مقدمهای بر دستهبندی بیز ساده (Naive Bayes Classification)

دستهبندی بیز ساده (Naive Bayes Classification) یکی از سادهترین و محبوبترین الگوریتمها در دادهکاوی (data mining) یا یادگیری ماشین (machine learning) است. ایده اصلی دستهبندی بیز ساده بسیار ساده است.
مطلب مرتبط: یادگیری ماشین چیست؟
شهود اصلی
فرض کنید ما دو دسته کتاب داریم. یک دسته کتابهای ورزشی و دسته دیگر کتابهای یادگیری ماشین. بیایید فرض کنیم در مجموع ۶ کتاب از این دو دسته داریم و تعداد کلمه «Match» (ویژگی شماره ۱) و تعداد کلمه «Algorithm» (ویژگی شماره ۲) در آنها مطابق جدول زیر شمارش شده است:
| تعداد کلمه Match | تعداد کلمه Algorithm | کتاب |
| ۱ | ۱۰ | کتاب یادگیری ماشین ۱ |
| ۰ | ۸ | کتاب یادگیری ماشین ۲ |
| ۱ | ۷ | کتاب یادگیری ماشین ۳ |
| ۶ | ۰ | کتاب ورزشی ۱ |
| ۷ | ۱ | کتاب ورزشی ۲ |
| ۹ | ۰ | کتاب ورزشی ۳ |
واضح است که کلمه «Algorithm» بیشتر در کتابهای یادگیری ماشین و کلمه «Match» بیشتر در کتابهای ورزشی ظاهر میشود. با این دانش، فرض کنید کتابی داریم که دستهبندی آن مشخص نیست ولی میدانیم که ویژگی شماره ۱ در آن مقدار ۲ و ویژگی شماره ۲ مقدار ۱۰ دارد. بنابراین میتوان گفت که کتاب متعلق به دسته کتابهای ورزشی است.
اساساً با توجه به مقادیر ویژگیهای ۱ و ۲، میخواهیم بفهمیم که کدام دسته محتملتر است.
از تعداد به احتمال
این رویکردِ مبتنی بر شمارش برای تعداد کم دستهها و کلمات بهخوبی کار میکند. همین شهود با استفاده از احتمال شرطی (Conditional Probability) با دقت بیشتری دنبال میشود. اجازه دهید احتمال شرطی را نیز با یک مثال توضیح دهیم.
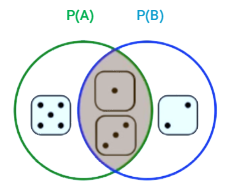
فرض کنید:
پیشامد A: عدد ظاهرشده روی تاس فرد باشد و پیشامد B: عدد ظاهرشده روی تاس کوچکتر از ۴ باشد
P(A) = 3/6 است (حالات مطلوب ۱,۳,۵ و همه حالات 1,2,3,4,5,6 هستند). به طور مشابه P(B) = 3/6 است (حالات مطلوب 1,2,3 و همه حالات 1,2,3,4,5,6 هستند). یک مثال از احتمال شرطی این است که احتمال بدست آوردن یک عدد فرد (A) اگر عدد کمتر از ۴ باشد (B) چقدر است؟ برای یافتن این احتمال ابتدا اشتراک پیشامدهای A و B را پیدا کرده و سپس بر تعداد حالات B تقسیم میکنیم:
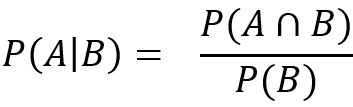
P(A|B) احتمال شرطی است و احتمال A به شرط B خوانده میشود. این معادله مبنای اصلی را تشکیل میدهد. حال بیایید دوباره به مسئله دستهبندی کتاب برگردیم و دستهبندی کتاب را به صورت رسمیتر پیدا کنیم.
احتمال شرطی به دستهبندیکننده بیز ساده
بیایید از نشانهگذاری زیر استفاده کنیم:
«Book=ML» پیشامد A است، «book=Sports» پیشامد B است، و «ویژگی ۱ = ۲ و ویژگی ۲ = ۱۰» پیشامد C است. پیشامد C یک پیشامد مشترک است که در ادامه به آن خواهیم پرداخت.
برای حل مسئله باید P(A|C) و P(B|C) را محاسبه کنیم. اگر مقدار اولی 0.01 و دومی 0.05 باشد، نتیجهگیری ما این خواهد بود که کتاب متعلق به کلاس دوم است. این یک دستهبندیکننده بیزی (Naive Bayes Classifier) است، بیز ساده فرض میکند که ویژگیها مستقل هستند. بنابراین:
P(ویژگی ۱ = ۲ و ویژگی ۲ = ۱۰) = P(ویژگی ۱ = ۲) * P(ویژگی ۲ = ۱۰)
بیایید این شرایط را به ترتیب x1 و x2 بنامیم.
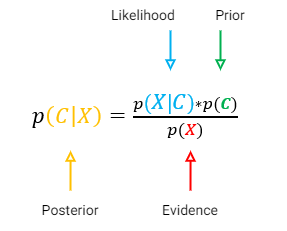
بنابراین با استفاده از درستنمایی (likelihood)، احتمال پیشین (Prior) و شواهد (Evidence)، احتمال پسین (Posterior Probability) را محاسبه میکنیم و سپس فرض میکنیم که ویژگیها مستقل هستند. بنابراین درستنمایی (likelihood) به این صورت بسط پیدا میکند.
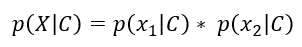
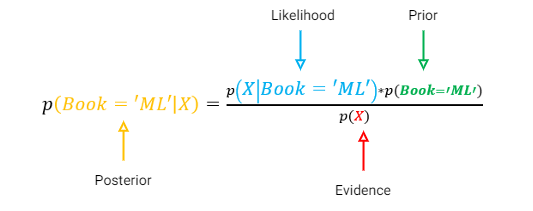
معادله بالا برای دو ویژگی نشان داده شده است، اما میتوان آن را برای موارد بیشتر بسط داد. برای سناریوی خاص ما، معادله به شکل زیر تغییر میکند. این معادله که برای «Book=ML» نشان داده شده است، به طور مشابه برای «Book=Sports» نوشته میشود.
ممکن است علاقهمند باشید: شبکه عصبی کانولوشن چیست؟
پیادهسازی
بیایید از مجموعه داده Flu برای بیز ساده استفاده کنیم و آن را وارد کنیم. شما میتوانید مسیر را تغییر دهید. میتوانید دادهها را از اینجا دانلود کنید.
وارد کردن دادهها
| لرز | آبریزش بینی | سردرد | تب | آنفولانزا |
| ✔ | ⨯ | خفیف | ✔ | ⨯ |
| ✔ | ✔ | ⨯ | ⨯ | ✔ |
| ✔ | ⨯ | شدید | ✔ | ✔ |
| ⨯ | ✔ | خفیف | ✔ | ✔ |
| ⨯ | ⨯ | ⨯ | ⨯ | ⨯ |
| ⨯ | ✔ | شدید | ✔ | ✔ |
| ⨯ | ✔ | شدید | ⨯ | ⨯ |
| ✔ | ✔ | خفیف | ✔ | ✔ |
nbflu=pd.read_csv('/kaggle/input/naivebayes.csv')تبدیل دادهها
ما ستونها را در متغیرهای مختلف تبدیل و ذخیره میکنیم.
# Collecting the Variables
x1= nbflu.iloc[:,0]
x2= nbflu.iloc[:,1]
x3= nbflu.iloc[:,2]
x4= nbflu.iloc[:,3]
y=nbflu.iloc[:,4]
# Encoding the categorical variables
le = preprocessing.LabelEncoder()
x1= le.fit_transform(x1)
x2= le.fit_transform(x2)
x3= le.fit_transform(x3)
x4= le.fit_transform(x4)
y=le.fit_transform(y)
# Getting the Encoded in Data Frame
X = pd.DataFrame(list(zip(x1,x2,x3,x4)))تطبیق مدل
در این مرحله ابتدا مدل را آموزش میدهیم و سپس برای یک بیمار پیشبینی خواهیم کرد.
model = CategoricalNB()
# Train the model using the training sets
model.fit(X,y)
#Predict Output
#['Y','N','Mild','Y']
predicted = model.predict([[1,0,0,1]])
print("Predicted Value:",model.predict([[1,0,0,1]]))
print(model.predict_proba([[1,0,0,1]]))خروجی
Predicted Value: [1]
[[0.30509228 0.69490772]]خروجی میگوید که احتمال عدم آنفولانزا 0.31 و آنفولانزا 0.69 است. بنابراین نتیجه آنفولانزا خواهد بود.
Naive Bayes بهعنوان یک طبقهبندیکننده پایه بسیار خوب عمل میکند. سریع است و میتواند روی تعداد نمونههای آموزشی کمتر و دادههای پرت (Noisy Data) کار کند. یکی از چالشها این است که ویژگیها را مستقل فرض میکند.