تاریخچه یادگیری ماشین

الگوریتمهای یادگیری ماشین میتوانند کارهای فوقالعادهای انجام دهند؛ از تسلط بر بازیهای رومیزی و شناسایی چهرهها گرفته تا خودکارسازی کارهای روزانه و پیشبینیها و تصمیمگیریها. اما باور اینکه پیشرفت این تکنولوژی تنها کمتر از یک قرن پیش آغاز شده است بسیار دشوار است. تعیین زمان دقیق نقطهی شروع تاریخچه یادگیری ماشین غیرممکن است، در عوض یادگیری ماشین را میتوان ترکیبی از کارهای بسیاری از افراد دانست که با اختراعات، الگوریتمها یا دستاوردهای خود در پیشرفت و شکلگیری آن مشارکت داشتهاند.
مطلب مرتبط: یادگیری ماشین (Machine Learning) چیست؟
در ادامه سعی کردهایم تاریخچهای مختصر از یادگیری ماشین و افرادی که در توسعهی یادگیری ماشین مشارکت داشتهاند و همچنین وقایع مهم در تاریخچه یادگیری ماشین را معرفی کنیم.
تاریخچه یادگیری ماشین
1943
تاریخچه یادگیری ماشین با اولین مدل ریاضی شبکههای عصبی که در مقاله علمی «A logical calculus of the ideas immanent in nervous activity» توسط Walter Pitts و Warren McCulloch معرفی شد، شروع میشود. آنها یک مدل ریاضی برای عصب زیستی ارائه کردند که هر نورون مغز را به عنوان یک پردازشگر دیجیتالی ساده و مغز را به عنوان یک ماشین محاسباتی کامل معرفی کرد. این مدل توانایی بسیار محدودی داشت و هیچ مکانیزمی برای یادگیری نداشت، اما شبکه عصبی مصنوعی و یادگیری عمیق را پایهگذاری کرد.

1949
Donald Hebb کتابی به نام «The Organization of Behavior» را منتشر کرد. این کتاب که تئوریهایی در مورد چگونگی ارتباط رفتار با فعالیت مغز و شبکههای عصبی ارائه میداد، به یکی از پایههای توسعه یادگیری ماشین تبدیل شد.

1950
Alan Turing، ریاضیدان و دانشمند کامپیوتر، تست تورینگ را در سال 1950 معرفی کرد. در این آزمون یک سیستم زمانی بهاندازهی کافی هوشمند محسوب میشود که بتواند مانند انسان از پس سؤالات یک داور برآید و بتواند او را متقاعد کند که کسی که به سؤالات او پاسخ میدهد یک انسان است نه یک ماشین. جالب اینجا است که این آزمون هنوز هم چالشی بزرگ محسوب میشود.

1951
زمانی که بیشتر رایانهها هنوز از کارتهای پانچشده برای اجرا استفاده میکردند، Marvin Minsky و Dean Edmonds اولین شبکه عصبی مصنوعی به نام SNARC را که از 40 سیناپس هبینِ (این سیناپسها در کتابی که Donald Hebb در سال ۱۹۴۹ نوشت تعریف شدهاند) بههمپیوسته با حافظه کوتاهمدت تشکیل شده بود را ساختند.

1952
Arthur Samuel در IBM برنامهای برای بازی کامپیوتری Checkers در سطح قهرمانی ایجاد کرد که به جای تحقیق در مورد همه مسیرهای ممکن، از تکنیک هرس آلفا-بتا (Alpha-Beta Pruning) که احتمال برندهشدن را اندازهگیری میکند استفاده میکرد. او با این فرض که حریف نیز بهصورت بهینه بازی میکند، از یک الگوریتم minimax برای یافتن حرکت بهینه استفاده کرد. به علاوه مکانیزمهایی را برای بهبود مداوم برنامه خود طراحی کرد؛ به عنوان مثال مقایسه حرکات قبلی با شانس برنده شدن.

1956
پروژه تحقیقاتی تابستانی Dartmouth را زادگاه هوش مصنوعی میدانند. John McCarthy یازده نفر از ریاضیدانان، محققان و دانشمندان برجسته در زمینههای ریاضی، مهندسی، کامپیوتر و علوم شناختی را به کالج Dartmouth دعوت کرد تا در مورد ماشینهایی که قادر به فکر کردن هستند برای حدود شش تا هشت هفته ایدهپردازی کنند.

۱۹۵۸
Frank Rosenblatt تلاش کرد اولین شبکه عصبی کامپیوتری به نام پرسپترون (Perceptron) را طراحی کند. پرسپترون توانایی یادگیری واقعی برای انجام طبقهبندی باینری بهتنهایی را داشت و برای دریافت ورودیها و ایجاد خروجیهایی مانند برچسبها و دستهبندیها ساخته شده بود.

1963
Donald Michie با 304 جعبه چوب کبریت توانست برنامهای توسعه دهد که این قابلیت را داشت که بازی tic-tac-toe (بازی دوز) را بیاموزد.

1965
Alexey Ivakhnenko و Valentin Lapa نمایش سلسلهمراتبی شبکه عصبی که بهعنوان اولین پرسپترون چندلایه شناخته میشود را توسعه دادند. این نمایش از تابع فعالساز غیرخطی استفاده میکرد و با استفاده از روش گروهی مدلسازی دادهها آموزش دیده بود.
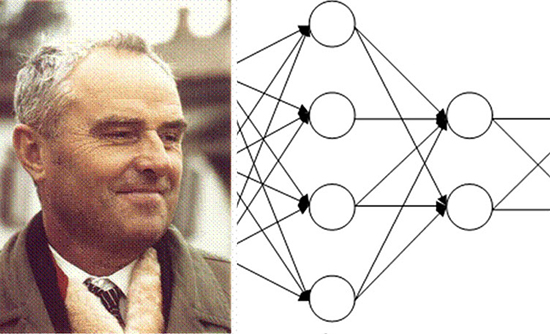
1967
Thomas Cover و Peter E. Hart مقالهای در IEEE Transactions on Information Theory درباره الگوریتم نزدیکترین همسایه (Nearest Neighbor Algorithm) منتشر کردند. الگوریتم نزدیکترین همسایه به رایانهها اجازه میدهد تا از تشخیص الگوی بسیار ابتدایی استفاده کنند. هنگامی که به برنامه یک نمونه جدید داده میشد، آن را با دادههای موجود مقایسه و در نزدیکترین همسایه – یعنی شبیهترین نمونه در حافظه – طبقهبندی میکرد.

۱۹۸۰
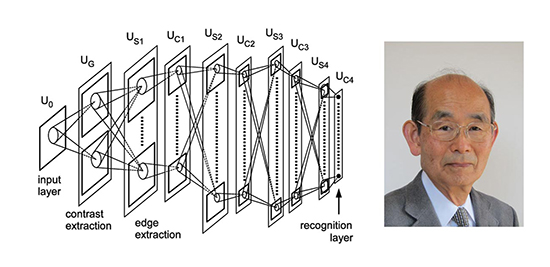
Kunihiko Fukushima، دانشمند علوم کامپیوتر ژاپنی، کار خود را بر روی Neocognitron منتشر کرد. یک شبکه عصبی مصنوعی سلسلهمراتبی و چندلایه که برای شناسایی الگوها مانند تشخیص کاراکترهای دستنویس طراحی شده بود و منجر به ایجاد شبکههای عصبی کانولوشن شد که امروزه برای تجزیهوتحلیل تصاویر از آنها استفاده میشود.
1979
دانشجویان دانشگاه استنفورد، Stanford Cart که یک ربات کنترل ازراهدور بود را ساختند. این ربات میتوانست با نقشهبرداری و مسیریابیِ سهبعدی به طور مستقل در فضا حرکت کند و از موانع موجود بهتنهایی عبور کند.

۱۹۸۶
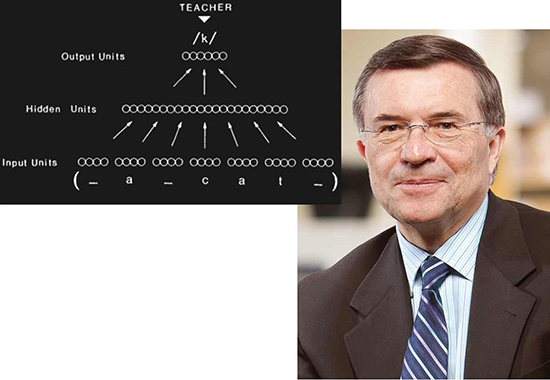
Terrence Sejnowski با ترکیب دانش خود در زیستشناسی و شبکههای عصبی NETtalk را ایجاد کرد؛ یک شبکه عصبی که میتوانست یاد بگیرد کلمات انگلیسی را با مطابقت و مقایسه با رونوشتهای آوایی تلفظ کند.
1986
Paul Smolensky یک ماشین بولتزمن محدودشده (Restricted Boltzmann machine) معرفی کرد که میتوانست مجموعهای از ورودیها را تحلیل کرده و توزیع احتمال را از آنها بیاموزد. این الگوریتم در مدلسازیهای موضوع – به عنوان مثال، تعیین موضوعات احتمالی یک مقاله بر اساس محبوبترین کلمات در آن – یا توصیههای مبتنی بر هوش مصنوعی استفاده میشود.
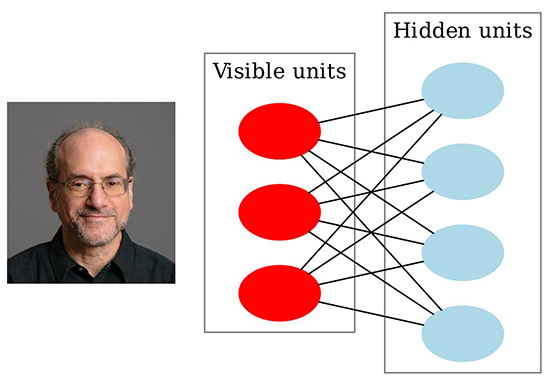
1990
Robert Schapire در مقالهای به نام «The Strength of Weak Learnability»، الگوریتم بوستینگ (Boosting) را معرفی میکند؛ الگوریتمی که هدف آن افزایش قدرت پیشبینی یک مدل هوش مصنوعی است. بوستینگ به جای استفاده از یک مدل قوی، مدلهای ضعیف زیادی را تولید میکند و با ترکیب پیشبینیها، آنها را به مدلهای قویتری تبدیل میکند.

1995
Tin Kam Ho، دانشمند کامپیوتری که برای IBM کار میکرد، مقالهای تأثیرگذار در مورد جنگلهای تصمیم تصادفی (Random Decision Forests) – یک روش یادگیری جمعی – منتشر کرد. این الگوریتم چندین درخت تصمیم را ایجاد و در یک «جنگل» ادغام میکند. با استفاده از چندین درخت تصمیمگیری مختلف، بهطور قابلتوجهی دقت و تصمیمگیری مدل، بهبود پیدا میکند.

1997
Deep Blue، یک برنامه کامپیوتری بازی شطرنج که توسط IBM ساخته شده بود، Garry Kasparov، قهرمان شطرنج جهان در آن زمان را شکست داد و تاریخساز شد؛ Kasparov در دو بازی اول پیروز شد، سه بازی بعد را باخت و در بازی پایانی به تساوی رسید.

برنامه Video Rewrite توسط Christoph Bregler، Michele Covell و Malcolm Slaney توسعه داده شد. این برنامه فیلم ویدیوئی موجود از فردی که در حال صحبت کردن بود را تغییر میداد تا آن شخص را در حال بیان کلمات موجود در یک فایل صوتی دیگر به تصویر بکشد.
2006
Geoffrey Hinton و همکارانش در مقالهای با عنوان «A fast learning algorithm for deep belief nets»، اصطلاح یادگیری عمیق (Deep Learning) را برای توصیف الگوریتمهایی وضع کردند که به رایانهها در تشخیص انواع مختلف اشیاء و کاراکترهای متن در تصاویر و فیلمها کمک میکرد.

2009
یک پایگاه داده تصویری عظیم از تصاویر برچسبگذاریشده به نام ImageNet توسط Fei-Fei Li راهاندازی شد. او میخواست دادههای موجود برای الگوریتمهای آموزشی را گسترش دهد، زیرا معتقد بود که هوش مصنوعی و یادگیری ماشین باید دادههای آموزشی خوبی داشته باشند تا بتوانند واقعاً کاربردی و مفید باشند.
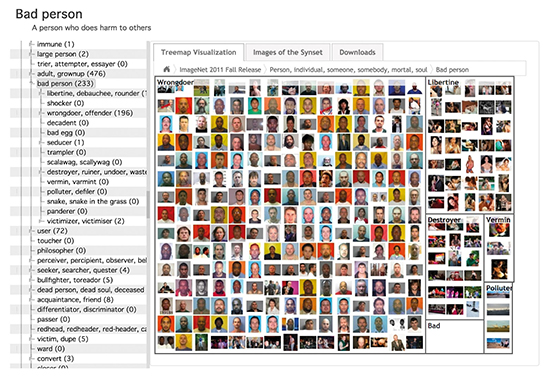
2012
تیم آزمایشگاه X در گوگل با داشتن پیشینه یادگیری ماشین گسترده، یک شبکه عصبی به نام Google Brain ایجاد کردند که در توانایی پردازش تصویر بسیار شناخته شد و قادر بود گربهها و صورت و بدن انسان را با دقت خوبی در تصاویر شناسایی کند.

بیشتر بخوانید: پردازش تصویر چیست و چه کاربردهایی دارد؟
2014
تیم تحقیقاتی فیسبوک DeepFace – یک سیستم تشخیص چهره مبتنی بر یادگیری عمیق – را توسعه میدهد. یک شبکه عصبی ۹لایهای که با 4 میلیون تصویر از کاربران فیسبوک آموزش داده شده بود. DeepFace قادر بود چهره انسان را در تصاویر با همان دقتی که انسان انجام میدهد (تقریباً 97.35٪) تشخیص دهد.

2014
Eugene Goostman که توسط سه دوست برنامهنویس به نام Vladimir Veselov ،Eugene Demchenko و Sergey Ulasen توسعه داده شده بود، در یک مسابقه تست تورینگ در انجمن سلطنتی، پس از اینکه 33 درصد از داوران را متقاعد کرد که یک انسان است، برنده شد.

۲۰۱۶
AlphaGo در بازی Go که بهعنوان یکی از پیچیدهترین بازیهای رومیزی شناخته میشود، Lee Sedol، بازیکن حرفهای Go را چهار بر یک شکست داد. بازیکنان حرفهای Go تأیید کردند که این الگوریتم قادر به انجام حرکات خلاقانهای است که قبلاً هرگز ندیده بودند.

2016
گروهی از دانشمندان، Face2Face را در کنفرانس بینایی کامپیوتری و تشخیص الگو معرفی کردند. Face2Face قادر بود ویدئوها را درلحظه ویرایش و حرکات صورت یک شخص را روی صورت فردی دیگر جایگزین کند طوری که انگار شخص موردنظر در ویدئو چیزی را میگوید که در واقع نگفته است. منطق و الگوریتمهای Face2Face اساس اکثر نرمافزارهای Deepfake امروزی است.

2017
Waymo شروع به آزمایش خودروهای خودران در ایالات متحده کرد و در اواخر همان سال نیز اولین سرویس حملونقل خودکار تجاری در جهان را در شهر فینیکس با نام Waymo One عرضه کرد.

2020 و پس از آن
در سال 2020، فیسبوک، یادگیری مبتنی بر باور بازگشتی (Recursive Belief-based Learning) یا ReBeL را معرفی کرد؛ یک الگوریتم با ظرفیت کار در همه بازیهای دونفره و مجموع صفر (zero-sum) و حتی بازیهایی که اطلاعات ناقصی دارند. Deepmind همچنین الگوریتم Player of Games را در سال ۲۰۲۱ معرفی کرد.
AlphaFold که توسط گوگل توسعه یافته است، در سال 2021 به سطحی از دقت بسیار بالایی در پیشبینی ساختار پروتئینها دست یافت. گوگل همچنین مقالهای با عنوان Switch Transformers را در سال ۲۰۲۲ منتشر کرد و در آن تکنیکی مبتنی بر یک الگوریتم اصلاحشده برای آموزش مدلهای زبانی با بیش از یک تریلیون پارامتر ارائه کرد.
محققان بیشماری وجود دارند که دستاوردهای آنها، مستقیم یا غیرمستقیم به ظهور و رونق یادگیری ماشین کمک کرده است. این مقاله تنها سعی داشت با مرور برخی از لحظات و رویدادهای کلیدی، تاریخچه مختصری از یادگیری ماشین را بازگو کند.