPQRS'` لایهی بعدی و به همین ترتیب ادامه مییابد. **خطوط میانی شامل حروف بزرگ** و **اعداد** هستند و **خطوط پایین هرم حروف کوچک را نمایش میدهند.** این ترتیب معکوس باعث میشود هرم از پایین به بالا بزرگ و کوچک شود و الگوی بصری هرم حفظ شود. همچنین در انتها خروجی در صورت چاپ شدن به صورت بخش کامنتشده در قسمت بالا خواهد بود.
# **زیرمسئلهها**
سیستم داوری برای این سوال به **زیرمسئلههای** زیر برای نمرهدهی تقسیمبندی شده است که میتوانید **امتیاز** مربوط به هر کدام را در جدول زیر مشاهده کنید. **زیرمسئلههای** این جدول **ابتدا بر اساس اولویت و پیشنیازی پیادهسازی** و سپس **بر اساس امتیاز** آنها مرتبسازی شدهاند. **لذا پیشنهاد میشود در پیادهسازی از زیرمسئلهی ابتدایی آغاز کنید.**
| **زیرمسئله** | **امتیاز** |
| ----------------------------- | ------ |
| **پیادهسازی تابع** `saeedeh_pyramid` | `200` |
# **آنچه باید آپلود کنید**
+ **توجه**؛ کد نوشته شده توسط شما باید **تنها و تنها یک خط** داشته باشد، در غیر این صورت نمرهای دریافت **نخواهد** کرد. همچنین توجه داشته باشید استفاده از **توابعی مثل** `exec` و `eval` و همچنین فشرده کردن کد با استفاده از `;` در یک خط مجاز **نخواهد** بود و **نمرهی صفر دریافت میکند.**
+ **توجه**: پس از پیادهسازی تابع خواسته شده، **فایل** `solution.py` را برای سیستم داوری ارسال کنید.
+ **توجه**: شما مجاز به افزودن فایل جدیدی در این ساختار **نیستید** و تنها باید تغییرات را در **فایل** `solution.py` اعمال کنید.
+ **توجه**: ایجاد هرگونه **تغییرات اضافی** در **امضا** *(Signature)* و **خروجی تابع** `saeedeh_pyramid` که خارج از تعریف سوال باشد، در سیستم داوری **مورد پذیرش قرار نگرفته** و نمرهای دریافت **نخواهد** کرد.
+ **توجه:** **فایل** `solution.py` **نباید** هیچ **عملکرد اضافهای** برای گرفتن **ورودی استاندارد** *(stdin)* و دادن **خروجی استاندارد** *(stdout)* مانند `print` کردن پاسخ را شامل باشد، در غیر این صورت نمرهای دریافت **نخواهد** کرد. سیستم داوری خود مسئول **فراخوانی تابع** `saeedeh_pyramid`، دادن آرگومانهای ورودی به آن و بررسی خروجی است.
هرم مشکلگشا
> تو مگو همه به جنگند و زِ صلح من چه آید **تو یکی نِهای هزاری تو چراغِ خود برافروز...**
**باقر** *(Bagher)،* که پس از **تغییراتی ابلفضلی** در ساختار اسکواد کوئرا کالج، این بار اما با شروع [**سری جدید #المپیکفناوری پردیس**](https://quera.org/events/techolympics-0407) تصمیم به تاسیس آکادمی آموزشی جدیدی با نام **باقرآکادمی** گرفته که قرار است مرزهای آموزش برنامهنویسی و هوشمصنوعی را این بار با اما همکاری **پارک فناوری پردیس،** *از قلبهای تپندهی فناوری ایران،* جابهجا کند. **باقرآکادمی** اما برخلاف مجموعههای آموزشی دیگر از **یک روش جدید** و **پیشرفته** برای ارزیابی دانشجویانش استفاده میکند!
انواع مختلفی از سوالات آموزشی که در **باقرآکادمی** پشتیبانی میشوند، مانند **سوالات چندگزینهای** و یا **کوتاهپاسخ،** میتوانند برخلاف سوالات چندگزینهای و کوتاهپاسخی که پیشتر دیدهاید، شامل *متغیرها، روابط ریاضی و بازههای عددی* در قالب **مانیفست سوالات** *(Question Manifest)* باشند. کارکنان این مجموعه، سوالات را در هنگام طراحی به صورت **مانیفستهایی زنده** و **متغیر** برای تولید **نه تنها یک نمونه سوال،** بلکه **هزاران نمونه سوال جدید مشابه** اما با بدنههای متغیر، بیان میکنند! **تو یکی بلکه هزاری تو سوال خود برافروز...**

# **پروژه اولیه**
برای دانلود **پروژهی اولیه** روی [این لینک](/contest/assignments/91477/download_problem_initial_project/310250/) کلیک کنید.
<details class="yellow">
<summary>
**ساختار فایلها**
</summary>
```
bagher-academy
├── core
│ ├── __init__.py
│ ├── <mark class="yellow" title="این فایل باید پیادهسازی شود">evaluator.py</mark>
│ ├── <mark class="yellow" title="این فایل باید پیادهسازی شود">placeholder.py</mark>
│ ├── <mark class="yellow" title="این فایل باید پیادهسازی شود">renderer.py</mark>
│ └── <mark class="yellow" title="این فایل باید پیادهسازی شود">variable_resolver.py</mark>
├── data
│ ├── configs
│ └── templates
├── engine
├── main.py
├── models
│ ├── __init__.py
│ ├── <mark class="blue" title="این فایل پیادهسازی شده است">base_question.py</mark>
│ ├── <mark class="yellow" title="این فایل باید پیادهسازی شود">matching.py</mark>
│ ├── <mark class="yellow" title="این فایل باید پیادهسازی شود">mcq.py</mark>
│ ├── <mark class="yellow" title="این فایل باید پیادهسازی شود">numeric_range.py</mark>
│ ├── <mark class="yellow" title="این فایل باید پیادهسازی شود">question_bank.py</mark>
│ ├── <mark class="yellow" title="این فایل باید پیادهسازی شود">short_answer.py</mark>
│ └── <mark class="yellow" title="این فایل باید پیادهسازی شود">true_false.py</mark>
├── questions
├── utils
└── valid_files
```
</details>
<details class="grey">
<summary>
**راهاندازی پروژه**
</summary>
## **تعریف مانیفست سؤالها**
هر سؤال در باقرآکادمی بهصورت یک **مانیفست** *JSON* در مسیر `data/templates/` تعریف میشود. مثلاً برای **سؤال کوتاهپاسخ:**
```json data/templates/short_answer_template.json json
{
"id": "short",
"type": "short_answer",
"template": {
"stem": "یک جسم از ارتفاع {{height}} متر رها میشود. شتاب گرانش g = {{g}} m/s² است. سرعت برخورد جسم با زمین چقدر است؟",
"answer": "{{sqrt(2*g*height)}}"
},
"variables": {
"height": [5, 20],
"g": [9.7, 9.9]
}
}
```
## **اجرای برنامه** *CLI*
### **تولید سه نسخه از سؤال کوتاهپاسخ** *(بدون ذخیره)*
```bash terminal terminal
python main.py --template short
```
### **تولید پنج نسخه از سؤال پرتابه** *(numeric_range)*
```bash terminal terminal
python main.py --template projectile_range --count 5
```
### **تولید و ذخیره خروجی بهصورت فایل** *JSON*
```bash terminal terminal
python main.py --template short --count 3 --save
```
در این حالت، فایلهای زیر بهصورت خودکار ساخته میشوند:
```
questions/
└── short/
├── question1.json
├── question2.json
└── question3.json
```
## **ساختار خروجی هر سؤال**
**نمونه خروجی برای** `short_answer`**:**
```json question1.json json
{
"id": "short",
"type": "short_answer",
"rendered": {
"stem": "یک جسم از ارتفاع 12 متر رها میشود. شتاب گرانش g = 9.8 m/s² است. سرعت برخورد جسم با زمین چقدر است؟",
"answer": "15.34"
},
"vars": {
"height": 12,
"g": 9.8
}
}
```
</details>
# **جزئیات پروژه**
در این پروژه، هدف **پیادهسازی یک ساختار برای تولید** و **مدیریت انواع سوالات آموزشی** است که شامل قالبهای مختلف مانند *چندگزینهای، پاسخ کوتاه، درست/نادرست، تطبیقی و بازه عددی* میشود. این سیستم باید بتواند **مانیفست سوال** را از [**فایلهای** *JSON*](https://en.wikipedia.org/wiki/JSON) بارگذاری کند، **متغیرهای** *(Variables)* مرتبط با هر سوال را با استفاده از محدودهها و قواعد مشخص تولید کند و سپس **متن نهایی سوال** و **گزینهها** یا **پاسخها** را با جایگذاری **مقادیر متغیرها** و **محاسبات ریاضی** محاسبهشده ایجاد کند. ساختار پروژه بر اساس **کلاسهای پایه** و **قابل ارثبری** طراحی شده است؛ `BaseQuestion` **رابط اصلی** را فراهم میکند و **کلاسهای خاص مانند** `MultipleChoiceQuestion` یا `NumericRangeQuestion` این رابط را پیادهسازی میکنند و مسئول **مدیریت قالب، اعتبارسنجی و تولید نسخههای متغیرهای مختلف** هستند. بخشهای کمکی مانند `SafeEvaluator` برای **محاسبهی عبارات ریاضی،** `PlaceholderProcessor` **برای پردازش متنهای قالببندیشده** با *placeholder* و `VariableResolver` **برای تولید مقادیر متغیرها** استفاده میشوند **تا کل جریان تولید سوال، از بارگذاری قالب تا رندر نهایی قابل اجرا باشد.**
<details class="grey">
<summary>
**معرفی مانیفستهای باقرآکادمی - یکی بلکه هزاری سوال!**
</summary>
در باقرآکادمی، هر **سوال** با یک **مانیفست** به صورت قالب *JSON* تعریف میشود که شامل **شناسه یکتا** (`id`)، **نوع سوال** (`type`)، **قالب متنی** (`template`) و **محدوده مقادیر متغیرها** (`variables`) است. این مانیفستها، **ساختار اصلی سوال را تعیین میکنند** و به سیستم اجازه میدهند تا **نسخههای مختلفی از یک سوال با مقادیر متغیر متفاوت تولید کند.** قالبها میتوانند شامل *placeholderهایی* در **قالب** `{{...}}` باشند که با مقادیر تولید شده جایگزین میشوند و **حتی محاسبات ریاضی درون آنها توسط** `SafeEvaluator` انجام میشود.
برای مثال، مانیفست **سوالات با نوع کوتاهپاسخ** `short_answer` با **شناسه** `short` به صورت زیر تعریف شده است:
```json short_answer_template.json json
{
"id": "short",
"type": "short_answer",
"template": {
"stem": "یک جسم از ارتفاع <mark class="blue" title="مقدار ارتفاع در سوال یک متغیر است">{{height}}</mark> متر رها میشود. شتاب گرانش g = <mark class="blue" title="مقدار شتاب گرانش زمین یک متغیر است">{{g}}</mark> m/s² است. سرعت برخورد جسم با زمین چقدر است؟",
"answer": "<mark class="blue" title="پاسخ نهایی سوال یک عبارت ریاضی متغیر است">{{sqrt(2*g*height)}}</mark>"
},
"variables": {
"height": [5, 20],
"g": [9.7, 9.9]
}
}
```
+ در این مثال، متن سوال شامل دو متغیر **ارتفاع** (`height`) و **شتاب گرانش** (`g`) است که در کد بالا با رنگ آبی مشخص شدهاند و **پاسخ به صورت عبارت ریاضی** `sqrt(2*g*height)` مشخص شده است. باقرآکادمی در هر اجرا، مقادیر **مجاز در محدوده مشخص شده برای متغیرها** را تولید کرده و پاسخ را محاسبه و جایگذاری میکند. خروجی نهایی، سوالات مختلفی است که ممکن است چیزی شبیه به این باشد:
```json short_answer_question.json json
{
"stem": "یک جسم از ارتفاع 12 متر رها میشود. شتاب گرانش g = 9.8 m/s² است. سرعت برخورد جسم با زمین چقدر است؟",
"answer": "15.34",
"vars": {"height": 12, "g": 9.8}
}
```
**مانیفست** `numeric_range` با **شناسه** `projectile_range` نیز مشابه عمل میکند، اما **پاسخ عددی با تلرانس مشخص ارائه میشود** تا امکان مقایسه با جواب کاربر فراهم باشد:
```json numeric_range_template.json json
{
"id": "projectile_range",
"type": "numeric_range",
"template": {
"stem": "اگر یک جسم با سرعت اولیه <mark class="blue" title="مقدار سرعت در این سوال یک متغیر است">{{v0}}</mark> m/s به صورت افقی پرتاب شود، فاصله طی شده قبل از برخورد زمین چقدر است؟",
"answer": "<mark class="blue" title="پاسخ نهایی سوال یک عبارت ریاضی متغیر است">{{v0*sqrt(2*height/g)}}</mark>",
"tolerance": 0.05
},
"variables": {
"v0": [10, 30],
"height": [5, 20],
"g": [9.7, 9.9]
}
}
```
خروجی پردازش شده این سوال ممکن است به شکل زیر باشد:
```json numeric_range_question.json json
{
"stem": "اگر یک جسم با سرعت اولیه 15 m/s به صورت افقی پرتاب شود، فاصله طی شده قبل از برخورد زمین چقدر است؟",
"answer": "21.0",
"tolerance": 0.05,
"vars": {"v0": 15, "height": 10, "g": 9.8}
}
```
و برای انواع دیگر سوالات نیز به همین ترتیب خواهد بود. به طور خلاصه، **مانیفستها،** قالبهای *JSON* **انعطافپذیری** هستند که مشخص میکنند سوال چه **متغیرهایی** دارد، **متن چگونه تولید شود** و **پاسخ چگونه محاسبه گردد.** باقرآکادمی با استفاده از کلاسهای مدیریت سوالات، **پردازش** *placeholderها* و تولید مقادیر متغیر و پاسخ نهایی، **سوالات آماده برای آزمونها** تولید میکند که **قابلیت ارزیابی درست کاربران** را دارند.
</details>
<details class="blue">
<summary>
**پیادهسازی پوشه** `core`
</summary>
<details class="blue">
<summary>
**پیاده سازی کلاس** `SafeEvaluator` **از فایل** `evaluator.py`
</summary>
**کلاس** `SafeEvaluator` در **فایل** `core/evaluator.py` باید ابزاری باشد که بتواند **عبارات ریاضی متنی** را بر اساس **مجموعهای از متغیرها** ارزیابی کرده و **مقدار عددی دقیق** آن را بازگرداند. **ورودی اصلی متد** `eval` **یک رشتهی بیان ریاضی است،** که ممکن است شامل *عملگرهایی مثل جمع، تفریق، ضرب، تقسیم، توان، باقیمانده، و حتی فراخوانی توابعی مانند* `sqrt`*،* `log`*،* `sin` *یا* `cos` باشد. خروجی آن باید یک عدد *(صحیح یا اعشاری)* باشد که با **دقت مشخصی** *(مثلاً تا سه رقم اعشار)* **گرد** شده است تا نتایج در تمام اجراها، **قطعی و مشخص** باقی بمانند. در صورتی که عبارت شامل *نامهای ناشناخته، توابع غیرمجاز یا سینتکس نامعتبر* باشد، باید **خطای** `ValueError` **بازگردانده** شود تا از **اجرای کد ناامن جلوگیری شود.**
همچنین کلاس باید از **ثابتهای ریاضی مثل** `pi` و `e` **پشتیبانی کند** تا تستهایی که از توابع مثلثاتی یا لگاریتمی استفاده میکنند بهدرستی کار کنند. **اگر متغیرهایی مانند** `x`، `y` یا `a` در عبارت وجود داشته باشند، مقادیر آنها از **دیکشنری ورودی** گرفته میشود تا بتوان عبارات پارامتری را نیز ارزیابی کرد. بهعلاوه، در *تستهایی که چند عمل ریاضی پشتسرهم ترکیب شدهاند، ترتیب تقدم عملگرها و تو در تویی توابع* **باید حفظ شود** تا نتایج عددی **دقیقاً با خروجی کتابخانهی** `math` برابر باشند.
**متد** `eval` در **کلاس** `SafeEvaluator` **نقش اصلی را در تبدیل یک رشتهی متنی حاوی عبارت ریاضی به مقدار عددی ایفا میکند.** ورودی این متد یک رشته است که ممکن است شامل *اعداد، متغیرها، عملگرهای ریاضی و توابع مجاز مانند* `sqrt`, `log`, `sin` باشد و **خروجی آن یک مقدار عددی** *(صحیح یا اعشاری)* است که با **دقت مشخص گرد شده است.**همانطور که پیشتر گفته شد، این متد باید **تمام ترکیبهای تو در تو و زنجیرهای از عملیات ریاضی** را به درستی محاسبه کند، به طوری که حتی عبارات پیچیده مثل `a + b * c ** 2 - (b + c)/a` یا `sqrt(abs(log(exp((x + y)**2))))` دقیقاً همان نتیجهای را بدهند که انتظار میرود.
علاوه بر این، `eval` باید بهطور کامل **ایمن** باشد و هیچگونه کد اجرایی یا فراخوانی **توابع غیرمجاز** را اجازه **ندهد؛** اگر عبارت شامل **نامهای ناشناخته** یا **دستورات خطرناک** باشد، باید **خطای** `ValueError` بدهد. در پیادهسازی، این متد با استفاده از **تجزیهی** *AST* عمل میکند و هر گرهی عبارت *(مثل عملیات باینری، یونیاری، فراخوانی تابع یا ثابت)* را **به صورت کنترلشده ارزیابی میکند** تا علاوه بر دقت عددی، امنیت و پیشبینیپذیری کامل را نیز **تضمین** کند. همچنین در ترکیب با دیگر بخشهای **باقرآکادمی** مانند `PlaceholderProcessor` و `Renderer`، **متد** `eval` **پایهی محاسبات پارامتری و جایگذاری مقادیر در قالب سوالات** را تشکیل خواهد داد.
+ **توجه داشته باشید** که در پیادهسازی این سوال شما **به هیچ عنوان مجاز به استفاده از تابع** `eval` پایتونی **نیستید** و استفاده از این مورد به صورت خودکار، **نمره صفر برای گل پاسخ ارائه شده لحاظ خواهد کرد.**
```python core/evaluator.py python
import ast
import operator as op
import math
from typing import Any, Dict, Optional
from utils.config_loader import ConfigLoader
config = ConfigLoader()
decimal_places: Optional[int] = config.get("decimal_places", 3)
enabled_functions = config.get(
"math_functions",
[
"sqrt","sin","cos","tan","asin","acos","atan",
"log","log10","exp","ceil","floor","abs","round"
]
)
OPERATORS = {
ast.Add: op.add,
ast.Sub: op.sub,
ast.Mult: op.mul,
ast.Div: op.truediv,
ast.FloorDiv: op.floordiv,
ast.Mod: op.mod,
ast.Pow: op.pow,
ast.USub: op.neg,
ast.UAdd: op.pos,
}
builtins_dict = __builtins__ if isinstance(__builtins__, dict) else __builtins__.__dict__
SAFE_FUNCTIONS: Dict[str, Any] = {}
for name in enabled_functions:
if name in ("abs", "round"):
SAFE_FUNCTIONS[name] = builtins_dict[name]
else:
SAFE_FUNCTIONS[name] = getattr(math, name)
CONSTANTS = {"pi": math.pi, "e": math.e}
class SafeEvaluator:
def __init__(self, vars: Optional[Dict[str, Any]] = None):
pass
def eval(self, expression: str) -> Any:
pass
```
برای درک نقش `SafeEvaluator` و **متد** `eval`، میتوان دو مثال زیر را در نظر گرفت. **در مثال اول،** یک **عبارت تو در تو از توابع ریاضی** با استفاده از`sqrt`, `abs`, `log`, `exp` داریم:
```python core/evaluator.py python
ev = SafeEvaluator(vars={'x': 2, 'y': 3})
expr = 'sqrt(abs(log(exp((x + y) ** 2))))'
result = ev.eval(expr)
# sqrt((2 + 3) ** 2) = 5
```
+ در اینجا، `eval` باید **توانایی پردازش دقیق عملیات تو در تو** را داشته باشد و **مقادیر متغیرها** (`x=2`, `y=3`) را جایگذاری کند. **ترتیب اعمال تابعها** و **عملیات ریاضی** رعایت میشود تا نتیجهی نهایی با مقدار مورد انتظار مطابق باشد.
در مثال دوم، **یک عبارت ترکیبی از عملگرهای مختلف داریم که شامل جمع، ضرب، توان، تفریق و تقسیم** است:
```python core/evaluator.py python
ev = SafeEvaluator(vars={'a': 2, 'b': 3, 'c': 4})
expr = 'a + b * c ** 2 - (b + c) / a'
result = ev.eval(expr)
# 2 + 3 * 4**2 - (3 + 4)/2 = 46.5
```
+ در اینجا **متد** `eval` **باید تقدم عملگرها را رعایت کند** و محاسبات ترکیبی را به دقت انجام دهد. این مثال نشان میدهد که `SafeEvaluator` باید قادر باشد تا عبارات پیچیدهی عددی را بهدرستی محاسبه کند.
</details>
<details class="blue">
<summary>
**پیاده سازی کلاس** `PlaceholderProcessor` **از فایل** `placeholder.py`
</summary>
**کلاس** `PlaceholderProcessor` برای **پردازش متنهایی طراحی شده است** که شامل *placeholderهای* **محاسباتی به شکل** `{{ ... }}` هستند و **هدف آن جایگذاری مقادیر محاسبهشده بهطور در متن است.** این کلاس هنگام ساخت، یک `SafeEvaluator` دریافت میکند تا هر بار که نیاز به محاسبهی عبارتها باشد، **یک نمونه امن و مستقل ایجاد شود** و **هیچ تداخل یا تغییر ناخواستهای در مقادیر رخ ندهد.**
**متد** `process` **متن ورودی را بررسی میکند** و **تمام بخشهایی که با الگوی** `{{...}}` همخوانی دارند را **استخراج** میکند. سپس برای هر *placeholder،* **متغیرهای دادهشده را جایگذاری کرده** و **عبارت را با استفاده از** `SafeEvaluator.eval` **محاسبه میکند.** اگر **هنگام محاسبات ریاضی،** خطایی رخ دهد یا عبارت شامل متغیر یا تابع **ناشناخته** باشد، **کلاس به صورت امن** *placeholder* را **بدون تغییر باقی میگذارد** و **از ایجاد خطا جلوگیری میکند.** در نهایت، متن خروجی شامل همهی *placeholderهای* **جایگزینشده با مقادیر محاسبهشده است.**
```python core/placeholder.py python
from .evaluator import SafeEvaluator
class PlaceholderProcessor:
def __init__(self, evaluator_factory):
pass
def process(self, text: str, vars: Dict[str, float]) -> str:
pass
```
+ **تابع** `process` از **کلاس** `PlaceholderProcessor` **مسئول پردازش متنهایی است** که شامل *placeholder* یا **عبارتهای محاسباتی در قالب** `{{ ... }}` هستند و **با مقادیر متغیرها جایگذاری میشوند.**
بهعنوان مثال، اگر متن به شکل زیر باشد:
```python core/placeholder.py python
pp = PlaceholderProcessor(lambda: SafeEvaluator(vars={}))
text = "Sum = {{x + y}}"
result = pp.process(text, {'x': 2, 'y': 3})
# result باید برابر با "Sum = 5" باشد
```
+ در این حالت، `process` ** حاصل عبارت داخل** `{{x + y}}` را پیدا میکند، **مقادیر متغیرها** (`x=2`, `y=3`) را **جایگذاری** میکند و با استفاده از `SafeEvaluator.eval` **محاسبه** میکند. **نتیجهی عددی به رشته تبدیل شده و در متن اصلی جایگزین میشود.**
مثال دیگر که شامل توابع ریاضی و ترکیبها است:
```python core/placeholder.py python
text = "Value={{ sqrt(x**2 + y**2) + log(z) }}"
result = pp.process(text, {'x': 3, 'y': 4, 'z': math.e})
# result باید برابر با "Value=6.0" باشد
```
+ در اینجا `process` قادر است **عبارات پیچیده و تو در تو** را پردازش کند و مقادیر دقیق را جایگزین کند. اگر هرگونه **خطا** یا **عبارت غیرقابل ارزیابی وجود داشته باشد،** متن اصلی بدون تغییر حفظ میشود، یعنی *placeholder* باقی میماند.
به طور خلاصه، `PlaceholderProcessor` **پل بین دادههای متغیر** و **مانفیست سوال** شده است و تضمین میکند که همهی *placeholderها* با **مقادیر محاسبهشده جایگزین شوند.**
</details>
<details class="blue">
<summary>
**پیاده سازی کلاس** `Renderer` **از فایل** `placeholder.py`
</summary>
**کلاس** `Renderer` **مسئول تبدیل یک سوال با قالب متنی** و **مقادیر متغیرها** به یک **خروجی آماده** است که شامل **متن سوال، گزینهها و پاسخ** محاسبهشده میشود و هدف آن این است که تمام *placeholderها* به صورت با مقادیر مناسب جایگزین شوند. هنگام مقداردهی اولیه، `Renderer` **یک نمونه از** `PlaceholderProcessor` **به همراه نمونهی** `SafeEvaluator` ایجاد میکند تا تمام پردازشهای ریاضی و جایگذاریها به صورت امن و قابل پیشبینی انجام شوند و **هیچ تغییر ناخواستهای روی مقادیر متغیرها رخ ندهد.**
**متد** `render` ابتدا **متن اصلی سوال** یا `stem` را پردازش میکند و **تمامی** *placeholderها* را با مقادیر محاسبهشده جایگزین میکند. سپس **اگر سوال شامل گزینهها باشد،** هر گزینه نیز با همان مقادیر متغیرها پردازش میشود تا **تمامی توابع** و **عبارات ریاضی داخل گزینهها** به شکل صحیح جایگزین شوند. در نهایت، **اگر سوال شامل پاسخ باشد،** `render` آن را **پردازش** میکند و **تلاش** میکند تا مقادیر عددی را با **تعداد رقمهای اعشاری مشخصشده و واحد مناسب نمایش دهد.** اگر مقدار قابل تبدیل به عدد نباشد، به همان شکل متنی نمایش داده میشود و **هیچ خطایی ایجاد نمیشود.**
```python core/renderer.py python
from typing import Dict
from .placeholder import PlaceholderProcessor
from .evaluator import SafeEvaluator
from utils.config_loader import ConfigLoader
config = ConfigLoader()
DECIMAL_PLACES = config.get("decimal_places", 3)
DEFAULT_UNITS = config.get("default_units", {})
class Renderer:
def __init__(self):
pass
def render(self, question, vars: Dict[str, float]) -> Dict[str, str]:
pass
```
**کلاس** `Renderer` مسئول **تبدیل یک سوال** با **مانیفستهای دارای** *placeholder* و **مقادیر متغیر به خروجی نهایی است** که شامل `stem`، **گزینهها** و **پاسخ پردازششده میشود** و تمامی *placeholderها* را با **مقادیر واقعی جایگزین میکند.** به عبارت دیگر، **این کلاس متن خام سوال و گزینهها را دریافت کرده و با استفاده از** `PlaceholderProcessor` و `SafeEvaluator` **مقادیر متغیرها و محاسبات ریاضی داخل** *placeholderها* **را محاسبه و در متن جایگذاری میکند.**
بهعنوان مثال، **اگر یک سوال داشته باشیم با** stem `"Compute {{x}} + {{y}}"` و **گزینههای** `["Sum={{x+y}}", "Double={{x*2}}"]` و **مقادیر متغیرهای** `{'x': 3, 'y': 5}`، **فراخوانی** `Renderer().render(question, {'x': 3, 'y': 5})` **خروجی زیر را تولید میکند:**
```json question.json json
{
"stem": "Compute 3 + 5",
"options": ["Sum=8", "Double=6"]
}
```
+ در این مثال، تمامی *placeholderها* با مقادیر محاسبهشده **جایگزین** شدهاند و بدنه سوال جدید به شکل درست ارائه شده است. همچنین، اگر سوال دارای پاسخ عددی یا متنی باشد، `Renderer` **پاسخ را با تعداد رقمهای اعشار مشخصشده و واحد مناسب قالببندی میکند.** اگر پاسخ یک عبارت غیرقابل تبدیل به عدد باشد، **به همان صورت رشتهای** باقی میماند.
</details>
<details class="blue">
<summary>
**پیاده سازی کلاس** `VariableResolver` **از فایل** `variable_resolver.py`
</summary>
**کلاس** `VariableResolver` **مسئول مدیریت** و **تولید مقادیر تصادفی برای متغیرها** در **محدودههای تعریف شده** است و به گونهای طراحی شده که خروجیها [**دترمنیستیک** *(Deterministic)*](https://en.wikipedia.org/wiki/Deterministic_system) باشند زمانی که یک `seed` مشخص یا `seed` سراسری در پیکربندی تعریف شده باشد. این کلاس، **مقادیر پیشفرض بارگذاری شده از فایل پیکربندی** را با **محدودههای ارائه شده توسط کاربر ترکیب میکند** و برای **هر متغیر** یک **مقدار تصادفی** تولید میکند که در بازه مشخص شده قرار دارد. این طراحی اجازه میدهد که مقادیر تولید شده به صورت **قابل پیشبینی** و **هماهنگ** با نیازها و اجرای برنامه باشند، **حتی وقتی محدودههای متغیرها متنوع یا زیاد باشند.**
**متد** `resolve` **قابلیت تنظیم** `seed` **محلی** برای **تولید مقادیر قابل تکرار را دارد** و این قابلیت باعث میشود هر بار که **همان** `seed` استفاده شود، **خروجیهای تولید شده دقیقاً یکسان باشند.** اگر `seed` **محلی** مشخص **نشده** باشد، **کلاس به طور خودکار از** `seed` سراسری تعریف شده در پیکربندی استفاده میکند **تا همچنان دترمنیستیک بودن حفظ شود.**
در هنگام تولید مقادیر، **هر مقدار با استفاده از** `round` و **تعداد رقمهای اعشار مشخص شده در پیکربندی گرد** میشود تا **دقت عددی** و **قالببندی** عدد حفظ شود. این مسئله برای اطمینان از اینکه مقادیر تولید شده در محاسبات بعدی با دقت معین استفاده شوند **بسیار مهم است** و باعث میشود نتایج محاسباتی در تستها یا رندرینگ سوالات **دقیق** و **یکسان** باقی بمانند. به عنوان مثال، **اگر محدوده متغیرها به شکل** `{'x': (1, 5), 'y': (10, 20)}` باشد و `seed` برابر با `42` تنظیم شود، فراخوانی `VariableResolver({'x': (1,5), 'y':(10,20)}).resolve(seed=42)` **مقدار مشخص و تکرارپذیر مثل** `{'x': 3.14, 'y': 16.27}` تولید میکند و هر بار با همان `seed`، **همان مقادیر بازمیگردند.**
```python core/variable_resolver.py python
import random
from typing import Dict, Any, Optional, Tuple
from utils.config_loader import ConfigLoader
config = ConfigLoader()
GLOBAL_SEED = config.get("random_seed", None)
DECIMAL_PLACES = config.get("decimal_places", 3)
CONFIG_RANGES = config.get("variable_ranges", {})
class VariableResolver:
def __init__(self, ranges: Optional[Dict[str, Tuple[float, float]]] = None):
pass
def resolve(self, seed: Optional[int] = None) -> Dict[str, Any]:
pass
```
+ بهعنوان مثال، فرض کنید **یک سوال با** `stem` و **گزینهها** داریم که شامل *placeholderهای* ریاضی است:
```python core/variable_resolver.py python
class DummyQuestion:
stem = "Compute {{x}} + {{y}}"
options = ["Sum={{x+y}}", "Double={{x*2}}"]
r = Renderer()
rendered = r.render(DummyQuestion(), {'x': 2, 'y': 3})
# rendered['stem'] باید برابر "Compute 2 + 3" باشد
# rendered['options'] باید برابر ["Sum=5", "Double=4"] باشد
```
+ در این مثال، `Renderer` ابتدا *placeholderهای* `stem` را **پردازش** میکند و **مقادیر** `x` و `y` را جایگزین میکند. سپس **گزینهها** را پردازش میکند، به طوری که **محاسبات داخلی هر گزینه** (`x+y` و `x*2`) انجام شده و **خروجی نهایی جایگزین متن** *placeholder* میشود. اگر پاسخ نهایی دارای واحد یا نیاز به گرد کردن باشد، کلاس بهطور خودکار آن را مدیریت میکند.
به طور خلاصه، `Renderer` **مسئول یکپارچهسازی** و **پردازش تمام متون** و **دادههای سوال** است، به طوری که خروجی *دترمنیستیک، دقیق و آماده استفاده در نمایش یا ارزیابی* باشد.
</details>
</details>
<details class="green">
<summary>
**پیادهسازی پوشه** `models`
</summary>
<details class="grey">
<summary>
**توضیحات کلاس** `BaseQuestion` **از فایل** `base_question.py`
</summary>
**کلاس** `BaseQuestion` به عنوان یک **کلاس انتزاعی** طراحی شده تا چارچوب و رابطی مشترک برای تمامی انواع سوالات را فراهم کند. این کلاس شامل **متغیرهای پایهای مانند** `template` برای **نگهداری ساختار سوال** و `variable_spec` برای **تعریف محدوده** یا **نوع متغیرهای استفاده شده** در سوال است. **متد** `to_dict` **امکان تبدیل سوال به یک دیکشنری استاندارد** را فراهم میکند تا بتوان آن را ذخیره یا ارسال کرد و **متد** `generate_variables` **با استفاده از کلاس** `VariableResolver` م**قادیر متغیرهای مورد نیاز برای تولید یک نمونه دترمنیستیک از سوال را فراهم میکند.**
بخش مهم دیگر، **متدهای انتزاعی** `render_variants` و `validate_template` هستند که در **کلاس پایه** تعریف شدهاند **اما پیادهسازی آنها برعهده کلاسهای فرزند است.** `render_variants` وظیفه تولید یک یا چند نسخه از سوال با مقادیر متفاوت متغیرها را بر اساس `variable_spec` دارد، در حالی که `validate_template` **مسئول بررسی صحت** و **کامل بودن** قالب سوال است. **کلاسهای فرزند** با **ارثبری** از `BaseQuestion` موظف هستند **این دو متد را پیادهسازی کنند** تا مطمئن شویم که **هر نوع سوال جدید قابلیت تولید نمونهها** و **اعتبارسنجی مانیفست را به طور دترمنیستیک و استاندارد دارد.**
```python base_question.py python
from typing import Dict, Any, List
from abc import ABC, abstractmethod
from core.variable_resolver import VariableResolver
class BaseQuestion(ABC):
def __init__(self, template: Dict[str, Any], variable_spec: Dict[str, Dict[str, Any]]):
self.template = template
self.variable_spec = variable_spec
@abstractmethod
def render_variants(self, num_variants: int = 1) -> List[Dict[str, Any]]:
pass
@abstractmethod
def validate_template(self) -> None:
pass
def to_dict(self) -> Dict[str, Any]:
return {
'template': self.template,
'variable_spec': self.variable_spec
}
def generate_variables(self) -> Dict[str, Any]:
resolver = VariableResolver(self.variable_spec)
return resolver.resolve()
```
</details>
<details class="grey">
<summary>
**پیاده سازی کلاس** `MultipleChoiceQuestion` **از فایل** `mcq.py`
</summary>
**کلاس** `MultipleChoiceQuestion` **یک پیادهسازی خاص از کلاس انتزاعی** `BaseQuestion` است که **مخصوص سوالات چندگزینهای** طراحی شده است. **متد** `validate_template` تضمین میکند که **قالب سوال شامل حداقل یک** `stem` و **یک لیست** `options` باشد و **در صورت نبود** یا **نادرستی** این بخشها **خطا** صادر میکند. این **متد** در **کلاسهای فرزند** باید همیشه پیادهسازی شود تا قبل از تولید نمونههای سوال، اعتبار قالب بررسی شود و **از تولید خروجی نادرست جلوگیری گردد.**
```python models/mcq.python python
from .base_question import BaseQuestion
class MultipleChoiceQuestion(BaseQuestion):
pass
```
**متد** `render_variants` **مسئول تولید یک یا چند نسخه از سوال با مقادیر متفاوت متغیرها است.** در این متد ابتدا قالب اعتبارسنجی میشود، سپس با استفاده از `VariableResolver` **مقادیر متغیرها تولید و با** `PlaceholderProcessor` در **متن** `stem` و **گزینهها** جایگذاری میشوند. **خروجی یک لیست از دیکشنریهاست که شامل** `stem`، `options` **و مقادیر متغیرهای استفاده شده است.**
به عنوان مثال، اگر **مانیفست سوال** به شکل زیر باشد:
```python models/mcq.py python
template = {
'stem': "What is {{a}} + {{b}}?",
'options': ["{{a+b}}", "{{a*b}}", "{{a-b}}"]
}
variable_spec = {'a': (1, 3), 'b': (2, 4)}
mcq = MultipleChoiceQuestion(template, variable_spec)
variants = mcq.render_variants(num_variants=2)
```
+ در این مثال، `render_variants` **دو نسخه از سوال تولید میکند،** هر نسخه دارای `stem` و **گزینههای جایگذاریشده با مقادیر واقعی متغیرها** خواهد بود.
</details>
<details class="grey">
<summary>
**پیاده سازی کلاس** `NumericRangeQuestion` **از فایل** `numeric_range.py`
</summary>
**کلاس** `NumericRangeQuestion` یک **پیادهسازی از کلاس انتزاعی** `BaseQuestion` است که برای **سوالاتی با پاسخ عددی در بازهای مشخص** طراحی شده است. **متد** `validate_template` بررسی میکند که **قالب سوال شامل حداقل یک** `stem` و **یک** `answer` باشد و **در صورت نبود یا نادرستی این بخشها خطا صادر میکند**. این متد تضمین میکند که قبل از تولید نسخههای سوال، قالب اعتبارسنجی شده و **از تولید خروجی نادرست جلوگیری شود.**
```python models/numeric_range.py python
from .base_question import BaseQuestion
class NumericRangeQuestion(BaseQuestion):
pass
```
**متد** `render_variants` **وظیفه تولید یک** یا **چند نسخه دترمنیستیک** از سوال را بر عهده دارد. در این متد ابتدا قالب اعتبارسنجی میشود، سپس با استفاده از `VariableResolver` **مقادیر متغیرها تولید و با** `PlaceholderProcessor` در **متن** `stem` و **مقدار** `answer` جایگذاری میشوند. اگر جایگذاری **مقدار** `answer` به هر دلیلی **ناموفق** باشد، مقدار **پیشفرض** `answer` استفاده میشود. **خروجی یک لیست از دیکشنریهاست که شامل** `stem`، `answer`، `tolerance` **و مقادیر متغیرهای استفاده شده است.**
به عنوان مثال، اگر **مانیفست سوال** به شکل زیر باشد:
```python models/numeric_range.py python
template = {
'stem': "Compute {{x}} + {{y}}",
'answer': "{{x + y}}",
'tolerance': 0.01
}
variable_spec = {'x': (1, 5), 'y': (2, 6)}
num_question = NumericRangeQuestion(template, variable_spec)
variants = num_question.render_variants(num_variants=2)
```
+ در این مثال، `render_variants` **دو نسخه از سوال تولید میکند،** هر نسخه **شامل** `stem` جایگذاریشده با **مقادیر واقعی متغیرها** و `answer` **محاسبهشده** با همان مقادیر خواهد بود و میتوان از آن برای تولید سوالات دترمنیستیک با پاسخ عددی و محدودهی مجاز استفاده کرد.
</details>
<details class="grey">
<summary>
**پیاده سازی کلاس** `ShortAnswerQuestion` **از فایل** `short_answer.py`
</summary>
**کلاس** `ShortAnswerQuestion` یک **پیادهسازی از کلاس انتزاعی** `BaseQuestion` است که برای **سوالاتی با پاسخ کوتاه طراحی شده** و میتواند هم پاسخهای عددی و هم متنی را مدیریت کند. **متد** `validate_template` ابتدا بررسی میکند که **قالب سوال شامل حداقل یک** `stem` و **یک** `answer` باشد و در صورت **نبود** یا **نادرستی** این بخشها، **خطا** صادر میکند. این مرحله اعتبارسنجی تضمین میکند که قبل از تولید نسخههای سوال، قالب درست باشد و **از تولید خروجی نامعتبر جلوگیری شود.**
```python models/short_answer.py python
from .base_question import BaseQuestion
class ShortAnswerQuestion(BaseQuestion):
pass
```
**متد** `render_variants` **وظیفه تولید یک یا چند نسخه دترمنیستیک از سوال را بر عهده دارد.** در این متد ابتدا قالب اعتبارسنجی میشود، سپس با استفاده از `VariableResolver` مقادیر متغیرها تولید میشوند و با `PlaceholderProcessor` در **متن** `stem` و **مقدار** `answer` جایگذاری میشوند. اگر پاسخ قابل تبدیل به عدد باشد، از `RegexGenerator.numeric_regex` **برای تولید یک الگوی عددی استفاده میشود** و **در غیر این صورت از** `RegexGenerator.text_regex` برای تولید الگوی متنی بهره گرفته میشود. خروجی یک لیست از دیکشنریهاست که شامل `stem` جایگذاریشده، `answer` محاسبهشده یا متنی، `regex` **برای بررسی پاسخ و مقادیر متغیرهای استفاده شده است.**
به عنوان مثال، اگر **مانیفست سوال** به شکل زیر باشد:
```python models/short_answer.py python
template = {
'stem': "Enter the sum of {{x}} and {{y}}",
'answer': "{{x + y}}"
}
variable_spec = {'x': (1, 5), 'y': (2, 6)}
sa_question = ShortAnswerQuestion(template, variable_spec)
variants = sa_question.render_variants(num_variants=2)
```
+ در این مثال، `render_variants` **دو نسخه از سوال تولید میکند،** هر نسخه شامل `stem` **جایگذاریشده** با مقادیر واقعی متغیرها و `answer` محاسبهشده است. اگر پاسخ عددی باشد، یک *regex* مناسب **برای بررسی پاسخهای عددی ایجاد میشود** و اگر پاسخ متنی باشد، *regex* **برای مقایسهی متن به کار میرود.** این مکانیزم اطمینان میدهد که سوالات کوتاه پاسخ هم **دترمنیستیک** و **هم قابل اعتبارسنجی باشند.**
</details>
<details class="grey">
<summary>
**پیاده سازی کلاس** `TrueFalseQuestion` **از فایل** `true_false.py`
</summary>
**کلاس** `TrueFalseQuestion` **پیادهسازی ویژهای از** `BaseQuestion` است که برای سوالات **درست/نادرست** طراحی شده و میتواند **مقادیر متغیرها** را در متن سوال جایگذاری کند. **متد** `validate_template` بررسی میکند که قالب شامل **حداقل یک** `stem` و **یک** `answer` باشد و در صورت نبود آنها **خطا** صادر میکند. این اعتبارسنجی تضمین میکند که قبل از تولید نسخههای سوال، قالب به صورت دترمنیستیک معتبر باشد و **از تولید خروجی نامعتبر جلوگیری شود.**
```python models/true_false.py python
from .base_question import BaseQuestion
class TrueFalseQuestion(BaseQuestion):
pass
```
**متد** `render_variants` **وظیفه تولید یک یا چند نسخه از سوال را بر اساس مقادیر متغیرها بر عهده دارد.** ابتدا قالب اعتبارسنجی میشود، سپس با `VariableResolver` **مقادیر متغیرها تولید میشوند** و با `PlaceholderProcessor` در **متن** `stem` جایگذاری میشوند. **پاسخ درست/نادرست** (`answer`) **به همان شکل از قالب گرفته میشود** و در خروجی قرار میگیرد. در نهایت، خروجی یک لیست از دیکشنریهاست که **شامل** `stem` جایگذاریشده، **پاسخ** و **مقادیر متغیرهاست** تا سوالات تولید شده قابل استفاده و بررسی باشند.
به عنوان مثال، اگر **مانیفست سوال** به شکل زیر باشد:
```python models/true_false.py python
template = {
'stem': "Is {{x}} greater than {{y}}?",
'answer': True
}
variable_spec = {'x': (1, 10), 'y': (1, 10)}
tf_question = TrueFalseQuestion(template, variable_spec)
variants = tf_question.render_variants(num_variants=2)
```
+ در این مثال، `render_variants` **دو نسخه از سوال تولید میکند،** هر نسخه شامل **متن سوال جایگذاریشده** با مقادیر واقعی متغیرها و **پاسخ درست/نادرست** مشخص شده در قالب است. این روش اطمینان میدهد که **سوالات درست/نادرست دترمنیستیک باشند** و **مقادیر متغیرها به درستی در متن سوال منعکس شوند.**
</details>
<details class="grey">
<summary>
**پیاده سازی کلاس** `MatchingQuestion` **از فایل** `matching.py`
</summary>
**کلاس** `MatchingQuestion` **یک پیادهسازی از** `BaseQuestion` است که برای **سوالات تطبیقی طراحی شده** و امکان جایگذاری **مقادیر متغیرها در متن سوال** و **جفتهای تطبیقی را فراهم میکند.** متد `validate_template` بررسی میکند که قالب شامل حداقل **یک** `stem` و **یک لیست** `pairs` باشد و در صورت نبود آنها **خطا** صادر میکند. این اطمینان میدهد که قالب دترمنیستیک و معتبر است و قبل از تولید نسخههای سوال **هیچ داده ناقصی وارد فرآیند تولید نمیشود.**
```python models/matching.py python
from .base_question import BaseQuestion
class MatchingQuestion(BaseQuestion):
pass
```
**متد** `render_variants` **وظیفه تولید یک یا چند نسخه از سوال تطبیقی را بر اساس مقادیر متغیرها بر عهده دارد.** ابتدا قالب اعتبارسنجی میشود، سپس با استفاده از `VariableResolver` **مقادیر متغیرها تولید میشوند و با** `PlaceholderProcessor` در **متن** `stem` و **در هر جفت** `left` و `right` جایگذاری میشوند. خروجی یک لیست از دیکشنریهاست که شامل *متن جایگذاریشده، جفتهای تطبیقی جایگذاریشده و مقادیر متغیرهاست* تا نسخههای تولید شده قابل استفاده و قابل بررسی باشند.
به عنوان مثال، اگر **مانیفست سوال** به شکل زیر باشد:
```python models/matching.py python
template = {
'stem': "Match the capitals with their countries:",
'pairs': [
{"left": "{{country1}}", "right": "{{capital1}}"},
{"left": "{{country2}}", "right": "{{capital2}}"}
]
}
variable_spec = {
'country1': ('France', 'France'),
'capital1': ('Paris', 'Paris'),
'country2': ('Germany', 'Germany'),
'capital2': ('Berlin', 'Berlin')
}
matching_question = MatchingQuestion(template, variable_spec)
variants = matching_question.render_variants(num_variants=1)
```
+ در این مثال، `render_variants` یک نسخه از سوال تولید میکند که **متن سوال** و **همه جفتها با مقادیر واقعی متغیرها جایگذاری شدهاند.** این روش تضمین میکند که سوالات تطبیقی **دترمنیستیک** باشند و تمامی *placeholderها* **به درستی با مقادیر مشخص شده جایگزین شوند.**
</details>
<details class="grey">
<summary>
**پیاده سازی کلاس** `QuestionBank` **از فایل** `question_bank.py`
</summary>
**کلاس** `QuestionBank` **مسئول مدیریت مجموعهای از قالبهای سوال است** و **وظیفه آن بارگذاری فایلهای** *JSON* **شامل سوالات مختلف** و **نگهداری آنها در یک دیکشنری داخلی است.** هر **فایل** *JSON* باید شامل **نوع سوال** (`type`)، **شناسه یکتا** (`id`)، **قالب سوال** (`template`) و **مشخصات متغیره**ا (`variables`) باشد. هنگام بارگذاری، `QuestionBank` **بر اساس نوع سوال کلاس مناسب را انتخاب میکند** و نمونهای از آن کلاس را با **قالب** و **متغیرهای** مشخصشده ایجاد میکند. قالبهای با نوع **ناشناخته** یا **بدون شناسه** نادیده گرفته میشوند و **بارگذاری فقط شامل فایلهای** *JSON* معتبر است.
```python models/question_bank.py python
class QuestionBank:
pass
```
پس از بارگذاری، **تمامی سوالات در دیکشنری** `self.templates` نگهداری میشوند تا **دسترسی سریع** به آنها ممکن باشد. **متد** `get` **امکان دسترسی به یک سوال مشخص بر اساس شناسه آن را فراهم میکند** و در صورت نبود شناسه موردنظر، **مقدار** `None` برمیگرداند. این ساختار اطمینان میدهد که تمام قالبهای معتبر با نوع مشخص و شناسه یکتا در بانک سوال قابل دسترس باشند و هرگونه خطا یا داده ناقص هنگام بارگذاری مدیریت شود.
به عنوان مثال، فرض کنید مجموعهای از فایلهای *JSON* در مسیر `questions/` داریم و میخواهیم سوال با شناسه `Q101` را بارگذاری کنیم:
```python models/question_bank.py py
qb = QuestionBank("questions/")
question = qb.get("Q101")
if question:
variants = question.render_variants(num_variants=3)
for v in variants:
print(v['stem'])
```
+ در این مثال، `QuestionBank` **ابتدا فایلها را بررسی میکند، قالبها و متغیرها را ایجاد میکند،** سپس با **فراخوانی** `get` سوال مشخص را برمیگرداند و امکان تولید نسخههای متعدد از هر سوال با مقادیر متغیر مشخص فراهم باشد.
</details>
</details>
# **زیرمسئلهها**
سیستم داوری برای این سوال به **زیرمسئلههای** زیر برای نمرهدهی تقسیمبندی شده است که میتوانید **امتیاز** مربوط به هر کدام را در جدول زیر مشاهده کنید. **زیرمسئلههای** این جدول **ابتدا بر اساس اولویت و پیشنیازی پیادهسازی** و سپس **بر اساس امتیاز** آنها مرتبسازی شدهاند. **لذا پیشنهاد میشود در پیادهسازی از زیرمسئلهی ابتدایی آغاز کنید.**
| **زیرمسئله** | **امتیاز** |
| ----------------------------- | ------ |
| **پیادهسازی بخش** `core` | `203` |
| **پیادهسازی بخش** `models` | `147` |
# **آنچه باید آپلود کنید**
+ **توجه**: پس از پیادهسازی موارد خواسته شده، **کل فایلهای پروژه** را زیپ کرده و ارسال کنید.
+ **توجه**: شما مجاز به **افزودن فایل جدیدی** در این ساختار **نیستید** و تنها باید تغییرات را در فایلهای موجود اعمال کنید.
+ **توجه**: که نام فایل _Zip_ اهمیتی **ندارد**.
باقرآکادمی
> سالها پیش، **باقر، ممجواد و مصطفی** سه **دانشجوی جوان مهندسی کامپیوتر** دانشگاه صنعتی شریف، **آغازگری** بودند بر **آغازگرانی** که بعدها **کوئرا** *(Quera)* نام گرفت...
اکنون، **بعد از سالها تجربه و پیشرفت و کوئراگری،** این سه **آغازگر،** که **آغازگرِ آغازگران کوئرا** بودند، تصمیم گرفتند تا همزمان با شروع سری جدید [**#المپیکفناوری پردیس**](https://quera.org/events/techolympics-0407) با آغازگری جدیدی، **ویژگی جدید مدیریت نسخهی کوئرا** *( Quera's Version Control)* را برای درسنامهها و سوالات توسعه دهند. **این ویژگی جدید در کوئرا،** باعث میشود تا برخلاف گذشته، هر درسنامه بتواند **چندین نسخهی مختلف** داشته باشد و **نسخهی فعالی** *(Active Version)* برای کاربران نمایش داده شود، سیستم مدیریت نسخه کوئرا به گونهای طراحی میشود که **هویت ایجادکنندهی هر نسخه** نیز همانند **طراحان و مربیان کالجهای کوئرا کالج،** ثبت و نمایش داده شود تا مسیر تغییرات **شفاف** شود و سابقهی تمامی مشارکتکنندگان در توسعهی محتواها، سوالات و درسنامهها در کوئرا به خوبی حفظ شود.
نسخهبندی درسنامهها و سوالات، قرار است تا بر اساس استاندارد **_SemVer_ (Semantic Versioning یا نسخهبندی معنایی)** انجام میشود و **فرمت** `MAJOR.MINOR.PATCH` برای مدیریت آنها وجود داشته باشد. اولین نسخهی هر درسنامه و سوال با شمارهٔ `0.1.0` آغاز میشود. هنگام ایجاد تغییرات جدید، مشارکتکنندگان میتوانند نوع افزایش نسخه را مشخص کند: افزایش `MAJOR`، `MINOR` یا `PATCH`. کاربارن بعدها هنگام خواندن این سوالات و درسنامهها میتوانند روند تغییرات و مشارکتکنندگان آنها را ببینند و همچنین نسخهی فعال را تغییر داده تا بتوانند نسخه مورد نظر خودشان از آن سوال یا درسنامه را مطالعه کنند. از آنجایی که این سه آغازگر قرار است به زودی و در مجموعه برنامههای استخدامی ترتیب داده شده در فینال مسابقات، سخنرانیهای آغازگرانه داشته باشند، در قالب این سوال از شما میخواهند تا بخشی از سیستم مدیریت نسخه کوئرا را آغازگری کنید!
# **پروژهی اولیه**
برای دانلود پروژهی اولیه روی [این لینک](/contest/assignments/91477/download_problem_initial_project/310246/) کلیک کنید.
<details class="yellow">
<summary>**ساختار فایلها**</summary>
```
release-manager/
├── accounts
│ ├── migrations
│ │ ├── 0001_initial.py
│ │ └── __init__.py
│ ├── templates
│ │ └── accounts
│ │ ├── login.html
│ │ └── signup.html
│ ├── __init__.py
│ ├── apps.py
│ ├── forms.py
│ ├── models.py
│ ├── urls.py
│ └── views.py
├── core
│ ├── forms
│ │ ├── __init__.py
│ │ ├── boundfields.py
│ │ └── renderers.py
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── lms
│ ├── fixtures
│ │ └── data.json
│ ├── migrations
│ │ ├── 0001_initial.py
│ │ └── __init__.py
│ ├── templates
│ │ └── lms
│ │ ├── lesson_confirm_delete.html
│ │ ├── lesson_detail.html
│ │ ├── lesson_form.html
│ │ ├── lesson_list.html
│ │ ├── my_lessons.html
│ │ ├── release_detail.html
│ │ ├── release_form.html
│ │ └── release_list.html
│ ├── __init__.py
│ ├── apps.py
│ ├── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">forms.py</mark>
│ ├── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">mixins.py</mark>
│ ├── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">models.py</mark>
│ ├── urls.py
│ └── views.py
├── static
│ ├── css
│ │ └── markdown.css
│ └── imgs
│ └── quera.png
├── templates
│ └── base.html
├── tests
│ ├── __init__.py
│ └── sample_tests.py
├── utils
│ ├── markdown.py
│ ├── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">models.py</mark>
│ ├── semver.py
│ └── utility.py
├── db.sqlite3
├── manage.py
└── requirements.txt
```
</details>
<details class="grey">
<summary>**راهاندازی پروژه**</summary>
برای اجرای پروژه، باید **پایتون و ابزار** _pip_ را از قبل نصب کرده باشید.
- ابتدا **پروژهی اولیه** را دانلود و از حالت فشرده خارج کنید.
- در پوشهی اصلی پروژه، یک **محیط مجازی پایتون** _(venv)_ ایجاد و فعال کنید:
```bash terminal terminal
python -m venv venv
source venv/bin/activate # در ویندوز: venv\Scripts\activate
```
- دستور زیر را برای **نصب نیازمندیها** در پوشهی اصلی پروژه اجرا کنید:
```bash terminal terminal
pip install -r requirements.txt
```
- برای **اجرای پروژه** *Django* دستور زیر را در مسیر پوشهی اصلی پروژه اجرا کنید:
```bash terminal terminal
python manage.py runserver
```
در صورت اجرای موفق، **یک لینک** در خروجی نمایش داده میشود که میتوانید **آن را در مرورگر باز کنید.**
- برای **اجرای مایگریشنها** و ایجاد جداول پایگاه داده، دستور زیر را اجرا کنید:
```bash terminal terminal
python manage.py migrate
```
- برای **بارگذاری دادههای نمونه** از **فایل** *fixture،* دستور زیر را اجرا کنید:
```bash terminal terminal
python manage.py loaddata data.json
```
</details>
# **جزئیات پروژه**
<details class="blue">
<summary>**فایل `models.py`**</summary>
باید دو مدل **`Lesson` (درسنامه)** و **`Release` (نسخه)** را مطابق زیر پیادهسازی کنید. در ادامه توضیحات مربوط به نحوهی پیادهسازی هر یک از این مدلها آورده شدهاست.
## **مدل درسنامه** (`Lesson`)
هر درسنامه شامل اطلاعاتی از جمله کلید خارجی به نویسندهی آن، رشتهای حاوی آخرین نسخهی فعال درسنامه و فیلدهای تاریخ-زمان برای نگهداری زمان ایجاد و آخرین زمان ویرایش میباشد.
| نام | نوع |
| :--------------: | ------------------------------------------: |
| `author` | کلید خارجی به مدل کاربر |
| `active_version` | رشته با طول حداکثر ۲۰ کاراکتر |
| `created_at` | تاریخ-زمان (ثبت خودکار زمان ایجاد شیء) |
| `updated_at` | تاریخ-زمان (ثبت خودکار زمان آخرین ویرایش) |
+ با حذف کاربر باید تمام درسنامههای مربوط به آن حذف شوند.
+ با استفاده از فیلد `lessons` از طرف مدل `User` باید به توان به درسنامههای مربوط به آن دسترسی پیدا کرد.
+ فیلد `active_version` رشتهای با فرمت `MAJOR.MINOR.PATCH` (سه عدد که با `.` از هم جدا شدند) است و مقدار پیشفرض آن برابر با رشتهی خالی است.
+ ترتیب پیشفرض این مدل بر اساس فیلد `updated_at` بهصورت نزولی است و درسنامههایی که جدیدتر ویرایش شدهاند بالاتر قرار میگیرند.
+ رشتهی نمایشی پیشفرض این مدل به فرمت زیر است:
```
Lesson #<mark title="شناسهی درسنامه">ID</mark> by <mark title="نام کاربری نویسنده" class="green">USERNAME</mark>
```
### **متد** `get_active_release`
اگر مقدار فیلد `active_version` خالی بود، خروجی متد برابر `None` است؛ در غیر اینصورت سه جزء اصلی نسخه را از آن استخراج کرده و شیء مربوطه از مدل نسخه (`Release`) متناظر با آن را برمیگرداند.
```python lms/models.py
def get_active_release(self):
pass
```
### **متد** `set_active_release`
مقدار فیلد `active_version` را با توجه به شیء نسخهی دریافتشده به فرمت `MAJOR.MINOR.PATCH` **بهروزرسانی** کرده و **ذخیره** میکند؛ بهگونهای که زمان آخرین ویرایش (`updated_at`) نیز بهروزرسانی شود.
```python lms/models.py
def set_active_release(self, release: 'Release'):
pass
```
## **مدل نسخه** (`Release`)
کلید اصلی مدل نسخه باید یک **کلید مرکب (Composite Primary Key)** از چهار جزء باشد: `(lesson, major, minor, patch)`.
| نام | نوع |
| :----------: | ----------------------------------------------: |
| `lesson` | ارجاع به `Lesson` |
| `major` | عدد صحیح نامنفی |
| `minor` | عدد صحیح نامنفی |
| `patch` | عدد صحیح نامنفی |
| `label` | رشتهای با حداکثر طول ۲۵۵ |
| `title` | رشتهای با حداکثر طول ۲۵۵ |
| `content` | متن طولانی |
| `color` | رشتهای با حداکثر طول ۷ |
| `created_at` | تاریخ-زمان (ثبت خودکار زمان ایجاد) |
+ با حذف هر درسنامه (`Lesson`) باید نسخههای (`Release`) مرتبط با آن نیز حذف شوند.
+ با استفاده از فیلد `releases` از طرف مدل `Lesson` میتوان به نسخههای مربوط به آن درسنامه دسترسی پیدا کرد.
+ فیلد `content` از محتوای *Markdown* پشتیبانی میکند؛ بنابراین یک متن راهنمای آن برابر `"Markdown content"` است:
+ فیلد `color` بهطور پیشفرض (در صورت خالی بودن) یک رنگ تصادفی هگز با استفاده از تابع `random_hex_color` موجود در فایل`utils/utility.py` میسازد و در خود ذخیره میکند.
+ ترتیب پیشفرض این مدل از بزرگ به کوچک بر اساس *(major, minor, patch)* و سپس زمان ایجاد (`created_at`) است.
+ رشتهی نمایشی پیشفرض این مدل به فرمت زیر است:
```
<mark class="red" title="عنوان نسخه">Title</mark> [<mark class="violet" title="مقدار عددی فیلد major">MAJOR</mark>.<mark class="pink" title="مقدار عددی فیلد minor">MINOR</mark>.<mark class="blue" title="مقدار عددی فیدل patch">PATCH</mark>]
```
### **متد**`to_semver`
این متد، یک نمونهٔ از دیتاکلاس `SemVer` (موجود در فایل از `utils/semver.py`) با دادههای معتبر ساخته و برگردانده میشود که حاوی `(major, minor, patch)` نسخهی فعلی است (از این متد در ویوها استفاده خواهد شد).
```python lms/models.py
def to_semver(self) -> SemVer:
pass
```
### **متد**`version_str`
این متد، رشتهای به فرمت `MAJOR.MINOR.PATCH` و حاوی اطلاعات صحیح را برمیگرداند.
```python lms/models.py
def version_str(self):
pass
```
</details>
<details class="green">
<summary>**فایل `utils/models.py`**</summary>
در این فایل یک چارچوب عمومی برای **حذف نرم** *(Soft Delete)* پیادهسازی میکنیم تا بهجای حذف دائمی رکوردها، زمان حذف آنها را در فیلد `deleted_at` ذخیره کنیم. بدین ترتیب، کوئریهای عادی رکوردهای حذفشده را نمیبینند و در صورت نیاز میتوان آنها را **بازیابی** یا **بهطور دائمی حذف** کرد.
## **کلاس** `SoftDeleteQuerySet`
یک `QuerySet` سفارشی که عملیاتهای حذف یا بازیابی دستهای و فیلترهای کمکی را فراهم میکند.
```python utils/models.py
class SoftDeleteQuerySet(QuerySet):
pass
```
### **متد** `delete`
بهجای حذف رکوردها، مقدار `deleted_at` را برای همهٔ نتایج روی `timezone.now()` بهروزرسانی میکند (حذف نرم کوئریست).
```python
def delete(self):
pass
```
### **متد** `hard_delete`
با فراخوانی این متد باید رکوردها از پایگاهداده به طور کامل با مکانیزم پیشفرض جنگو پاک شوند (حذف دائمی کوئریست).
```python
def hard_delete(self):
pass
```
### **متد** `restore`
فیلد `deleted_at` را برای همهی نتایج `None` میکند (بازیابی کوئریست).
```python
def restore(self):
pass
```
### **متد** `alive`
فقط رکوردهایی که حذف نشدهاند را برمیگرداند (`deleted_at` در آنها `None` است).
```python
def alive(self):
pass
```
### **متد** `dead`
فقط رکوردهای حذفشده را برمیگرداند (دارای مقدار در `deleted_at`).
```python
def dead(self):
pass
```
## **کلاس** `SoftDeleteManager`
یک `Manager` پیشفرض که **همواره رکوردهای حذفنشده** را برمیگرداند و متدهایی برای دسترسی به رکوردهای حذفشده، بازیابی و حذف دائمی فراهم میکند. این منیجر بهصورت پیشفرض با متد `.all()` فقط نتایج حذفنشده را برمیگرداند (`deleted_at` برابر `None` است).
```python utils/models.py
class SoftDeleteManager(models.Manager):
pass
```
### **متد** `with_deleted`
یک کوئریست شامل **همه** رکوردها (موجود و حذفشده) را برمیگرداند.
```python
def with_deleted(self):
pass
```
### **متد** `dead`
یک کوئریست حاوی تنها رکوردهای حذفشده را برمیگرداند.
```python
def dead(self):
pass
```
### **متد** `restore`
بازیابی دستهای همهی رکوردها (روی کوئریست برگرداندهشده توسط `with_deleted()` اعمال میشود).
```python
def restore(self):
pass
```
### **متد** `hard_delete`
با فراخوانی این متد باید رکوردهای انتخاب شده از پایگاهداده به طور کامل با مکانیزم پیشفرض جنگو پاک شوند.
```python
def hard_delete(self):
pass
```
## **کلاس** `SoftDeleteBaseModel`
کلاسی **انتزاعی *(Abstract)*** که فیلد و رفتارهای حذف نرم را به مدلهایی که از آن ارثبری میکنند اضافه میکند.
```python utils/models.py
class SoftDeleteBaseModel(models.Model):
pass
```
### **فیلد** `deleted_at`
این فیلد از نوع `DateTimeField` است و میتواند خالی باشد. وظیفهی آن نگهداری زمان حذف شدن رکورد است.
### **فیلد** `objects`
این فیلد از یک شیء از کلاس `SoftDeleteManager` استفاده میکند و منیجر پیشفرض مدلها است.
### **متد** `delete`
این متد وظیفهی حذف نرمِ شیء را بر عهده دارد. مقداردهی `deleted_at` با مقدار زمان کنونی آپدیت شود.
```python
def delete(self):
pass
```
### **متد** `hard_delete`
این متد وظیفهی حذف واقعی رکورد از پایگاهداده را بر عهده دارد و رکورد موردنظر را به صورت کامل حذف میکند.
```python
def hard_delete(self):
pass
```
### **متد** `restore`
این متد وظیفهی بازیابی شیء را برعهده دارد که با تنظیم `deleted_at` با مقدار `None` و ذخیره آن اینکار را انجام میدهد؛ در نهایت همان شیء بازیابیشده را برمیگرداند.
```python
def restore(self):
pass
```
پس از پیادهسازی این کلاس، هر مدلی که میخواهید حذف نرم داشته باشد، کافی است از `SoftDeleteBaseModel` ارثبری کند. در این حالت، رفتارهای بالا بهصورت خودکار در دسترس خواهند بود.
</details>
<details class="violet">
<summary>**فایل `mixins.py`**</summary>
## میکسین مالکیت (`OwnerRequiredMixin`)
در این فایل یک کلاس `Mixin` با نام `OwnerRequiredMixin` بسازید که فقط به **مالک درسنامه** اجازهی دسترسی بدهد. این میکسینکلاس در ویوهایی که شیء (از نوع `Lesson` یا `Release`) را میخوانند استفاده شدهاست و باید عملیات مربوط به کنترل دسترسی کاربران را بهدرستی انجام دهد.
```python lms/mixins.py
class OwnerRequiredMixin(UserPassesTestMixin):
def test_func(self):
pass
```
+ اگر شیء از نوع **درسنامه *(Lesson)*** باشد، فقط در صورتی اجازهی دسترسی صادر شود که **شناسهی نویسندهی درسنامه** با شناسهٔ کاربر فعلی برابر باشد.
+ اگر شیء از نوع **نسخه *(Release)*** بود، فقط در صورتی اجازهی دسترسی داده شود که **نویسندهی درسنامهی مربوط به آن نسخه** با کاربر فعلی برابر باشد.
+ اگر شیء ورودی از هیچکدام از انواع بالا نبود، نیازی به انجام عملیات اعتبارسنجی نیست.
**نکته:** این میکسین باید با مکانیزم استاندارد مجوزها در جنگو پیادهسازی شود تا در صورت صدق نکردن شرایط بالا، اجازهی دسترسی داده نشود و ریسپانسی با کد وضعیت ۴۰۳ برگردانده شود.
</details>
<details class="pink">
<summary>**فایل `forms.py`**</summary>
در این فایل باید دو عدد فرم با استفاده از `ModelForm` پیادهسازی کنید. متد سازندهی فرمها در پروژهی اولیه قرار داده شده و **نباید** آن را تغییر دهید. سایر بخشهای این فرمها، از جمله تعریف فیلدها و شخصیسازی ویجتهای نمایشی بر عهدهی شماست.
## **فرم** `ReleaseForm`
هدف از این فرم، ساخت نسخهی اولیه است و بدون دخالت کاربر است؛ نسخهی اولیه در ویوها همواره روی `0.1.0` تنظیم میشود. از طرفی تفاوت آن با فرم بعدی در همین مورد است؛ بهطوری که در این فرم نسخه به صورت خودکار مقداردهی میشود اما در فرم دوم، نحوهی افزایش نسخه را کاربر مشخص میکند. بنابراین برای پیادهسازی فرم بعدی، ابتدا باید این فرم را بهدرستی پیادهسازی کرده باشید.
### **فیلد** `title`
+ **نوع فیلد:** ورودی متنی با پاسخ کوتاه
+ **برچسب *(label)*:**
```
عنوان
```
+ **متن *placeholder*:**
```
مثال: معرفی اولیهٔ درسنامه
```
+ **اجباری/اختیاری:** اجباری
+ **پیام خطا:**
پیام خطای خالی بودن:
```
وارد کردن عنوان الزامی است.
```
پیام خطای طول غیرمجاز:
```
عنوان بیش از حد بلند است.
```
### **فیلد** `content`
+ **نوع فیلد/ویجت:** ورودی متنی با پاسخ بلند (`Textarea`)
+ **برچسب *(label)*:**
```
محتوا (Markdown)
```
+ **متن راهنما *(help text)*:**
```
از Markdown برای قالببندی تیترها، کد و فهرستها استفاده کنید.
```
+ **متن *placeholder*:**
```
محتوای نسخه را با Markdown بنویسید…
```
+ **اجباری/اختیاری:** اجباری
+ **پیام خطا:**
پیام خطای نبود مقدار:
```
محتوای نسخه نمیتواند خالی باشد.
```
#### فیلد `color`
+ **نوع فیلد/ویجت:** رنگ به فرمت کد هگزادسیمال (`ColorInput`)
+ **برچسب *(label)*:**
```
رنگ
```
+ **متن راهنما *(help text)*:**
```
یک رنگ هگز مانند #22C55E انتخاب کنید.
```
+ **متن *placeholder*:**
```
محتوای نسخه را با Markdown بنویسید…
```
+ **اجباری/اختیاری:** اختیاری
+ **پیام خطا:**
پیام خطای مقدار نامعتبر:
```
قالب رنگ نامعتبر است (مثلاً #22C55E).
```
#### فیلد `label`
+ **نوع فیلد/ویجت:** ورودی متنی با پاسخ کوتاه
+ **برچسب *(label)*:**
```
برچسب
```
+ **متن راهنما *(help text)*:**
```
نوع تغییرات این نسخه را مشخص کنید (feature، fix یا breaking).
```
+ **متن *placeholder*:**
```
مثال: feature / fix / breaking
```
+ **اجباری/اختیاری:** اجباری
+ **پیام خطا:**
پیام خطای نبود مقدار:
```
برچسب را وارد کنید (مثلاً feature یا fix).
```
پیام طول زیاد:
```
برچسب بیش از حد بلند است.
```
### **فیلد** `make_active`
فیلد جدیدی که خودتان باید به فرم موردنظر اضافه کنید و جزء فیلدهای مدل `Release` نیست.
+ **نوع فیلد/ویجت:** چکباکس (`BooleanField`)
+ **برچسب *(label)*:**
```
فعالسازی پس از ذخیره؟
```
+ **متن راهنما *(help text)*:**
```
پس از ذخیره، این نسخه بهعنوان نسخهٔ فعال نمایش داده میشود.
```
+ **اجباری/اختیاری:** اجباری
+ **پیشفرض:** فعال (`True`)
## **فرم** `NewVersionForm`
این فرم، نصخهٔ جدید را همراه با نوع افزایش نسخه مشخص میکند؛ درواقع فیلدهای این فرم مانند فیلدهای `ReleaseForm` است بهعلاوهی یک انتخابگر برای **نوع افزایش نسخه**. برای پیادهسازی این فرم باید از فرم `ReleaseForm` ارثبری کنید.
### **فیلد** `bump`
+ **نوع فیلد/ویجت:** انتخابی (`ChoiceField`) تک گزینه بههمراه ویجت `Select` و کلاس `"input"`
+ **برچسب *(label)*:**
```
نوع افزایش نسخه
```
+ **متن راهنما *(help text)*:**
```
نوع نسخهگذاری مطابق Semantic Versioning انتخاب شود.
```
+ **اجباری/اختیاری:** اجباری
+ **پیام خطا:**
پیام خطای نبود مقدار:
```
انتخاب نوع افزایش نسخه الزامی است.
```
+ **گزینهها:** گزینههای این فیلد بهصورت لیستی از تاپلهای دو عضوی به نام `BUMP_CHOICES` در فایل `utils/utility.py` قرار داده شدهاند. که در آن
+ مقدار `patch` به معنای «تغییرات جزئی بدون شکستن سازگاری» است.
+ مقدار `minor` به معنای «افزودن قابلیت بدون شکستن سازگاری» است.
+ مقدار `major` به معنای «تغییرات بزرگ/احتمالاً ناسازگار» است.
</details>

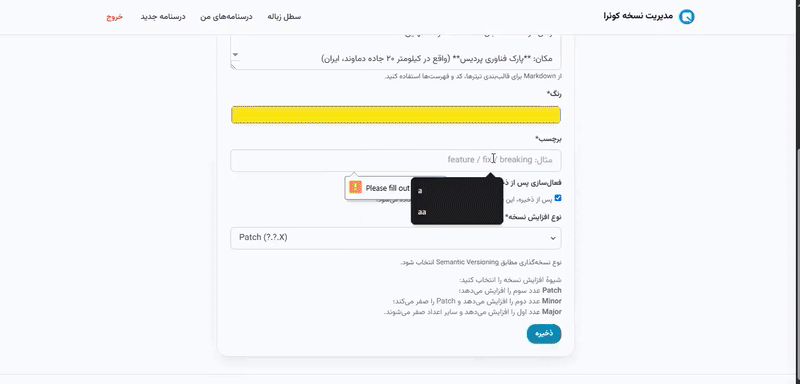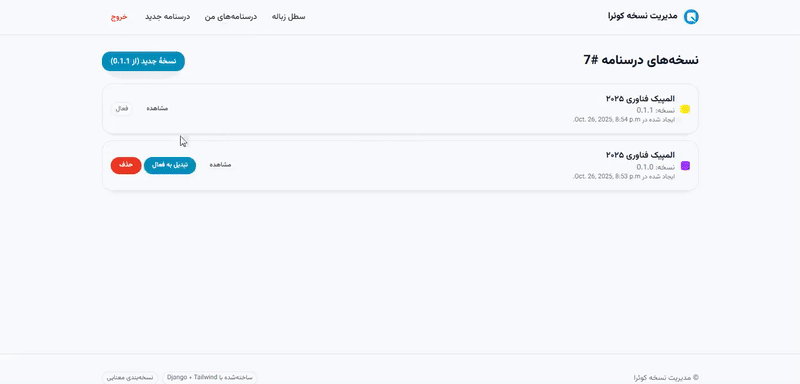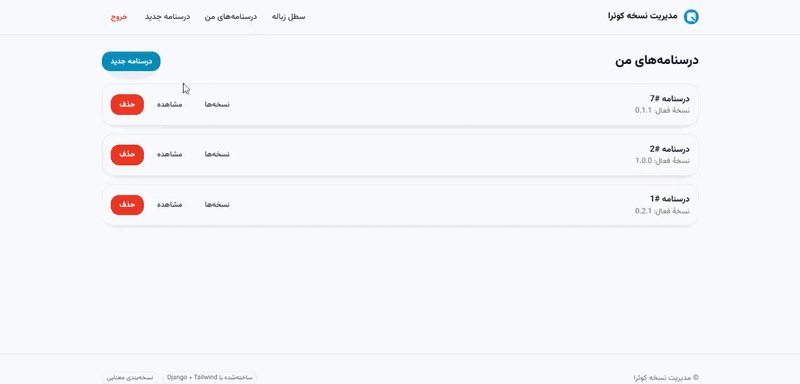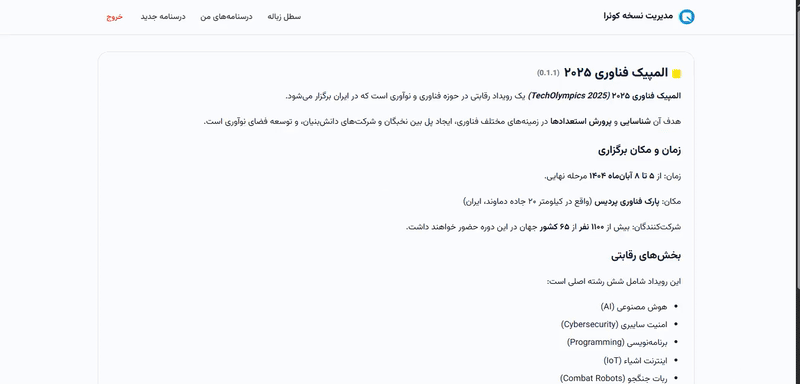
# **زیرمسئلهها**
سیستم داوری برای این سوال به **زیرمسئلههای** زیر برای نمرهدهی تقسیمبندی شده است که میتوانید **امتیاز** مربوط به هر کدام را در جدول زیر مشاهده کنید. **زیرمسئلههای** این جدول **ابتدا بر اساس اولویت و پیشنیازی پیادهسازی** و سپس **بر اساس امتیاز** آنها مرتبسازی شدهاند. **لذا پیشنهاد میشود در پیادهسازی از زیرمسئلهی ابتدایی آغاز کنید.**
| **زیرمسئله** | **امتیاز** |
| ----------------------------------------------- | :----: |
| **مدلهای** `Lesson` و `Release` | `75` |
| **مکانیزم** `Soft Delete` | `100` |
| **میکسین** `OwnerRequiredMixin` | `25` |
| **فرم** `ReleaseForm` | `70` |
| **فرم** `NewVersionForm` | `30` |
# **آنچه باید آپلود کنید**
+ **توجه**: پس از اعمال تغییرات، کل پروژه را _Zip_ کرده و آپلود کنید. **همانند پروژهی اولیه در فایل زیپشده نباید کد در پوشهی دیگری قرار بگیرد در غیر این صورت سیستم داوری فایل را شناسایی نکرده و نمرهای دریافت نخواهید کرد.**
+ **توجه:** تنها فایلهایی که در **ساختار پروژه** مشخص شدهاند، در سیستم داوری **مورد پذیرش** قرار خواهد گرفت و سایر تغییرات در سایر فایلها **بیتأثیر** خواهند بود.
+ **توجه:** متنهای نمونه در مدلها و فرمها باید **دقیقاً** برابر مقادیر گفتهشده باشند؛ در غیر این صورت نمرهی کامل دریافت نخواهید کرد.
آغازگر آغازگران
> **کانتست** تمام گشت و به پایان رسید **المپیک** ما همچنان در **اوّلِ وصفِ سوال ماندهایم...**
با رسیدن به **آخرین سوال** از [**مسابقات پایتون جنگوی**](https://quera.org/events/techolympics-python-0407) سری دوم [**#المپیکفناوری پردیس،**](https://quera.org/events/techolympics-0407) **علی غرغرو** *(Ali GhorGhorooo)* که از **ماهها قبل از شروع این سری مسابقات،** با غرهای فراوانی مانند "_من میدونمممممممممممممممم ما موفق نمیشیممممممممممممم_"، **نقش بسزایی** در پیشبرد این سری از مسابقات داشته است، میخواهد تا با توسعهی یک **فرمساز پویا** *(Dynamic Form Builder)* **جدید** برای کوئرا، **نظرسنجی جامع و کاملی** از تمام شرکتکنندگان این مسابقات در مورد **تمام بخشها،** از جمله *محتوا و سطح سوالات تا داستانهای عجیب غریب و طولانی سوالات مسابقه و کیفیت برگزاری مسابقه حضوری فینال* انجام دهد.
**فرمهایی** که این **فرمسازی پویا** قرار است تا برای نظرسنجی از شرکتکنندگان بسازد، باید قابلیتهای پیشرفتهای مانند *ثبت زمان پاسخدهی کاربران، تولید فرمها از روی مدل دادهها و پردازش پاسخها* را داشته باشد تا **علی غرغرو** در نهایت بتواند با **تحلیل** و **بررسی دادههای نظرسنجی** انجام شده و **زدن غرهای بهتر و بیشتر،** سری سوم **مسابقات #المپیکفناوری پردیس** که قرار است در سال آینده برگزار شود را به صورت هر چه بهتری برگزار کند. از آنجایی که سر او **همچنان با گفتن** "_من میدونمممممممممممممممم ما موفق نمیشیممممممممممممم_" برای تیم برگزاری مسابقه فینال، حسابی شلوغ است، **شما قرار است تا در این سوال به پیادهسازی بخشهایی از این فرمساز جدید کوئرا بر اساس توضیحات داده شده بپردازید.**

# **پروژهی اولیه**
برای دانلود پروژهی اولیه روی [این لینک](/contest/assignments/91477/download_problem_initial_project/310247/) کلیک کنید.
<details class="yellow">
<summary>**ساختار فایلها**</summary>
```
form-builder/
├── config
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── forms
│ ├── migrations
│ │ ├── __init__.py
│ │ └── 0001_initial.py
│ ├── templatetags
│ │ ├── __init__.py
│ │ └── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">form_tags.py</mark>
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">forms.py</mark>
│ ├── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">middleware.py</mark>
│ ├── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">models.py</mark>
│ ├── urls.py
│ ├── utils.py
│ └── <mark class="yellow" title="شما باید این فایل را تکمیل کنید">views.py</mark>
├── static
│ ├── css
│ │ └── style.css
│ └── js
│ └── main.js
├── templates
│ ├── forms
│ │ ├── field_create.html
│ │ ├── field_delete.html
│ │ ├── field_edit.html
│ │ ├── form_analytics.html
│ │ ├── form_builder.html
│ │ ├── form_create.html
│ │ ├── form_delete.html
│ │ ├── form_detail.html
│ │ ├── form_edit.html
│ │ ├── form_list.html
│ │ ├── form_responses.html
│ │ ├── form_success.html
│ │ ├── response_delete.html
│ │ └── response_detail.html
│ └── base.html
├── manage.py
└── requirements.txt
```
</details>
<details class="grey">
<summary>**راهاندازی پروژه**</summary>
برای اجرای پروژه، باید **پایتون و ابزار** _pip_ را از قبل نصب کرده باشید.
- ابتدا **پروژهی اولیه** را دانلود و از حالت فشرده خارج کنید.
- در پوشهی اصلی پروژه، یک **محیط مجازی پایتون** _(venv)_ ایجاد و فعال کنید:
```bash terminal terminal
python -m venv venv
source venv/bin/activate # در ویندوز: venv\Scripts\activate
```
- دستور زیر را برای **نصب نیازمندیها** در پوشهی اصلی پروژه اجرا کنید:
```bash terminal terminal
pip install -r requirements.txt
```
- برای **اجرای پروژه** *Django* دستور زیر را در مسیر پوشهی اصلی پروژه اجرا کنید:
```bash terminal terminal
python manage.py runserver
```
در صورت اجرای موفق، **یک لینک** در خروجی نمایش داده میشود که میتوانید **آن را در مرورگر باز کنید.**
- برای **اجرای مایگریشنها** و ایجاد جداول پایگاه داده، دستور زیر را اجرا کنید:
```bash terminal terminal
python manage.py migrate
```
- برای **بارگذاری دادههای نمونه** از **فایل** *fixture،* دستور زیر را اجرا کنید:
```bash terminal terminal
python manage.py loaddata data.json
```
</details>
# **جزئیات پروژه**
<details class="green">
<summary>**فایل `models.py`**</summary>
در این فایل تعدادی مدل وجود دارد که دو تا از آنها را شما باید پیادهسازی کنید؛ در تصویر زیر نمودار ER مربوط به آن جهت درک بهتر روابط میان این مدلها نمایش داده شده است.
|  |
| :-: |
| نمودار *Entity Rlationship Diagram (ERD)* مربوط به مدلها |
در این قسمت باید دو مدل `Form` و `Field` را به شکل گفته شده پیادهسازی کنید.
<details class="green">
<summary>**مدل `Form`**</summary>
این مدل وظیقهی نگهداری فرمهای ساخته شده توسط کاربران را دارد و اطلاعات مربوط به هر فرم را در خود ذخیره کرده تا در ادامه با استفاده از مدل `Field` بتوانیم سوالات برای این فرم ایجاد کنیم و آن را برای پاسخدهی به اشتراک بگذاریم.
| فیلد | نوع داده | توضیحات |
| -------- | ------------ | ------------------------------------ |
| `title` | `CharField` | بیشترین طول مجاز ۲۰۰ کاراکتر |
| `description` | `TextField` | توضیحات فرم (اختیاری) |
| `success_message` | `TextField` | پیام موفقیت بعد از ارسال |
| `allow_multiple_submissions` | `BooleanField` | اجازه چند بار پاسخ دادن به یک کاربر (پیشفرض: `False`) |
| `submission_limit` | `PositiveIntegerField` | حداکثر تعداد پاسخهای مجاز (اختیاری) |
| `expires_at` | `DateTimeField` | تاریخ انقضای فرم (اختیاری) |
| `is_active` | `BooleanField` | فعال یا غیرفعال بودن فرم (پیشفرض `True`) |
| `created_by` | `ForeignKey` | کاربری (`User`) که فرم را ساخته |
| `created_at` | `DateTimeField` | تاریخ ایجاد فرم (خودکار) |
| `updated_at` | `DateTimeField` | آخرین بروزرسانی (خودکار) |
* باید بتوان از طریق مدل `User` با استفاده از ویژگی `created_forms` به فرمهای ساخته شده توسط کاربر دسترسی داشت و همچنین در صورت حذف کاربر فرمهای مربوط به آن نیز حذف شوند.
* مقدار پیشفرض برای فیلد `success_message` برابر با رشتهی زیر است:
```
Thank you for your submission!
```
### **ویژگی** `is_expired`
بررسی میکند آیا فرم منقضی شده است؛ برای اینکار باید بررسی کنید زمان فعلی از زمان منقضی شدن فرم کمتر باشد.
### **ویژگی** `is_submission_limit_reached`
بررسی میکند آیا محدودیت پاسخها پر شده است یا خیر؛ برای اینکار باید از ارتباط میان این مدل با مدل `Response` استفاده کنید و در صورتی که متغیر `submission_limit` برای این فرم مقداردهی شده است، چک کنید آیا تعداد پاسخها بیشتر مساوی مقدار این فیلد باشد؛ در غیر اینصورت `False` برگردانید.
### **ویژگی** `can_accept_submissions`
یک مقدار بولی برمیگرداند که نشان میدهد فرم هنوز میتواند پاسخ جدید بگیرد یا خیر؛ برای پیادهسازی باید چک کنید فرم **فعال باشد** و **منقضی نشده باشد** و **محدودیت پاسخ آن پر نشده باشد**؛ در غیر اینصورت مقدار `False` برگردانده شود.
### **متد** `__str__`
خروجی این متد رشتهای به فرمت زیر میباشد:
```
<mark class="green" title="مقدار فیلد title">TITLE</mark>
```
### **متد** `get_response_count()`
در این متد باید تعداد پاسخهای مرتبط با فرم را از طریق رابطهی میان مدلهای `Form` و `Response` برگردانید.
### **متد** `get_completion_rate()`
نرخ تکمیل فرم را برمیگرداند؛ نرخ تکمیل که عددی ببین `0` و `100` است، از تقسیم تعداد پاسخها بر تعداد بازدیدهای فرم ضربدر `100` بدست میآید. همچنین برای دریافت تعداد ویوهای مربوط به هر فرم باید از رابطهی موجود میان مدلهای `Form` و `FormView` استفاده کرد.
</details>
<details class="green">
<summary>**مدل `Field`**</summary>
این مدل وظیفهی نگهداری اطلاعات مربوط به سوالات یک فرم را دارد و باید حاوی فیلدهای زیر باشد.
| فیلد | نوع داده | توضیحات |
| ------------- | ----------------- | -------------------------- |
| `form` | `ForeignKey` | ارجاع به فرم (`Form`) که این فیلد متعلق به آن است |
| `label` | `CharField` | عنوان فیلد (حداکثر ۲۰۰ کاراکتر) |
| `field_type` | `CharField` | نوع فیلد |
| `help_text` | `TextField` | متن راهنما برای فیلد (اختیاری) |
| `placeholder` | `CharField` | متن پیشفرض داخل فیلد (اختیاری) |
| `is_required` | `BooleanField` | آیا پر کردن فیلد اجباری است یا خیر (پیشفرض: `False`) |
| `order` | `PositiveIntegerField` | ترتیب نمایش فیلد در فرم (پیشفرض: `0`) |
| `options` | `JSONField` | گزینهها برای فیلدهای چند گزینهای (پیشفرض: لیست خالی) |
| `min_length` | `PositiveIntegerField` | حداقل طول متن (اختیاری) |
| `max_length` | `PositiveIntegerField` | حداکثر طول متن (اختیاری) |
| `min_value` | `FloatField` | حداقل مقدار (اختیاری) |
| `max_value` | `FloatField` | حداکثر مقدار (اختیاری) |
| `regex_pattern` | `CharField` | الگوی regex برای اعتبارسنجی (اختیاری) |
| `custom_error_message` | `CharField` | پیام خطای دلخواه (اختیاری) |
* فیلد `field_type` میتواند از یک فیلد انتخابی است که مقادیر مجاز برای آن به شکل زیر است:
```python
FIELD_TYPES = [
('text', 'Text'),
('email', 'Email'),
('number', 'Number'),
('textarea', 'Textarea'),
('select', 'Select'),
('radio', 'Radio'),
('checkbox', 'Checkbox'),
('file', 'File Upload'),
('date', 'Date'),
('url', 'URL'),
('phone', 'Phone'),
]
```
* `options` فقط برای فیلدهای چند گزینهای (`select`, `radio`, `checkbox`) استفاده میشود و انتخابهای مجاز آن را نشان میدهد.
* `min_length` و `max_length` برای فیلدهای متنی کاربرد دارند و درصورت مقدار دهی یک بازهی مشخص برای طول کاراکترهای آن فیلد تعیین میشود.
* `min_value` و `max_value` برای فیلدهای عددی کاربرد دارند و درصورت مقدار دهی یک بازهی مشخص برای مقدار آن فیلد تعیین میشود.
### **متد** `__str__`
خروجی این متد رشتهای به فرمت زیر میباشد:
```
<mark class="green" title="مقدار فیلد title از مدل form مربوطه">FORM_TITLE</mark> - <mark title="مقدار فیلد label">LABEL</mark>
```
### **متد** `clean()`
در این متد باید صحت مقادیر داده شده را برای ایجاد یک نمونه از مدل `Field` را بررسی کنید.
برای این کار ابتدا بررسی کنید اگر این فیلد از یکی از انواع فیلدهای انتخابی است و مقدار `options` خالی یا برابر لیست خالی است، یک `ValidationError` با پیغام زیر پرتاب کنید:
```
Choice fields must have at least one option.
```
در مرحلهی بعد، در صورت مقداردهی فیلدهای `min_value` و `max_value` بایستی بررسی کنید مقدار `max_value` همواره بزرگتر مساوی مقدار `min_value` باشد و در غیر این صورت یک `ValidationError` با پیغام زیر پرتاب کنید:
```
Minimum value cannot be greater than maximum value.
```
در ادامه همین اعتبارسنجی را برای فیلدهای `min_legth` و `max_length` نیز انجام دهید و در صورت وجود خطا باید حاوی پیغام زیر باشد:
```
Minimum length cannot be greater than maximum length.
```
در نهایت در صورت مقداردهی فیلد `regex_pattern`، بررسی کنید آیا الگوی وارد شده یک الگوری *Regex* معتبر است یا خیر. در صورت نامعتبر بودن یک `ValidationError` با پیغام زیر پرتاب کنید:
```
Invalid regex pattern.
```
### **متد** `validate_value(value)`
این متد وظیفهی اعتبارسنجی مقدار ورودی (`value`) برای یک نمونه از مدل `Field` را دارد. خروجی این متد یک لیست خواهد بود که در صورت وجود خطا حاوی این خطاها میباشد.
در صورتی که فیلد اجباری است اما مقدار ورودی خالی است (یعنی مقدار دهی نشده است) یک لیست تکعضوی حاوی رشتهی زیر را برگردانید:
```
"<mark title="مقدار فیلد label مدل">{label}</mark> is required."
```
اگر پاسخ به فیلد اختیاری است و مقدار ورودی نیز خالی داده نشده، یک لیست خالی برگردانید و اجرای تابع را متوقف کنید تا سایر اعتبارسنجی ها روی این فیلد انجام نشود.
اما در غیر این صورت بر اساس نوع فیلد (`field_type`) اعتبارسنجیهای زیر را انجام دهید:
+ `email`: مقدار ورودی را با الگوی `[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$` تطابق داده و در صورت عدم تطابق خطای زیر را به لیست خطاها اضافه کنید:
```
Please enter a valid email address.
```
+ `number`: در اینصورت سه مرحله اعتبارسنجی باید انجام دهید و هر کجا به خطا برخوردید دیگر ادامه ندهید؛ در مرحلهی اول، چک کنید مقدار داده شده از نوع عددی باشد و در غیر این صورت ارور زیر را به لیست ارورها اضافه کنید:
```
Please enter a valid number.
```
اگر ورودی از نوع عددی بود و فیلد `min_value` مقداردهی شده بود باید بررسی شود مقدار ورودی بیشتر مساوی مقدار این فیلد باشد و در غیر اینصورت خطای زیر به لیست خطاها اضافه شود:
```
Value must be at least <mark title="مقدار این فیلد">{min_value}</mark>.
```
و اگر ورودی از نوع عددی بود و از مراحل قبل عبور کردید، این بار همین کار را برای فیلد `max_value` انجام دهید و بررسی کنید مقدار ورودی کمتر مساوی مقدار این فیلد باشد و در غیر این صورت خطای زیر را اضافه کنید:
```
Value must be at most <mark title="مقدار این فیلد">{max_value}</mark>.
```
+ `url`: باید مقدار آدرس داده شده را بررسی کنیم تا یک URL معتبر باشد؛ برای اینکار با استفاده از الگوی زیر این مورد را بررسی کنید:
```
^https?://(?:[-\w.])+(?:[:\d]+)?(?:/(?:[\w/_.])*(?:\?(?:[\w&=%.])*)?(?:#(?:\w*))?)?$
```
در صورت عدم تطابق پیغام خطای زیر را به لیست خطاها اضافه کنید:
```
Please enter a valid URL.
```
+ `phone`: برای بررسی معتبر بود شماره تلفن وارد شده باید ابتدا آن را با الگوی `^\+?[1-9][0-9]{7,14}$` تطبیق داده و در صورت عدم مطابقت پیغام خطای زیر را اضافه کنید:
```
Please enter a valid phone number.
```
+ `select` یا `radio`: در صورتی که مقدار ورودی دادهشده در فیلد `options` که مقادیر مجاز برای فیلدهای انتخابی است وجود نداشت، پیغام خطای زیر را اضافه کنید:
```
Please select a valid option.
```
+ `checkbox`: برای فیلدهای از نوع چند انتخابی که ورودی از نوع لیست است، باید تمام اعضای لیست را بررسی کنید و در صورتی که حداقل یکی از اعضای لیست ورودی جز مقادیر مجاز برای این فیلد نبود خطای زیر را به لیست خطاها اضافه کنید:
```
Please select valid options.
```
در ادامه باید مقادیر `max_length` و `min_length` را بررسی کنید؛ در صورت مقداردهی باید مقدار ورودی را با توجه به مقادیر موجو در این متغیر ها بررسی کنید تا در بازهی مورد نظر باشند. در صورتی که طول کاراکترهای ورودی از `min_legth` کمتر است خطای زیر را اضافه کنید:
```
Must be at least <mark title="مقدار این فیلد">{min_length}</mark> characters long.
```
در غیر اینصورت اگر طول کاراکترها از `max_length` بیشتر است پیغام خطای زیر را اضافه کنید:
```
Must be at most <mark title="مقدار این فیلد">{max_length}</mark> characters long.
```
در آخر، در صورت مقداردهی فیلد `regex_pattern` باید الگوی موجود در این فیلد را با مقدار ورودی تطبیق داده و در صورت عدم تطابق، اگر فیلد `custom_error_message` مقداردهی شده بود آن را به لیست ارورها اضافه کنید و در غیر اینصورت خطای زیر را اضافه کنید:
```
Invalid format.
```
در نهایت پس از انجام اعتبارسنجیهای بالا لیست خطاها را برگردانید.
</details>
</details>
<details class="blue">
<summary>**فایل `forms.py`**</summary>
در این فایل شما وظیفهی تکمیل یک کلاس به نام `DynamicForm` را دارید.
این فرم وظیفه دارد از روی مدلهای ذخیرهشده (`Form` و `Field`) بهطور پویا یک فرم *HTML* مناسب برای نمایش به کاربر بسازد. تابع سازندهی کلاس (`__init__()`) از قبل پیادهسازی شده و شما تنها کافیست منطق مربوط به اعتبارسنجی و ذخیرهی مدل در پایگاهداده را در متدهای `clean()` و `save()` پیادهسازی کنید.
### **متد** `clean`
از این متد برای اعتبارسنجی دادههای فرم بعد از پر شدن توسط کاربر استفاده میکنیم.
در این متد ابتدا با صدا زدن متد `clean` کلاس والد اعتبارسنجی پیشفرض را انجام دهید و دیکشنری `cleaned_data` که برمیگرداند را در یک متغیر ذخیره کنید. در مرحلهی بعد روی همهی فیلدهای مرتبط با فرم پیمایش کرده و مقدار هر فیلد را از `cleaned_data` بگیرید؛ سپس با استفاده از متد `validate_value(...)` که پیشتر در مدل `Field` پیادهسازی کردید، ابتدا ورودی کاربر را بررسی کرده و در صورتی که لیست خطای برگردانده شده خالی نبود آن را با به لیست خطاهای فرم فعلی به همراه نام فیلد اضافه کنید:
```python
self.add_error(<mark title="نام فیلد">field_name</mark>, <mark class="red" title="یکی از خطاها">error</mark>)
```
در انتها دیکشنری `cleaned_data` را برگردانید.
### **متد** `save`
از این متد برای ذخیرهسازی پاسخهای ارسالشده توسط کاربر در مدل `Response` استفاده میکنیم و هدف از آن جداسازی منطق ذخیرهی این شیء از ویوهاست. خروجی این متد در صورت معتبر بودن دادهها و ذخیرهی اطلاعات کاربر، شیء `Response` ساخته شده است؛ و در غیر این صورت خروجی آن `None` خواهد بود.
ابتدا بررسی کنید که فرم معتبر است یا نه. اگر معتبر نبود، هیچ چیزی ذخیره نکنید و یک مقدار `None` برگردانید. در صورتی که فرم معتبر باشد، یک شیء `Response` جدید با استفاده از پارامترهای ارسالی برای فرم فعلی ایجاد کنید و آن را ذخیره کنید.
سپس باید روی تمام اشیاء فیلدهای مربوط به فرم فعلی پیمایش کنید و دادههای هر فیلد را ذخیره کنید؛ برای انجام اینکار ابتدا باید دادهها را از دیکشنری `cleaned_data` بخوانید؛ برای اینکار نیز به مقدار `name` هر فیلد در متد `__init__()` نوشته شده بود نیاز دارید. پس ابتدا نامی که مقدار فیلد با آن در این دیشکنری نگهداری میشود را تشکیل دهید و سپس از دیکشنری مقدار آن را بخوانید.
در صورتی که مقداری برای آن فیلد وجود داشت بسته به نوع فیلد یک شیء از مدل `ResponseData` ایجاد کنید و در پایگاهداده ذخیره کنید:
* اگر فیلد از نوع `file` بود آن را در ستون `file` از شیء `ResponseData` ذخیره کنید.
* در غیر اینصورت آن را به رشته تبدیل کرده و در ستون `value` ذخیره کنید (توجه کنید که اگر فیلد از نوع `checkbox` و مقدار آن از نوع لیست باشد باید آن را به *JSON String* تبدیل کنید)
در نهایت شیء `Response` ایجادشده را برگردانید.
</details>
<details class="purple">
<summary>**فایل `middlewares.py`**</summary>
شما باید یک **میدلور *(Middleware)*** بنویسید که زمان شروع و پایان پر کردن فرم را ثبت کرده و در نهایت مدت پاسخدهی کاربر را ذخیره کند تا علی غرغرو بتواند آمار زمان پاسخدهی کاربران را دریافت کند.
## **کلاس** `FormAccessMiddleware`
این کلاس وظیفه دارد مدت زمان اجرای هر درخواست را محاسبه کند و علاوه بر آن، مدت زمانی که یک کاربر برای پر کردن و ارسال فرم صرف میکند را نیز ثبت نماید. برای رسیدن به این هدف، سه متد اصلی باید پیادهسازی شوند: `process_request`، `process_response` و `_calculate_completion_time`.
### **متد** `process_request`
این متد پیش از آنکه درخواست به *view* برسد اجرا میشود. در اولین گام باید زمان شروع پردازش درخواست در ویژگیای به نام `_form_access_start_time` در شیء `request` ذخیره شود. این زمان بعداً برای محاسبهی مدت کل اجرای درخواست مورد استفاده قرار خواهد گرفت.
در ادامه لازم است بررسی شود که آیا درخواست مربوط به مشاهدهی یک فرم است یا خیر. این حالت زمانی رخ میدهد که نام ویو برابر `form_detail` باشد و متد درخواست نیز `GET` باشد. اگر چنین شرایطی برقرار بود، باید زمان شروع پر کردن فرم در شیء `session` ذخیره شود تا بتوان در لحظهی ارسال فرم، مدت زمان تکمیل آن را محاسبه کرد. برای این منظور ابتدا باید کلیدی به نام `form_start_times` در `session` ایجاد شود (در صورتی که وجود نداشت) و مقدار اولیهی آن یک دیکشنری خالی قرار گیرد. سپس شناسهی فرم از پارامترهای URL استخراج شده و پس از تبدیل به رشته، به عنوان کلید در این دیکشنری قرار داده میشود. مقدار متناظر با آن نیز برابر زمان فعلی خواهد بود.
در نهایت اگر هرگونه خطایی در طول اجرای این بخش رخ داد، باید با استفاده از `logger` پیام **خطا *(error)*** در لاگ ثبت شود تا فرآیند قابل پیگیری باشد.
```
Error in FormAccessMiddleware: <mark title="ارور مربوطه">{error}</mark>
```
### **متد** `process_response`
این متد پس از اجرای *view* و پیش از ارسال پاسخ به مرورگر فراخوانی میشود. در این مرحله ابتدا باید مدت زمان اجرای کل درخواست محاسبه شود. این کار از طریق مقایسهی زمان فعلی با مقداری که در متد `process_request` ذخیره شده انجام میشود. اگر این مدت زمان بیش از مقدار آستانهای باشد که در تنظیمات پروژه و در متغیر `FORM_REQUEST_SLOW_THRESHOLD` مشخص شده است، لازم است یک پیام هشدار در سطح *warning* در لاگ ثبت شود.
گام بعدی مربوط به حالتی است که کاربر یک فرم را ارسال کرده است. اگر نام ویو برابر `form_submit`، متد درخواست `POST` و وضعیت پاسخ نیز `302` باشد (که نشاندهندهی موفقیت و ریدایرکت است)، در این صورت باید متد `_calculate_completion_time` فراخوانی شود تا زمان تکمیل فرم محاسبه و در `session` ذخیره گردد.
در پایان، صرفنظر از نوع درخواست، لازم است جزئیات مربوط به آن از جمله مسیر، وضعیت کاربر، مدت زمان اجرا و دیگر اطلاعات مرتبط با استفاده از متد کمکی `_log_form_access` در لاگ ثبت شود.
همچنین اگر هرگونه خطایی در طول اجرای این بخش رخ داد، باید با استفاده از `logger` پیام **خطا *(error)*** در لاگ ثبت شود تا فرآیند قابل پیگیری باشد.
```
Error in FormAccessMiddleware: <mark title="ارور مربوطه">{error}</mark>
```
### **متد** `_calculate_completion_time`
این متد وظیفهی محاسبهی مدت زمانی را بر عهده دارد که کاربر صرف پر کردن یک فرم کرده است. برای انجام این کار، ابتدا شناسهی فرم از پارامترهای URL استخراج میشود. سپس در `session` به دنبال زمانی که به عنوان شروع پر کردن همان فرم ثبت شده است جستجو میکنیم. در صورت وجود، اختلاف بین زمان فعلی و آن زمان به عنوان مدت زمان تکمیل فرم (بر حسب ثانیه) محاسبه میشود. این مقدار در `session` و تحت کلید `form_completion_time` ذخیره خواهد شد تا در بخشهای بعدی سیستم مورد استفاده قرار گیرد. در نهایت برای جلوگیری از باقی ماندن دادههای غیرضروری، مقدار ذخیرهشدهی اولیهی شروع فرم از دیکشنری `form_start_times` حذف میشود.
</details>
<details class="pink">
<summary>**فایل `views.py`**</summary>
در این فایل شما وظیفهی پیادهسازی کلاس `FormSubmissionView` را دارید که وظیفهی مدیریت ارسالهای کاربران برای پاسخدهی به یک فرم را دارد.
## **کلاس** `FormSubmissionView`
این کلاس برای مدیریت فرآیند ارسال فرم توسط کاربر طراحی شده است. هر بار که کاربری یک فرم را پر کرده و دکمهی ارسال را میزند، منطق پردازش دادهها از طریق این ویو انجام میشود. از آنجا که کلاس از `DetailView` ارثبری میکند، وظیفهی نمایش جزئیات یک فرم (از جمله فیلدهای پویا) را بر عهده دارد، اما بخش اصلی و مهم آن در متد `post` پیادهسازی شده است.
### **متد** `post`
این متد زمانی اجرا میشود که یک درخواست `POST` به سمت سرور ارسال گردد، یعنی همان لحظهای که کاربر دادههای فرم را برای ذخیرهسازی ارسال میکند. در ادامه گامهای مهم این متد شرح داده شده است.
ابتدا شیء فرم مورد نظر از دیتابیس واکشی میشود تا بتوان بررسیها و اعتبارسنجیها روی آن اعمال گردد. سپس اولین شرط مهم این است که بررسی شود آیا فرم همچنان امکان دریافت پاسخ دارد یا خیر. اگر فرم بسته شده باشد (از طریق ویژگی `can_accept_submissions`)، کاربر با پیام خطای زیر مواجه شده و دوباره به صفحهی جزئیات همان فرم هدایت خواهد شد:
```
This form is no longer accepting submissions.
```
در گام بعدی لازم است اطمینان حاصل شود که کاربر یک **شناسهی سشن معتبر** دارد. این شناسه برای کاربرانی که وارد حساب نشدهاند اهمیت ویژهای دارد، زیرا به کمک آن میتوان تشخیص داد چه کسی (ولو ناشناس) فرم را ارسال کرده است. اگر کلید سشن هنوز ساخته نشده باشد، باید آن را ایجاد کنیم و سپس مقدار آن در متغیر `session_key` ذخیره میشود.
مسئلهی بعدی مربوط به جلوگیری از ارسال چندبارهی یک فرم توسط یک کاربر است. اگر فرم به گونهای تنظیم شده باشد که فقط یک بار قابلیت ارسال داشته باشد (`allow_multiple_submissions=False`)، آنگاه باید بررسی کنیم آیا کاربر (چه لاگین کرده و چه ناشناس) قبلاً پاسخی برای این فرم ثبت کرده است یا خیر.
* اگر کاربر وارد شده باشد، جستجو بر اساس فیلد `submitted_by` انجام میشود.
* اگر کاربر ناشناس باشد، بررسی با استفاده از کلید سشن (`session_key`) صورت میگیرد.
اگر چنین پاسخی وجود داشته باشد، ارسال مجدد متوقف میشود و پیامی به کاربر نمایش داده خواهد شد:
```
You have already submitted this form.
```
در ادامه یک نمونه از `DynamicForm` ساخته میشود که با توجه به مدل فرم و دادههای ارسالی (`POST` و `FILES`) مقداردهی شده است. این فرم پویا وظیفهی اعتبارسنجی مقادیر هر فیلد را بر عهده دارد. اگر دادهها معتبر باشند، مرحلهی ذخیرهسازی شروع میشود.
در زمان ذخیرهسازی، ابتدا مقدار مدت زمانی که کاربر صرف تکمیل فرم کرده از سشن خوانده میشود (کلیدی به نام `form_completion_time` که در *Middleware* محاسبه شده بود). اگر چنین مقداری وجود داشته باشد، به صورت یک `timedelta` به تابع `save` فرستاده میشود. متد `save` در نهایت یک پاسخ جدید در دیتابیس ایجاد کرده و دادههای مربوط به هر فیلد را ذخیره میکند.
پس از ذخیره موفق، دادهی `form_completion_time` از سشن حذف میشود تا برای درخواستهای بعدی باقی نماند. سپس اطلاعاتی دربارهی referrer (یعنی صفحهای که کاربر از آنجا به فرم آمده است) جمعآوری شده و در جدول مربوط به **بازدید فرمها (`FormView`)** ذخیره میشود. در اینجا منطق ثبت بازدید به گونهای است که اگر کاربر ناشناس باشد، بازدید بر اساس کلید سشن منحصربهفرد در نظر گرفته میشود و اگر کاربر وارد سیستم شده باشد، بر اساس حساب کاربری او ذخیره خواهد شد.
در پایان کاربر به صفحهی موفقیت (`form_success`) هدایت میشود. اما اگر دادههای فرم معتبر نباشند (یعنی `is_valid=False` برگردد)، همان صفحهی فرم دوباره رندر میشود و خطاهای اعتبارسنجی در کنار فیلدها نمایش داده خواهند شد تا کاربر بتواند اصلاحات لازم را انجام دهد.
</details>
<details class="grey">
<summary>**فایل `templatetags/form_tags.py`**</summary>
در این فایل یک سری **فیلترهای سفارشی *(Custom Template Filters)*** برای جنگو تعریف شدهاند. این فیلترها را میتوان در تمپلیتها استفاده کرد تا دادهها را قبل از نمایش به کاربر پردازش و تغییر دهند. در ادامه به معرفی و شرح عملکرد هر یک از این فیلترها میپردازیم.
### **فیلتر** `render_markdown(text)`
این فیلتر برای تبدیل متنهایی که به فرمت ***Markdown*** نوشته شدهاند به کد *HTML* استفاده میشود. زمانی که کاربر یک متن را با نشانهگذاریهای مارکداون وارد میکند، این فیلتر باید به کمک کتابخانهی `markdown` آن را پردازش کرده و نسخهی *HTML* آن را تولید کند. در نهایت متن تبدیلشده با `mark_safe` علامتگذاری شود تا جنگو آن را به عنوان *HTML* معتبر رندر کند.
### **فیلتر** `extract_field_id(field_name)`
این فیلتر وظیفه دارد **شناسهی عددی یک فیلد** را از نام آن (که در فرم `DynamicForm` ایجاد میکردیم) استخراج کند.
به عنوان مثال، اگر نام فیلد چیزی شبیه به `field_123` باشد، این فیلتر مقدار `123` را برمیگرداند. برای انجام این کار باید به دنبال الگوی `field_` به همراه عدد بگردید. اگر چنین الگویی پیدا شد، همان بخش عددی استخراج و بازگردانده شود؛ در غیر این صورت یک رشتهی خالی برگرداندید.
### **فیلتر** `get_field_type_icon(field_type)`
این فیلتر به ازای هر نوع فیلد، یک **کلاس آیکون از کتابخانهی *Font Awesome*** برمیگرداند. ورودی این تابع یک رشته خواهد بود که برای هر یک از انواع مجاز برای فیلدها (`field_type`) یک آیکون منحصر به فرد در نظر گرفته شده است:
```python
{
'text': 'fas fa-font',
'email': 'fas fa-envelope',
'number': 'fas fa-hashtag',
'textarea': 'fas fa-align-left',
'select': 'fas fa-list',
'radio': 'fas fa-dot-circle',
'checkbox': 'fas fa-check-square',
'file': 'fas fa-file-upload',
'date': 'fas fa-calendar',
'url': 'fas fa-link',
'phone': 'fas fa-phone',
}
```
اگر هم ورودی تابع یکی از موارد بالا نبود، مقدار پیشفرض `'fas fa-question'` بازگردانده شود.
</details>
# **زیرمسئلهها**
سیستم داوری برای این سوال به **زیرمسئلههای** زیر برای نمرهدهی تقسیمبندی شده است که میتوانید **امتیاز** مربوط به هر کدام را در جدول زیر مشاهده کنید. **زیرمسئلههای** این جدول **ابتدا بر اساس اولویت و پیشنیازی پیادهسازی** و سپس **بر اساس امتیاز** آنها مرتبسازی شدهاند. **لذا پیشنهاد میشود در پیادهسازی از زیرمسئلهی ابتدایی آغاز کنید.**
| زیرمسئله | امتیاز |
| ----------------------------- | ------ |
| مدل `Form` | 50 |
| مدل `Field` | 55 |
| فرم `DynamicForm` | 90 |
| میدلور `FormAccessMiddleware` | 90 |
| ویو `FormSubmissionView` | 135 |
| فیلترها | 30 |
# **آنچه باید آپلود کنید**
+ **توجه**: پس از اعمال تغییرات، کل پروژه را _Zip_ کرده و آپلود کنید. **همانند پروژهی اولیه در فایل زیپشده نباید کد در پوشهی دیگری قرار بگیرد در غیر این صورت سیستم داوری فایل را شناسایی نکرده و نمرهای دریافت نخواهید کرد.**
+ **توجه:** تنها فایلهایی که در **ساختار پروژه** مشخص شدهاند، در سیستم داوری **مورد پذیرش** قرار خواهد گرفت و سایر تغییرات در سایر فایلها **بیتأثیر** خواهند بود.
+ **توجه:** متنهای نمونه در مدلها و فرمها باید **دقیقاً** برابر مقادیر گفتهشده باشند؛ در غیر این صورت نمرهی کامل دریافت نخواهید کرد.