اسنپتریپ، به عنوان ارائه دهنده خدمات و سرویسهای مورد نیاز برای سفر، در کنار امکان رزرو هتل، اقامتگاه و مهمانسرا در سراسر ایران، مجموعهای کامل از خدمات مسافری مانند خرید بلیط اتوبوس، هواپیما و قطار را به یک مسافر ارائه می دهد.
احتمالا هنگامی که شما بخواهید برای تعطیلات نوروز به یک شهر مانند ارومیه سفر کنید، از طریق موبایل و یا لپتاپ و از مسیر جستجوی گوگل، پیامک تبلیغاتی و یا به صورت مستقیم، وارد سایت اسنپتریپ میشوید و بعد از ساخت حساب کاربری، اقدام به جستجو میکنید:
سپس، شما اقدام به انتخاب مقصد و تاریخ ورود/خروج خود میکنید. در نتیجه لیستی از هتلها برای شما مانند شکل زیر، نشان داده میشود.
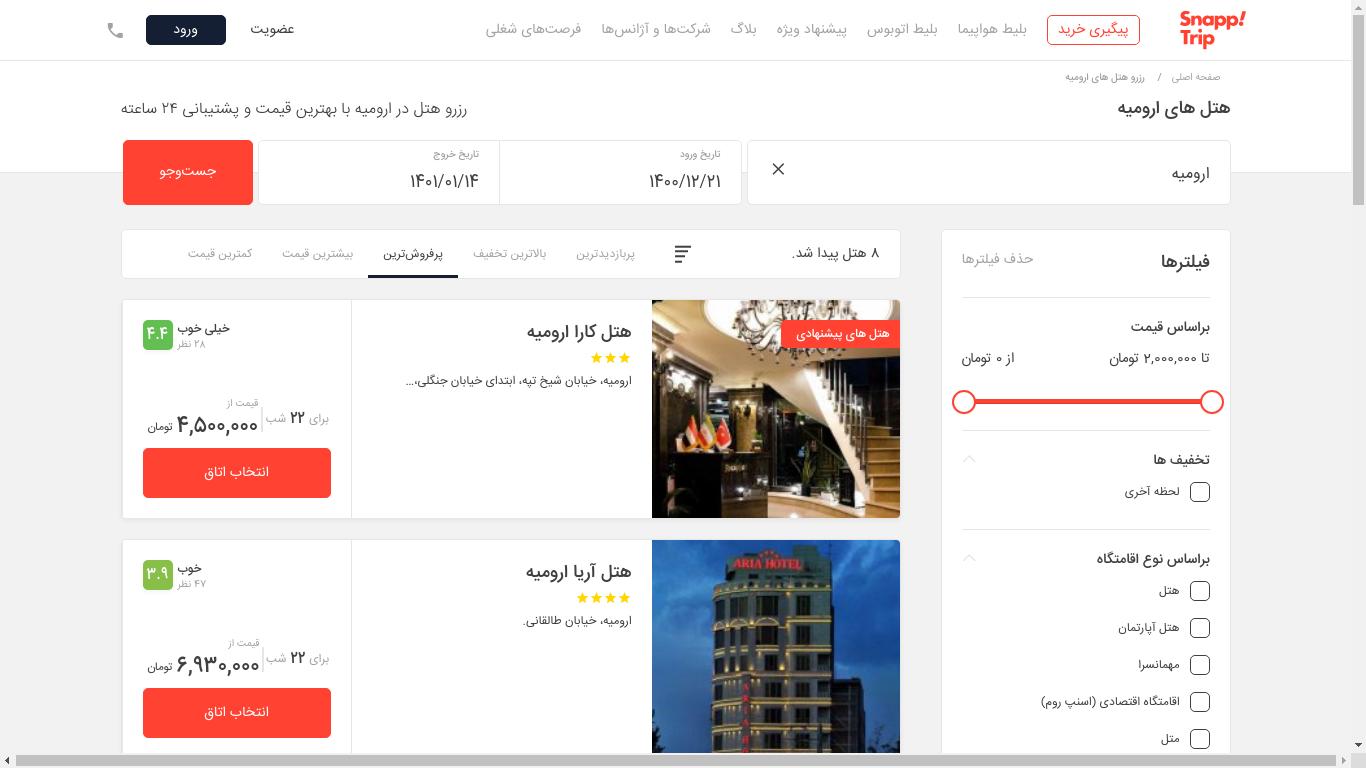
در نهایت، شما با کلیک بر روی هتلهای مختلف، اقدام به مقایسه آنها میکنید و شاید در نهایت یکی از آنها را رزرو کنید.
دادگان
در این سوال، شما به دادگان جستجوی کاربران از اینجا دسترسی دارید. هنگامی که این فایل را از حالت فشرده خارج کنید. پوشه hotels را میبینید. در صورتی که وارد این پوشه شوید، فایلهای آموزش (train.csv) و آزمایش (test.csv) در اختیار شما خواهند بود.
فایل آموزش، نتایج جستجوی کاربران را در یک بازه حدودا ۲ ساله شامل میشود و حدود ۳۰ میلیون سطر دارد. فایل آزمایش، دارای ۱۰۰ هزار سطر از اطلاعات جستجوی کاربران در بازه حدود ۱ ماه پس از آخرین جستجوی موجود در فایل آزمایش است (این سطرها، به صورت تصادفی از بین چند میلیون سطر آن ماه، انتخاب شدهاند).
جدول زیر، ستونهای موجود در فایل آموزش را توضیح میدهد. توجه داشته باشید که هر ردیف این دادگان، نشاندهنده جستجوی یک کاربر جهت رزرو هتل است.
| نام ستون | توضیحات ستون |
|---|---|
| user | شناسه کاربر |
| search_date | زمان انجام جستجو |
| channel | کاربر از چه کانالی وارد سایت شدهاست (تبلیغات پیامکی، تبلیغات شبکه اجتماعی، ورود مستقیم و ...) |
| is_mobile | آیا کاربر با دستگاه موبایل وصل شدهاست؟ |
| is_package | آیا کاربر در حال جستجوی هتل به همراه بلیط اتوبوس یا هواپیما یا قطار است؟ |
| destination | شناسه مقصد مورد نظر کاربر |
| checkIn_date | تاریخ ورود به هتل |
| checkOut_date | تاریخ خروج از هتل |
| n_adults | تعداد افراد بالغ اعلام شده جهت رزرو هتل |
| n_children | تعداد کودکان اعلام شده جهت رزرو هتل |
| n_rooms | تعداد اتاق مورد نظر برای رزرو |
| hotel_category | گروهبندی هتلی که جزییاتش را مشاهده میکنند. این گروهبندی میتواند بر اساس مواردی مانند چندستاره بودن و یا نوع هتل باشد. |
| is_booking | آیا کاربر در نهایت، هتل مشاهده شده را رزرو کرد؟ |
توجه
لطفا در هنگام کار با این دادگان، به نکات زیر توجه داشته باشید:
- فایل آزمایش، ستون
is_bookingرا ندارد. - مجموع فایلهای
unzipشده دادگان آموزش و آزمایش روی هم، دارای اندازه حدود ۳ گیگابایتی میباشند. نحوه روبهرو شدن شما با دادگان با این حجم، جزو یکی از چالشها و اهداف طراحی این سوال بودهاست.
صورت مسئله
با استفاده از دادگان توضیح داده شده در بالا، اسنپتریپ از شما انتظار دارد که بر اساس فایل آموزش، مُدلی آموزش دهید که بر اساس جستجوی کاربران و سایر ویژگیهای مرتبط با آن، بتواند پیشبینی کند که آیا یک کاربر، هتل مشاهده شده را رزرو خواهد کرد یا نه (فایل آزمایش، مشخصات جستجوهایی را شامل میشود که بایستی احتمال رزرو شدن هتل را برای آنها، پیشبینی کنید). بدین ترتیب، مجموعه اسنپتریپ، میتواند برای هرکاربر، متناسب با پیشبینی رزرو، تصمیم متناسبی همانند ارائه تخفیف و یا پیشنهاد سایر هتلها، در لحظه اتخاذ کند.
در این سوال باید احتمال رزرو شدن هتل را پیشبینی کنید. به عبارت بهتر احتمال True شدن ستون is_booking را تخمین بزنید.
راهنمایی
شاید نکات زیر، بتوانند به شما در حل این مسئله کمک بکنند:
- اگر که تمامی دادگان آموزش در حافظه (
RAM) جا نمیشوند، شاید بتوانید به صورت بخشبخش آن را بخوانید و یا فقط از بخشی از دادگان آموزش به انتخاب خود و نه همه آن، استفاده کنید. همچنین طراحی یک ساختمان داده مناسب همچون لیست ولی با تفاوتهایی در بارگذاری دادگان، میتواند یک راهحل دیگر باشد. - محاسبه ویژگی (
feature)های مناسب - استفاده از یادگیری تحت نظارت (
supervised) - یا استفاده از هر روش مرتبط دیگر با تحلیل داده، یادگیری ماشین و عمیق
ارزیابی
برای ارزیابی مُدل شما از سطح زیر ناحیه نمودار ROC استفاده میشود. برای مطالعه بیشتر در مورد این نمودار میتوانید ویکیپدیا یا راهنمای کوتاه نکات و ترفندهای یادگیری ماشین را مطالعه کنید.
امتیاز نهایی مدل شما طبق فرمول زیر محاسبه میشود: \[ score = ((AUCROC\times100)-50)\times4\]
توضیحات
علت استفاده از این فرمول برای امتیازدهی، این است که اگر به صورت تصادفی برای جستجوها عددی پیشبینی کنید، auc_roc مدل شما ۰.۵ خواهد بود. بنابراین تنها مدلهایی پذیرفته میشوند که دارای auc_roc بیشتر از ۰.۵ باشند. توجه داشته باشید که بیشترین امتیاز ممکن از این سوال ۲۰۰ و کمترین امتیاز ممکن، صفر است.
خروجی
پیشبینیهای مدل خود بر روی دادگان آزمایش (test.csv) را در فایلی با نام output.csv قرار دهید. این فایل باید دارای یک ستون با نام prediction باشد که ردیف i ام ستون prediction، پیشبینی شما برای سطر ردیف i ام فایل آزمایش باشد (دقت کنید که این ستون باید حتما دارای header باشد).
بعد از آمادهسازی فایل output.csv، آن را برای ما بارگذاری کنید.
نمونه خروجی فایل output.csv (فقط سه خط اول به همراه نام ستون)
prediction
0.723
0.516
0.281
توجه
حتما فایل output.csv باید دارای ۱۰۰,۰۰۰ سطر (بدون در نظر گرفتن header) و یک ستون باشد.
همچنین نام ستون بایستی بدون space در قبل و بعد از نام آن، باشد. در غیر این صورت، سیستم داوری نمرهای به شما نخواهد داد.
هشدار 😱
فراموش نکنید که قبل از پایان زمان مسابقه، بایستی تمامی کدهای این مسابقه را از قسمت بارگذاری کُد برای ما ارسال کنید. در غیر این صورت، شما از این مسابقه، امتیازی کسب نمی کنید.
توجه داشته باشید که اگر از jupter notebook استفاده می کنید بایستی همانند توضیحات قسمت بارگذاری کُد، خروجی .py را دریافت و برای ارسال در نظر بگیرید. ارسال فایلهای jupyter همانند .ipynb مورد قبول واقع نخواهند شد.