سلام دوست عزیز😃👋
به مسابقه «**المپیک فناوری ۲۰۲۵: پردازش تصویر**» خوش آمدی!
هرگونه **ارتباط با سایر شرکتکنندگان** در مسابقات کوئرا ممنوع است و بعد از شناسایی **از لیست شرکتکنندگان مسابقه حذف میشوید**.
در طول مسابقه، میتوانید سؤالات خود را از قسمت «[سوال بپرسید](https://quera.org/contest/clarification/84123/)» مطرح کنید.
موفق باشید 😉✌
| فایل اولیهی تمرین را میتوانید از [این لینک](/contest/assignments/84378/download_problem_initial_project/306358/) دانلود کنید. |
| :--: |
در دنیای مدرن فوتبال، هوش مصنوعی به بازوی اصلی مربیان و آنالیزورها تبدیل شده است. از تحلیل تاکتیکی حریف گرفته تا بررسی عملکرد بازیکنان، همهچیز به سمت هوشمند شدن پیش میرود. تصور کنید شما معمار هوش مصنوعی یک باشگاه سطح اول هستید و اولین ماموریت شما، ساختن سیستمی است که بتواند در یک لحظه، توازن عددی دو تیم در زمین را تحلیل کند. آیا تیم شما در یک ضد حمله برتری نفری دارد؟ آیا در دفاع تحت فشار است؟ پاسخ به این سوالات با تحلیل آنی تصاویر بازی ممکن میشود.
در این چالش، شما این سیستم هوشمند را خواهید ساخت!
----------
ماموریت شما ساخت یک مدل هوش مصنوعی است که بتواند با دریافت یک تصویر از مسابقه فوتبال، **تعداد بازیکنان هر یک از دو تیم** حاضر در زمین را به طور خودکار شمارش کند. مدل شما باید بتواند با تحلیل ویژگیهای بصری، بازیکنان را به دو تیم مجزا تفکیک کرده و تعداد دقیق آنها را گزارش دهد.
این چالش برای سنجش توانایی شما در **طراحی یک خط لوله (Pipeline) هوشمند و خودکار** برای حل یک مسئله واقعی طراحی شده است. هدف، صرفاً استفاده از یک مدل آماده نیست، بلکه ترکیب خلاقانه الگوریتمهای پردازش تصویر و یادگیری ماشین برای رسیدن به نتیجه در شرایطی است که دادههای آموزشی لیبلدار وجود ندارد.
<details class="red">
<summary>
**قوانین و نکات**
</summary>
به شما یک مجموعه شامل تقریباً ۱۰۰۰ تصویر از مسابقات فوتبال، **بدون هیچگونه لیبل**، ارائه میشود. تمام پردازشها و نتایج باید صرفاً بر اساس همین مجموعه تصاویر (و منابع مجازی که در ادامه ذکر میشود) استخراج گردد.
1. **استفاده از منابع خارجی:** شما مجاز به استفاده از مدلهای پایهی **عمومی** هستید که بر روی دیتاستهای بزرگ و غیرمرتبط با این مسئله خاص (مانند **COCO** یا **ImageNet**) آموزش دیدهاند.
✅مثل استفاده از وزنهای استاندارد YOLOv8 (`yolov8s.pt`) که برای تشخیص ۸۰ کلاس عمومی دیتاست COCO آموزش دیده است.
**❌ غیرمجاز:** استفاده از مدلهایی که به طور خاص برای مسئله "تشخیص بازیکن فوتبال"، "تفکیک لباس تیم" یا موارد مشابه توسط دیگران آموزش داده شده و در پلتفرمهایی مانند Roboflow Universe، Kaggle، یا GitHub به اشتراک گذاشته شدهاند، **اکیداً ممنوع است.**
❌مثل دانلود مدلی از Roboflow که از قبل میتواند بازیکنان دو تیم آبی و قرمز را تفکیک کند.
> استفاده از هرگونه دیتاست خارجی (شامل تصاویر، لیبلها، و...) برای آموزش، فاینتیون کردن، یا هر هدف دیگری **ممنوع است.** راهحل شما باید فقط با استفاده از دیتاست ارائهشده در مسابقه و مدلهای پایهی عمومی مجاز، کار کند.
2. **محیط اجرا:** کد نهایی شما باید در یک نوتبوک **Google Colab** ارائه شود. این نوتبوک باید با یک بار اجرا (گزینه "Run all")، تمام مراحل از بارگذاری دادهها و مدلها گرفته تا تولید فایل `submission.csv` نهایی را بدون نیاز به دخالت دستی و بدون خطا انجام دهد.
</details>
## خروجی
شما باید یک فایل به نام `submission.csv` تولید کنید که شامل سه ستون است: `image_name`, `count_1`, و `count_2`.
+ `image_name`: نام تصویر مورد نظر از پوشه `test`.
+ `count_1`: تعداد بازیکنان تیمی که در آن تصویر **تعداد بیشتری** دارد.
+ `count_2`: تعداد بازیکنان تیمی که در آن تصویر **تعداد کمتری** دارد.
**نکته مهم:** اگر تعداد بازیکنان دو تیم مساوی بود، تفاوتی ندارد کدام در ستون اول بیاید.
برای مثال در تصویر زیر، ردیف مربوط به فایل خروجی به شکل زیر است:
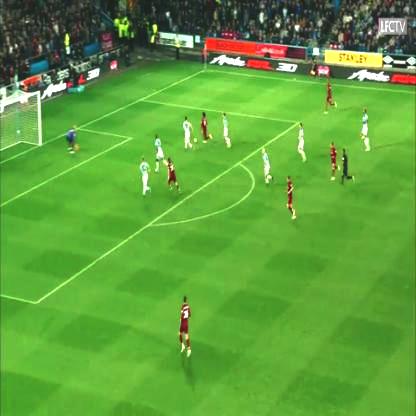
| image_name | count_1| count_2|
| :--- | :--- | :--- |
| jpg | 7 | 6 |
<details class="green">
<summary>
**راهنمایی تصویر**
</summary>
تیم سفید 7 بازیکن و تیم قرمز 6 بازیکن را در تصویر دارد. دقت کنید که دروازهبان و طبیعتا داور به عنوان بازیکنان شمارش **نشدهاند.**
</details>
## معیار ارزیابی (Evaluation Metric)
امتیاز نهایی شما بر اساس یک معیار به نام **«امتیاز مبتنی بر میانگین خطای مطلق»** محاسبه خواهد شد. این معیار نه تنها شمارشهای کاملاً درست را تشخیص میدهد، بلکه به پیشبینیهایی که به مقدار واقعی نزدیک هستند نیز امتیاز مناسبی اختصاص میدهد تا کیفیت واقعی مدل شما سنجیده شود.
فرآیند امتیازدهی در سه مرحله انجام میشود:
۱. **محاسبه خطای مطلق:** برای هر یک از دو تیم (`team1` و `team2`) در هر تصویر، اختلاف بین تعداد پیشبینیشده توسط شما و تعداد واقعی بازیکنان محاسبه میشود. به این اختلاف قدر مطلق، **خطای مطلق** میگوییم.
۲. **محاسبه میانگین خطای مطلق (MAE):** در مرحله بعد، از تمام خطاهای مطلق به دست آمده در کل تصاویر آزمون، میانگین گرفته میشود. عدد نهایی که **Mean Absolute Error (MAE)** نام دارد، نشان میدهد که الگوریتم شما به طور متوسط در هر پیشبینی چقدر خطا داشته است.
۳. **تبدیل خطا به امتیاز نهایی:** در نهایت، عدد *MAE* (که هرچه کمتر باشد بهتر است) با استفاده از یک فرمول نمایی به یک **امتیاز نهایی بین ۰ تا ۱۰۰** تبدیل میشود. این فرمول به خطاهای کوچک جریمه کم و به خطاهای بزرگ جریمه سنگینی اختصاص میدهد.
\[
\text{Score} = 100 \times e^{-\text{MAE}}
\]
| **نکته مهم**: دوباره تاکید میشود برای جلوگیری از تقلب و برای اطمینان از صحت فایل ارسالی، نوتبوک نهایی شما باید پس از اجرا در محیطی استاندارد (مانند *Google Colab* یا *Jupyter*) بتواند فایل `submission.csv` را مجدداً تولید کند. در صورت وجود هرگونه مغایرت بین فایل تولیدی جدید و فایل ارسالی شما، این عمل **تقلب** محسوب شده و نه تنها امتیاز این سؤال را از دست خواهید داد، بلکه نمره منفی برای شما منظور خواهد شد که بر امتیاز کل شما تأثیر خواهد گذاشت. |
| :--: |
آنالیز خسته
ارسال پاسخ برای این سؤال
در حال حاضر شما دسترسی ندارید.