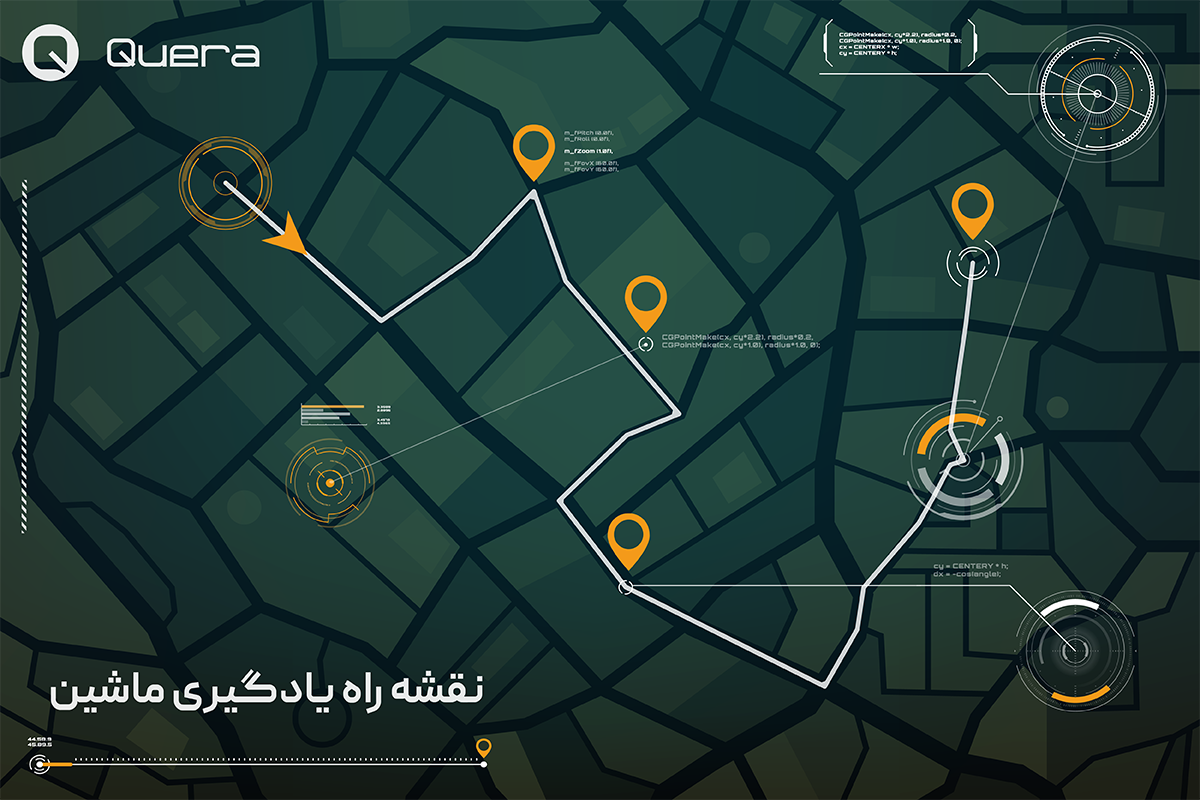
نقشه راه یادگیری ماشین
یادگیری ماشین حوزهی وسیعی است که موضوعات زیادی برای یادگیری دارد. به همین دلیل بسیاری از افراد در شروع مسیر یادگیری ماشین دچار سردرگمی میشوند و نمیدانند که باید از کجا شروع کنند. بهترین راه برای شروع این سفر یادگیری، داشتن نقشه راه یادگیری ماشین است که شما را قدمبهقدم تا تبدیل شدن به یک متخصص یادگیری ماشین راهنمایی کند.
در ادامه یک نقشه راه جامع و ساختاریافته برای تسلط بر یادگیری ماشین ارائه کردهایم. اما قبل از ارائهی نقشه راه یادگیری ماشین، بهطور خلاصه بررسی میکنیم که ایدهی کلی یادگیری ماشین چیست و چرا استفاده از آن اهمیت دارد.
شروع آموزش یادگیری ماشین
اگر به یادگیری ماشین علاقهمند هستید، دورههای یادگیری ماشین کوئراکالج گزینه خوبی برای شروع مسیر شغلی شما در این حوزه خواهند بود. کوئراکالج در قالب سه دورهی یادگیری ماشین، شما را قدمبهقدم از سطح ابتدایی تا پیشرفتهی یادگیری ماشین راهنمایی میکند. برای آشنایی بیشتر با مقدمات یادگیری ماشین و هوش مصنوعی میتوانید همین حالا بهصورت رایگان در دورهی «یادگیری ماشین ۰ | دروازه ورود به یادگیری ماشین» ثبتنام کنید.
پس از این دوره میتوانید با دورهی «یادگیری ماشین ۱ | تحلیل داده با پایتون» وارد دنیای تحلیل داده شوید و در نهایت برای یادگیری و رشد بیشتر در زمینهی یادگیری ماشین و حل چالشهای واقعی، در دورهی «یادگیری ماشین ۲ | جامپ تکنیکال» شرکت کنید. شما در روند یادگیری میتوانید از مربیهای کوئراکالج کمک بگیرید و با حل تمرینها و انجام پروژههای مختلف دانش خود را تثبیت کرده و همزمان با چالشهای واقعی در صنعت آشنا شوید.
یادگیری ماشین چیست؟
یادگیری ماشین (Machine Learning) زیرمجموعهای از هوش مصنوعی و حوزهای از علوم محاسباتی است که بر تجزیهوتحلیل و تفسیر الگوها و ساختار دادهها تمرکز دارد. به زبان ساده، یادگیری ماشین زمینهای از علوم کامپیوتر است که این امکان را فراهم میکند تا ماشین بتواند بهتنهایی و بدون اینکه صریحاً برنامهنویسی شده باشد، یاد بگیرد. بنابراین بهجای اینکه کد هر بار برای یک مسئلهی جدید نوشته شود، الگوریتم با دادهها تغذیه میشود. سپس الگوریتم دادهها را تجزیهوتحلیل کرده و توصیهها و تصمیماتی را تنها بر اساس دادههای ورودی و بدون دخالت انسان ارائه میکند.

الگوریتمهای یادگیری ماشین درست مانند انسانها میتوانند از تجربیات گذشته خود یاد بگیرند! هنگامی که دادههای جدید به آنها داده میشود، این الگوریتمها یاد میگیرند، تغییر میکنند و بدون نیاز به تغییر هربارهی کد، رشد میکنند. ممکن است در ابتدا نتایج بهدستآمده از دقت بالایی برخوردار نباشند، اما الگوریتمهای یادگیری ماشین میتوانند از دادههای خروجی خود برای بهبود نتایج در آینده استفاده کنند.
بیشتر بخوانید: یادگیری ماشین (Machine Learning) چیست؟
اهمیت یادگیری ماشین
راهحلهای یادگیری ماشین همچنان در فرایندهای اصلی کسبوکارها تغییرات مهمی ایجاد میکنند و در زندگی روزمره ما رایجتر میشوند. در حال حاضر بسیاری از شرکتها استفاده از یادگیری ماشین را به دلیل پتانسیل بالای آن برای پیشبینیهای دقیقتر و تصمیمگیریهای تجاری آغاز کردهاند. پیشبینی میشود بازار جهانی یادگیری ماشین از 8.43 میلیارد دلار در سال 2019 به 117.19 میلیارد دلار تا سال 2027 افزایش یابد.
یادگیری ماشین همچنین پتانسیل تحقیقاتی بالایی دارد. در حال حاضر یکی از موضوعات داغ در مقالات تحقیقاتی حوزهی علوم کامپیوتر، یادگیری ماشین است و از آن در صنایع و زمینههای تحقیقاتی مختلفی استفاده میشود. با این سرعت و افزایش نفوذ در بازار، یادگیری ماشین آینده درخشانی خواهد داشت.
نقشه راه یادگیری ماشین
اکنون که با ایدهی کلی حوزهی یادگیری ماشین و اهمیت آن آشنا شدید، وقت آن است که قدمبهقدم مسیر تبدیل شدن به یک متخصص یادگیری ماشین را بررسی کنیم. امیدواریم که این نقشه راه به شما کمک کند تا مسیر یادگیری و تسلط بر یادگیری ماشین را بدون سردرگمی و با اعتمادبهنفس بیشتری طی کنید.
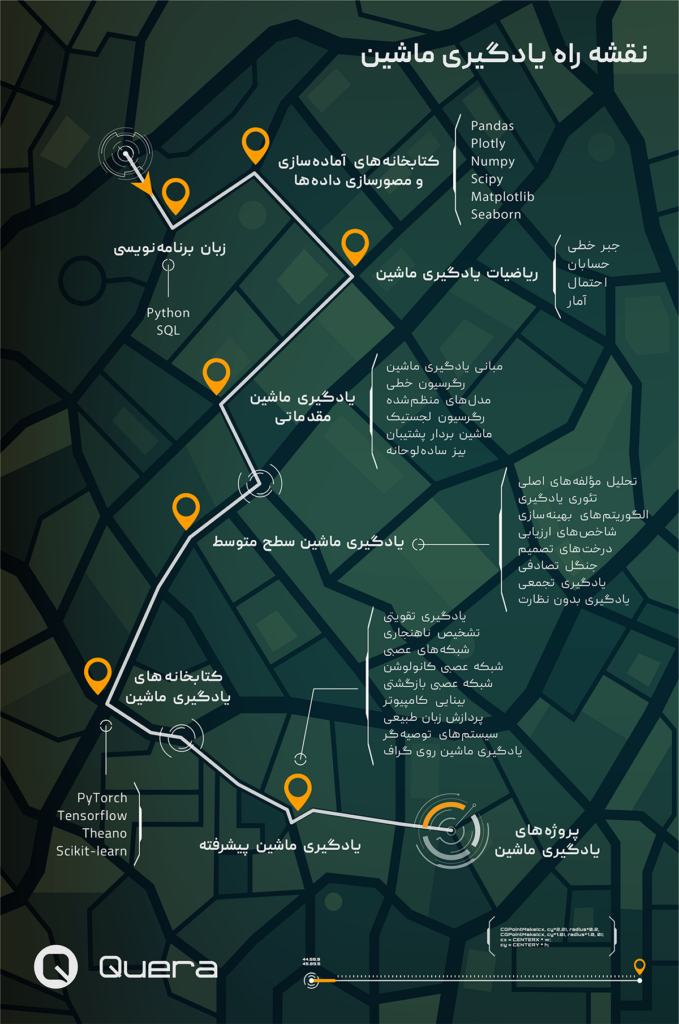
قدم اول: زبان برنامهنویسی
اگر میخواهید به یک متخصص یادگیری ماشین تبدیل شوید، باید مهارتهای برنامهنویسی خود را توسعه دهید. بنابراین قدم اول، انتخاب یک زبان برنامهنویسی است. اما با وجود زبانهای برنامهنویسی مختلف که بهطور گسترده مورد استفاده قرار میگیرند و هرکدام مزایا و معایب خود را دارند، انتخاب بهترین زبان برای یادگیری ماشین قطعاً کار دشواری است.
در مقاله بهترین زبانهای برنامهنویسی برای یادگیری ماشین، تلاش کردیم تا برخی از آنها را معرفی کنیم، با این حال توصیهی ما به شما این است که پایتون را برای یادگیری انتخاب کنید. در حال حاضر، پایتون محبوبترین زبان در حوزهی یادگیری ماشین است. یکی از دلایل محبوبیت پایتون در این حوزه، مجموعهی وسیع کتابخانههای آن است. در واقع بسیاری از کتابخانههای پایتون بهطور خاص برای هوش مصنوعی و یادگیری ماشین ایجاد شدهاند که این ویژگی کار شما را در پروژههای یادگیری ماشین بسیار آسان میکند. از این گذشته به لطف سینتکس سادهی پایتون بهسرعت میتوانید آن را فرا بگیرید.

زبان برنامهنویسی دیگری که باید برای کار در حوزهی داده یاد بگیرید SQL است. SQL زبان برنامهنویسی استاندارد برای بسیاری از سیستمهای پایگاه داده است. بنابراین متخصصان یادگیری ماشین برای مدیریت دادههای ذخیرهشده در پایگاههای دادهی رابطهای نیاز به دانش عمیق SQL دارند.
قدم دوم: کتابخانههای آمادهسازی داده و مصورسازی
فرایند آمادهسازی و مصورسازی دادهها بخش مهمی از فرایندهای یادگیری ماشین است. هدف از آمادهسازی و مصورسازی دادهها، سازماندهی، تبدیل و نگاشت دادهها از فرم خام به شکلی است که برای تجزیهوتحلیل قابل استفاده شوند. اگر زبان برنامهنویسی پایتون را برای کار با پروژههای یادگیری ماشین و یادگیری عمیق انتخاب کردهاید، کتابخانههای پایتون زیادی وجود دارد که میتوانید از آنها برای آمادهسازی و مصورسازی دادهها استفاده کنید. در ادامه لیستی از بهترین کتابخانههای پایتون برای این منظور پیشنهاد شده است:
- Pandas
- Plotly
- Numpy
- Scipy
- Matplotlib
- Seaborn
چیزی که یک متخصص یادگیری ماشین معمولی را از یک حرفهای متمایز میکند، کیفیت مهندسی ویژگیها و آمادهسازی دادهها است. بنابراین هرچه زمان بیشتری را برای تسلط به ابزارها و مباحث در این مرحله اختصاص دهید، نهتنها پیشزمینهای قویتر برای پیشرفت در آینده، بلکه ارزش بیشتری برای کارفرمایان خواهید داشت.
قدم بعدی در نقشه راه یادگیری ماشین، بررسی ریاضیات مربوط به الگوریتمهای آن است؛ که بهتر است کمی بیشتر درمورد آن صحبت کنیم.
قدم سوم: ریاضیات یادگیری ماشین
درک ریاضیات نهفته در الگوریتمهای یادگیری ماشین، یک توانمندی بارز به شمار میرود. اگر بخواهید فراتر از عملکردهای پایهی یادگیری ماشین کار کنید، نیاز به آشنایی با جزئیات ریاضیات یادگیری ماشین دارید. حتی اگر مبتدی هستید و لزوماً تحصیلات خاصی در ریاضیات پیشرفته ندارید، با یک برنامهریزی میتوانید مباحث موردنیاز را بهراحتی یاد بگیرید.
برای شروع، درک کلی از این مباحث کافی است. بنابراین توصیه میکنیم بهجای اینکه سعی کنید قبل از ورود به مباحث تخصصی یادگیری ماشین به ریاضیات یادگیری ماشین تسلط کامل پیدا کنید، در حین کار با الگوریتمها و مدلهای یادگیری ماشین ریاضیات موردنیاز را در عمل تمرین کنید.
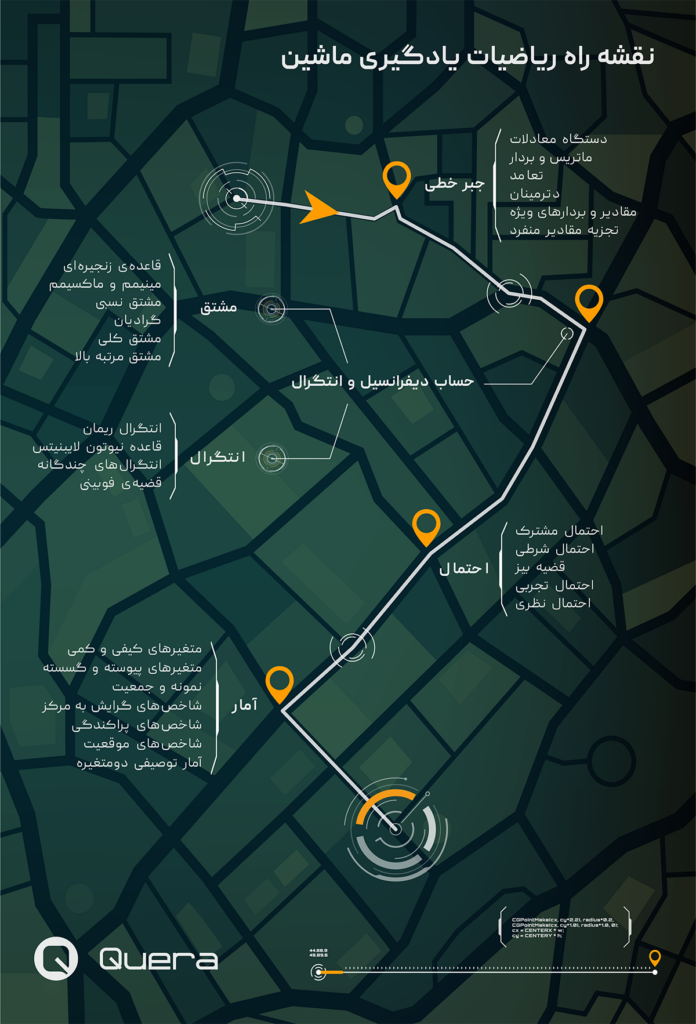
جبر خطی
جبر خطی برای درک و کار با بسیاری از الگوریتمهای یادگیری ماشین ضروری است. این مفهوم، به شما درک بهتری از نحوهی عملکرد الگوریتمها میدهد و به شما این امکان را میدهد تا بتوانید تصمیمات بهتری بگیرید. بنابراین اگر واقعاً میخواهید در این زمینه حرفهای شوید، نمیتوانید از تسلط بر مفاهیم جبر خطی فرار کنید.
حساب دیفرانسیل و انتگرال
حساب دیفرانسیل و انتگرال یکی از مفاهیم اصلی ریاضی در یادگیری ماشین است که شما را قادر میسازد تا عملکرد درونی الگوریتمهای مختلف یادگیری ماشین را درک کنید. این مفاهیم، نقش مهمی در ساخت، آموزش و بهینهسازی الگوریتمهای یادگیری ماشین ایفا میکنند. با وجود اینکه در یادگیری ماشین بهندرت کدی برای محاسبهی مشتق یا انتگرال نوشته میشود، اما الگوریتمهایی که استفاده میکنیم ریشههای نظری در حساب دیفرانسیل و انتگرال دارند.
آمار و احتمال
آمار و احتمال دو مورد از ابزارهای اصلی هر دانشمند داده یا متخصص یادگیری ماشین هستند. بدون داشتن درک درست از آنها تقریباً غیرممکن است که بفهمیم الگوریتمها و مدلهای ما چگونه کار میکنند و چه چیزی به ما میگویند. هر پروژهی یادگیری ماشین دو مرحلهی مهم را شامل میشود؛ اولین مورد درک مجموعهداده است و اینجاست که به دانش آمار نیاز داریم و مورد دوم، پیشبینی احتمال وقوع یک رویداد است. این نشان میدهد که چقدر دانش آمار و احتمال برای انجام پروژههای یادگیری ماشین اهمیت دارد.
قدم چهارم: یادگیری ماشین مقدماتی
اکنون که با پیشنیازها در نقشه راه یادگیری ماشین آشنا شدهاید، وقت آن است که به سراغ یادگیری ماشین برویم. بهتر است از اصول اولیه شروع کرده و سپس به موارد پیچیدهتر بروید. برخی از مفاهیم مهم یادگیری ماشین در سطح مقدماتی عبارتاند از:
مبانی یادگیری ماشین
برای شروع شما باید درکی کلی درمورد مفهوم یادگیری ماشین و نحوهی کار آن، انواع الگوریتمهای یادگیری ماشین (یادگیری نظارتشده، یادگیری بدون نظارت و یادگیری تقویتی)، فرایندهای یادگیری ماشین و چالشهای این حوزه داشته باشید.
رگرسیون خطی (Linear Regression)
یکی از ابتداییترین الگوریتمهای یادگیری ماشین، رگرسیون خطی است که پایهای برای یادگیری و ایجاد سایر الگوریتمهای یادگیری ماشین فراهم میکند. رگرسیون خطی روشی برای مدلسازی رابطهی بین یک متغیر وابسته و یک یا چند متغیر دیگر است که میتواند به شما در حل بسیاری از مشکلات دنیای واقعی کمک کند.
مدلهای منظمشده (Regularized Linear Models)
مدلهای پیچیده میتوانند یک الگوی ظریف را در دادهها تشخیص دهند، اما اگر دادهها دارای نویز باشند یا مجموعهداده خیلی کوچک باشد، مدل در نهایت الگو را در نویزها تشخیص میدهد. بنابراین خطا بیش از خطای موردانتظار خواهد بود و نتایج استفاده از این مدلها برای پیشبینی دقیق نیست. برای بهبود مدل یا کاهش اثر نویز، باید وزنهای مرتبط با نویز را کاهش دهیم. به کمک مدلهای منظمشده، وزن نویز سهم کمتری در خروجی مدل خواهد داشت.
رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک معروفترین الگوریتم یادگیری ماشین بعد از رگرسیون خطی است. از بسیاری جهات، رگرسیون خطی و رگرسیون لجستیک مشابه هم هستند، اما از الگوریتمهای رگرسیون خطی برای برازش استفاده میشود، در حالی که رگرسیون لجستیک در طبقهبندی دادهها کاربرد دارد. بهعنوان مثال طبقهبندی اینکه آیا یک ایمیل هرزنامه است یا نه، طبقهبندی بدخیم یا خوشخیم بودن یک تومور، طبقهبندی اینکه آیا یک وبسایت تقلبی است یا خیر و…
ماشین بردار پشتیبان (Support Vector Machine)
این الگوریتم، یکی دیگر از الگوریتمهایی است که هر متخصص یادگیری ماشین باید در مجموعه مهارتهای خود داشته باشد. ماشین بردار پشتیبان میتواند در فرایندهای رگرسیون و بهطور گسترده در طبقهبندی استفاده شود. بهعنوان مثال یک ماشین بردار پشتیبان میتواند با بررسی صدها یا هزاران گزارش فعالیت کارتهای اعتباری جعلی و غیرجعلی، فعالیتهای جعلی کارتهای اعتباری را شناسایی کند.
بیز سادهلوحانه (Naive Bayes)
سادهترین راهحلها معمولاً بهترین راهحلها هستند و بیز سادهلوحانه مثال خوبی برای این نوع راهحلها است. مدلهای بیز سادهلوحانه، گروهی از الگوریتمهای طبقهبندی بسیار سریع، ساده و مناسب برای مجموعهدادهها با ابعاد بسیار بالا هستند. علیرغم پیشرفتهای یادگیری ماشین در سالهای اخیر، بیز سادهلوحانه هنوز هم یک روش ساده و سریع برای بسیاری از مسائل یادگیری ماشین است.
قدم پنجم: یادگیری ماشین سطح متوسط
در قدم پنجم از نقشه راه یادگیری ماشین، باید از مسیر مفاهیم زیر بگذریم:
تحلیل مؤلفههای اصلی (Principal Component Analysis)
برای تفسیر مجموعهدادههای بزرگ باید ابعاد آنها را بهروشی قابلتفسیر کاهش داد، بهطوری که اطلاعات موجود در دادهها حفظ شود. تکنیکهای زیادی برای این منظور توسعه داده شده است، اما تحلیل مؤلفههای اصلی یکی از قدیمیترین و پرکاربردترین آنهاست. تحلیل مؤلفههای اصلی تکنیکی برای کاهش ابعاد مجموعهدادهها، افزایش تفسیرپذیری آنها و در عین حال حفظ اطلاعات مهم است.
تئوری یادگیری (Learning Theory)
تئوری یادگیری محاسباتی (Computational Learning Theory) علاوه بر فراهمکردن یک چارچوب برای فرمولبندی دقیق و پاسخگویی به سؤالات درمورد عملکرد الگوریتمهای مختلف، امکان مقایسهی کامل ظرفیت پیشبینی و کارایی محاسباتی الگوریتمهای جایگزین را نیز فراهم میکند.
الگوریتمهای بهینهسازی (Optimization Algorithms)
هدف اصلی یادگیری ماشین ایجاد مدلی است که عملکرد خوبی داشته باشد و پیشبینیهای دقیقی ارائه دهد. برای این منظور به بهینهسازی الگوریتمهای یادگیری ماشین نیاز داریم. بهینهسازی الگوریتمهای یادگیری ماشین فرایند تنظیم پارامترهای مدل بهمنظور به حداقل رساندن تابع هزینه با استفاده از یکی از تکنیکهای بهینهسازی است.
شاخصهای ارزیابی (Evaluation Metrics)
ارزیابی مدلهای یادگیری ماشین یکی از ضروریترین قسمتهای هر پروژهی یادگیری ماشین است. شاخصهای ارزیابی به ما کمک میکنند تا دقت و عملکرد مدل را قبل از استفاده از آن بر روی دادههای دیدهنشده ارزیابی کرده و در صورت لزوم بهبود دهیم.
درختهای تصمیم (Decision Trees)
درخت تصمیم بخش مهمی از جعبهابزار یک دانشمند داده است. الگوریتمهای درخت تصمیم ابزاری قدرتمند برای طبقهبندی و برازش دادهها و ارزیابی هزینهها، خطرات و مزایای احتمالی هستند. به کمک درخت تصمیم میتوان رویکردی اصولی و به دور از سوگیری برای تصمیمگیری داشت. درختهای تصمیم همچنین گزینههای در دسترس را در قالبی ارائه میدهند که بهسادگی قابل تفسیر است.
جنگل تصادفی (Random Forest)
یکی از تکنیکهای پیشرفتهی یادگیری ماشین، جنگل تصادفی است که از مجموعهای از درختهای تصمیم تشکیل شده است. از جنگل تصادفی اغلب برای حل مشکلات رگرسیونی و طبقهبندی دادهها استفاده میشود.
یادگیری تجمعی (Ensemble Learning)
مجموعهای از مدلها، دقیقتر از مدلهای منفرد عمل میکنند. بنابراین هر زمان که نیاز به دقت پیشبینی خوبی باشد، از یادگیری تجمعی استفاده میشود. روشهای یادگیری تجمعی شامل الگوریتمهایی هستند که چندین تکنیک یادگیری ماشین را در یک مدل ترکیب میکنند تا واریانس، سوگیری و انباشتگی را کاهش دهند.
یادگیری بدون نظارت (Unsupervised Learning Algorithm)
الگوریتمهای بدون نظارت امکان انجام تحلیلهای پیچیدهتری را نسبت به الگوریتمهای نظارتشده فراهم میکنند. آنها الگوهای پنهان در دادههای بدون برچسب را کشف میکنند. توانایی یادگیری بدون نظارت در کشف شباهتها و تفاوتهای اطلاعات، آن را به راهحلی ایدئال برای تجزیهوتحلیل دادههای اکتشافی، استراتژیهای فروش و طبقهبندی مشتریان تبدیل کرده است.
قدم ششم: کتابخانههای یادگیری ماشین
قدم ششم در نقشه راه یادگیری ماشین، یادگیری کتابخانههای یادگیری ماشین است.به لطف این کتابخانهها، ماژولها و فریمورکهای گستردهی یادگیری ماشین، دورانی که افراد مجبور بودند همهی الگوریتمهای یادگیری ماشین را خودشان از ابتدا کدنویسی کنند، گذشته است. کتابخانههای یادگیری ماشین شامل توابع و روشهایی هستند که مقیاسبندی محاسبات علمی و عددی را برای سادهسازی فرایندهای یادگیری ماشین امکانپذیر میکنند تا بتوان مدلهای یادگیری ماشین را در زمان کمتر و بدون واردشدن به پیچیدگیهای الگوریتمهای پایه طراحی کرد.
پایتون کتابخانههای یادگیری ماشین بسیاری را برای عملیاتهای مختلف یادگیری ماشین در اختیار افراد فعال در این حوزه گذاشته است. در ادامه تعدادی از معروفترین کتابخانههای پایتون برای یادگیری ماشین و یادگیری عمیق را معرفی کردهایم:
Pytorch
Pytorch یک کتابخانهی پایتون بسیار محبوب است که عموماً در مفاهیم یادگیری عمیق استفاده میشود. از Pytorch که توسط یک جامعهای گسترده از متخصصان یادگیری ماشین پشتیبانی میشود، بیشتر در بهینهسازی و تقویت عملکرد فریمورکهای یادگیری عمیق استفاده میشود.
Tensorflow
Tensorflo در Differentiable Programming تخصص دارد، به این معنی که میتواند بهطور خودکار مشتقات یک تابع را در زبان سطح بالا محاسبه کند. هر دو مدل یادگیری ماشین و یادگیری عمیق بهراحتی با معماری و فریمورک انعطافپذیر TensorFlow قابل توسعه و ارزیابی هستند. از TensorFlow میتوان برای مصورسازی مدلهای یادگیری ماشین نیز استفاده کرد.
Theano
این کتابخانه، تقریباً تنها توسط توسعهدهندگان یا برنامهنویسان یادگیری ماشین و یادگیری عمیق استفاده میشود. این کتابخانه بهطور خاص برای بهینهسازی و ارزیابی مدلهای ریاضی و محاسبات ماتریسی که از آرایههای چندبعدی برای ایجاد مدلهای یادگیری ماشین استفاده میکنند ساخته شده است.
Scikit-Learn
Scikit-Learn یک کتابخانه یادگیری ماشین بسیار محبوب و با محیط کاربرپسند است که بر اساس NumPy و SciPy ساخته شده است. این کتابخانه از اکثر الگوریتمهای کلاسیک یادگیری نظارتشده و بدون نظارت پشتیبانی میکند. از Scikit-learn همچنین میتوان برای دادهکاوی، مدلسازی و تجزیهوتحلیل دادهها استفاده کرد. توصیه میکنیم که یادگیری این کتابخانه را در قدم چهارم، یعنی زمانی که در حال یادگیری مفاهیم و تکنیکهای اولیهی یادگیری ماشین هستید، شروع کنید.
قدم هفتم: یادگیری ماشین پیشرفته
اکنون که بیشتر تکنیکهای یادگیری ماشین را یاد گرفتهاید، در هفتمین قدم از نقشه راه یادگیری ماشین، زمان آن رسیده است که تکنیکهای پیشرفتهی یادگیری ماشین مانند یادگیری عمیق و یادگیری ماشین با دادههای بزرگ بررسی کنید:
یادگیری تقویتی (Reinforcement learning)
دانشمندان داده معمولاً از یادگیری ماشین تقویتی برای انجام یک فرایند چندمرحلهای که قوانین مشخصی برای آن وجود دارد، استفاده میکنند. آنها الگوریتم را برای انجام چیزی برنامهنویسی میکنند و در حالی که الگوریتم در تلاش برای انجام آن است، نشانههای مثبت یا منفی را به آن ارائه میکنند. وقتی مدل نتیجهای را پیشبینی یا تولید میکند، در صورت اشتباهبودنِ پیشبینی جریمه میشود و در صورت صحت پیشبینی پاداش میگیرد و بر این اساس، مدل خود را آموزش میدهد.
تشخیص ناهنجاری (Anomaly Detection)
به هر فرایندی که بتواند نقاط پرت یک مجموعهداده را پیدا کند، تشخیص ناهنجاری گفته میشود. از تشخیص ناهنجاری میتوان برای شناسایی ترافیک غیرمعمول شبکه یا برای تمیز کردن دادهها قبل از تحلیل استفاده کرد. نقاط پرت یک مجموعهداده معمولاً بهصورت مشکلاتی مانند کلاهبرداری از کارت اعتباری، خرابی دستگاه در سرور، حمله سایبری و… ترجمه میشوند.
شبکههای عصبی (Neural Networks)
Neural Networks یا شبکههای عصبی، که با نامهای شبکههای عصبی مصنوعی یا شبکههای عصبی شبیهسازیشده نیز شناخته میشوند، زیرمجموعهای از یادگیری ماشین و مبنای الگوریتمهای یادگیری عمیق هستند. شبکههای عصبی مجموعهای از الگوریتمها هستند که بر اساس مغز انسان مدلسازی و برای تشخیص الگوها طراحی شدهاند.
شبکه عصبی کانولوشن (Convolutional Neural Network)
شبکههای عصبی کانولوشن از معماری مغز الهام گرفتهاند. درست مانند نورونها در مغز که اطلاعات را در سراسر بدن پردازش و منتقل میکنند، گرههای مصنوعیِ شبکههای عصبی کانولوشن نیز ورودیها را دریافت و پردازش کرده و نتیجه را بهعنوان خروجی ارسال میکنند. از شبکههای عصبی کانولوشن بهطور گسترده برای تشخیص و طبقهبندی تصویر و اشیا استفاده میشود.
شبکه عصبی بازگشتی (Recurrent Neural Network)
در بسياری از شبكههای عصبی مانند شبکههای عصبی کانولوشن، سيگنال فقط در يک جهت از لايه ورودی، به لايههای مخفی و سپس به لايهی خروجی حركت میكند و دادههای قبلی به حافظه سپرده نمیشوند. اما شبكههای عصبی بازگشتی شامل يک حلقهی بازگشتی هستند كه موجب میشود اطلاعات قبلی از بين نروند و در شبكه باقی بمانند. از شبکه عصبی بازگشتی در مواردی مانند زمانی که لازم است کلمهی بعدی یک جمله پیشبینی شود استفاده میشود.
بینایی کامپیوتر (Computer Vision)
همان طور که هوش مصنوعی رایانهها را قادر میسازد تا فکر کنند، بینایی کامپیوتر آنها را قادر میسازد که ببینند، مشاهده کنند و بفهمند. بینایی کامپیوتری حوزهای از هوش مصنوعی است که رایانهها و سیستمها را قادر میسازد تا اطلاعات معناداری را از تصاویر دیجیتال، فیلمها و سایر ورودیهای بصری استخراج کرده و بر اساس آنها اقداماتی انجام داده یا توصیههایی را ارائه دهند.
پردازش زبان طبیعی (Natural Language Processing)
پردازش زبان طبیعی (NLP) زیرشاخهای از یادگیری ماشین است که درک، تجزیهوتحلیل، دستکاری و تولید زبان انسانی را برای رایانهها ممکن میسازد. این فناوریها در کنار هم، رایانهها را قادر میسازند تا زبان انسان را بهصورت متن یا دادههای صوتی پردازش کنند و معنای کامل آن را کاملاً با هدف و احساسات گوینده یا نویسنده درک کنند.
سیستمهای توصیهگر (Recommendation Systems)
سیستمهای توصیهگر، موتورهای قدرتمندی هستند که از الگوریتمها و تکنیکهای یادگیری ماشین استفاده میکنند تا بر اساس الگوهای رفتاری کاربران مانند تاریخچهی خرید و جستوجو، لایکها یا نظرات، علایق و ترجیحات آنها را پیشبینی کرده و مرتبطترین پیشنهادها را ارائه کنند.
یادگیری ماشین روی گراف (Graph Machine Learning)
این شاخه بر چگونگی به دست آوردن ویژگیهای مبتنی بر گرافها و توسعهی الگوریتمهایی که ساختار یک گراف را در نظر میگیرند، تمرکز دارد. از Graph ML میتوان برای انجام طیف وسیعی از فرایندها از جمله طبقهبندی گرهها، پیشبینی پیوندهای پنهان در میان گرهها، طبقهبندی نمودارها و همچنین خوشهبندی استفاده کرد.
قدم هشتم: پروژههای یادگیری ماشین
دورههای آنلاین، کتابها و سایر منابع یادگیری به شما در درک اصول یادگیری ماشین کمک میکنند، اما یادگیری واقعی فقط با انجام پروژههایی با دادههای دنیای واقعی امکانپذیر است. آخرین قدم در نقشه راه یادگیری ماشین، انجام پروژه است. بنابراین هنگامی که تمام مهارتهای موردنیاز را یاد گرفتید، شروع به کار بر روی پروژههای یادگیری ماشین کنید. شما با کار بر روی پروژههای بیشتر، مهارتهای بیشتری کسب کرده و بر مفاهیم تسلط بیشتری پیدا خواهید کرد.
پروژههای یادگیری ماشین به شما کمک میکنند تا مهارتهایی که تاکنون توسعه دادهاید را تمرین کرده و در عین حال در پورتفولیوی خود چیزی برای نمایش مهارتهای خود داشته باشید. کار بر روی پروژههای واقعی نهتنها به شما در درک بهتر علم داده و یادگیری ماشین کمک میکنند، بلکه به شما کمک میکند تا به کارفرمایان نشان دهید که در صورت داشتن فرصت چه کاری میتوانید انجام دهید.
شرکت در مسابقات یادگیری ماشین نیز فرصت خوبی است تا آموختههای خود را در عمل به کار گرفته و به چالش بکشید. کوئرا هرساله مسابقات متعددی در زمینهی علم داده و یادگیری ماشین برگزار میکند. برای کسب اطلاعات بیشتر و شرکت در مسابقات علم دادهی کوئرا، میتوانید شبکههای مجازی کوئرا را دنبال کنید یا در صفحهی مسابقات کوئرا، پیگیر برگزاری مسابقه جدید باشید. همچنین با مراجعه به بانک سؤالات کوئرا، میتوانید سؤالات مسابقات پیشین را حل کرده و آموختههای خود را به چالش بکشید.
جمعبندی
امیدواریم این نقشه راه یادگیری ماشین به شما کمک کند تا راحتتر مسیر تبدیلشدن به یک متخصص یادگیری ماشین را طی کنید. با این حال این نقشهی راه، تنها مسیر یادگیری و تسلط بر یادگیری ماشین نیست. بنابراین اگر پیشنهادی برای بهبود این مسیر دارید، خوشحال میشویم که پیشنهاد خود را در بخش نظرات با ما و دوستان خود به اشتراک بگذارید.