آموزش کاربردی وب اسکرپینگ با PHP – هرچه باید بدانید
اینترنت امروزی فضایی بسیار عظیم با بیش از ۴.۷ میلیارد کاربر است که هر روز بزرگتر هم میشود. طبیعتا شمار بیشتر کاربران هم به معنی تولید دادههای هرچه بیشتر است. در واقع اینترنت اکنون آنقدر بزرگ است که تخمین زده میشود گوگل، آمازون، مایکروسافت و فیسبوک به تنهایی از حدود ۱.۲ میلیون ترابایت داده نگهداری میکنند. حتی با یک هزارم از این مقدار داده هم فرصتهای تجاری بیشماری شکل میگیرد و جای تعجب ندارد که جمعیت زیادی از مردم به آموزش PHP و وب اسکرپینگ علاقهمند شدهاند. در این مقاله نهتنها با مفهوم وب اسکرپینگ آشنا میشوید، بلکه روش وب اسکرپینگ با PHP را هم میآموزید. با کوئرا بلاگ همراه باشید.
وب اسکرپینگ چیست و چرا باید داده را اسکرپ کرد؟
دادههایی که صحبتش را کردیم در میان میلیاردها وبسایت مختلف پخش شدهاند و این باعث میشود توسعهدهندگان نیازمند راهی برای جمعآوری و پردازش این اطلاعات باشند تا محصولاتی نوآورانه در اختیار کاربران بگذارند. با این حال جمعآوری دستی اطلاعات به هیچ وجه امکانپذیر نیست، زیرا نهتنها حجم داده واقعا کلان است، بلکه اطلاعات دائما دچار تغییر میشوند.

راهکار این است که داده را به صورت خودکار استخراج کنیم و این خیلی ساده، معنای وب اسکرپینگ است. هرچه اطلاعات بیشتری به دست میآورید، ایدهها، فرصتها و مزایای بیشتری هم خواهید داشت. وقتی داده پردازش میشود، میتواند برای شما یا مشتریان کسبوکار شما بینهایت ارزشمند باشد. برخی از کاربردهای وب اسکرپینگ با پی اچ پی را در ادامه آوردهایم:
- ابزارهای مقایسه قیمت: با اسکرپ کردن چندین وبسایت میتوان متوجه شد که یک محصول معمولا با چه قیمتی فروخته میشود.
- تحقیق بازار: با سر درآوردن از اینکه برجستهترین رقبا چه میکنند، شانس بیشتری برای موفقیت خواهید داشت.
- یادگیری ماشین: که در زمینه جمعآوری و آزمودن مجموعه دادهها کاربرد دارد.
- و هر ایده دیگری که نیازمند دسترسی به مقادیر قابل توجهی از داده است.
برای مثال یکی از کاربردهای بالقوه میتواند ساخت اپلیکیشنی برای پایش تغذیه باشد که اجازه میدهد غذاهای خود را به آن اضافه کنید. در حالت ایدئال، کاربر اپلیکیشن را باز میکند، به دنبال محصولاتی میگردد که خورده است و آنها را به ابزار اضافه میکند تا ببیند در ادامه روز میتواند چند کالری دیگر دریافت کند.
اما این ابزار نیازمند فهرستی بلندبالا از محصولات بالقوه و ارزشهای غذایی هرکدام خواهد بود. با وب اسکرپینگ میتوانید اطلاعات مورد نیاز را از سایتهای مختلف جمعآوری کنید و فهرستهایی بسازید که به صورت خودکار بهروزرسانی میشوند.
بیشتر بخوانید: وب اسکرپینگ چیست و چطور انجام میشود؟ – راهنمای کامل Web Scraping
شاید علاقهمند باشید: PHP چیست؟
چالشهای وب اسکرپینگ چیست؟
اگرچه وب اسکرپینگ فرایندی کاملا کاربردی برای شخصی که از بات استفاده میکند به حساب میآید، برخی وبسایتها علاقهای به اشتراکگذاری محتوای خود نشان نمیدهند و شاید با شما مقابله کنند.

برخی از راهکارهایی که برای این کار در پیش میگیرند را در ادامه آوردهایم:
- کدهای کپچا (Captcha Codes): هر صفحهای در وب میتواند از کپچا استفاده کند، حتی اگر آن را به کاربر نشان ندهد. وقتی چندین درخواست میفرستید، یک کد کپچا به نمایش درمیآید که وب اسکرپر شما را از کار میاندازد.
- مسدودسازی آیپی (IP Blocking): برخی از وبسایت وقتی متوجه ترافیک کمرشکنی میشوند که از سمت شما میآید، تصمیم به مسدودسازی کامل آیپی میگیرند.
- مسدودسازی جغرافیایی (Geo-Blocking): گاهی از اوقات محتوا در برخی کشورهای خاص مسدود میشود یا ممکن است محتوایی متفاوت دریافت کنید که برای منطقه شما طراحی شده است.
- جاوا اسکریپت: اکثر سایتهای امروزی به هر طریق ممکن از جاوا اسکریپت استفاده میکنند. برخی از آن برای نمایش پویای محتوا کمک میگیرند که شرایط را برای وب اسکرپر شما دشوار میکند، زیرا منبع صفحه با آنچه درون صفحه به نمایش درمیآید یکسان نیست.
برای وب اسکرپینگ با PHP نیاز به چه دارید؟
حالا که دانشی کلی راجع به وب اسکرپینگ به دست آوردیم، احتمالا برای ساخت نخستین وب اسکرپر خود آماده باشید. اما پیش از هر چیز باید راهی برای به اجرا درآوردن کدهای PHP پیدا کنیم. مثلا میتوانید از یک سرور Apache یا Nginx همراه با PHP نصبشده کمک بگیرید و کدها را مستقیما روی مرورگر اجرا کنید، یا اینکه به سراغ خط فرمان (Command Line) بروید.

پیش از هر چیز با استفاده از یک کتابخانه بهخصوص برای پردازش محتوای اسکرپ شده، زندگی را برای خودمان آسانتر میکنیم. از جمله کتابخانههای محبوب برای اسکرپینگ با PHP میتوان به Simple HTML DOM ،Panther و htmlSQL اشاره کرد. البته اگر مایل بودید، میتوانید محتوا را با عبارات یا Expressionهای معمولی نیز پردازش کنید.
در این مقاله به سراغ Simple HTML Dom میرویم، اما در نظر داشته باشید که برای درخواستهای پیشرفتهتر از یک کتابخانه دیگر به نام cURL نیز کمک خواهیم گرفت.
استفاده از Simple HTML DOM
Simple HTML DOM کتابخانهای است که به شما اجازه میدهد به شکلی آسانتر به محتوای صفحات دسترسی پیدا کنید. برای دانلود Simple HTML DOM میتوانید سری به وبسایت sourceforge.net بزنید و ضمنا پیشنهاد میکنیم که اسناد مربوط به آن را نیز با دقت بخوانید.
درون فایل زیپی که بعد از دانلود فایل باز میکنید، تنها به فایل simle_html_dom.php نیاز دارید که باید آن را در همان فولدری قرار دهید که کدهای اسکرپر را نیز درون آن خواهید نوشت.
برای تعبیه کتابخانه درون کد، تنها به یک خط کد نیاز دارید:
include 'simple_html_dom.php';'path_to_library/simple_html_dom.php'نصب php-curl

اگرچه لزوما نیازی به این ابزار ندارید، اما اگر بخواهید برای درخواستهای پیشرفتهتر از هدرهای مختلف استفاده کنید به کتابخانه php-curl نیاز پیدا خواهید کرد.
برای نصب این کتابخانه روی دستگاهی مبتنی بر سیستم عامل اوبونتو، میتوانید از این فرمان کمک بگیرید:
sudo apt-get install php-curlساخت ابزار وب اسکرپینگ با PHP
حالا که به تمام پیشنیازهای ضروری دسترسی داریم، نوبت به استخراج داده میرسد. پیش از هر چیز باید وبسایت مورد نظرتان برای اسکرپ کردن داده را شناسایی کنید. برای این مقاله به اسکرپ کردن فهرست پرامتیازترین فیلمهای IMDB مشغول میشویم.
۱. بررسی محتوای وبسایت
اکثر محتوای وب به کمک HTML به نمایش درمیآید. از آنجایی که لازم است محتوایی بهخصوص را از یک منبع HTML استخراج کنیم، لازم است درکی جامع نیز از آن داشته باشیم. بنابراین ابتدا باید شمایل صفحه منبع را بررسی کنیم تا متوجه شویم کدام عناصر باید استخراج شوند.
برای این کار میتوانید در مرورگر گوگل کروم به سراغ عنصری که میخواهید استخراج شود بروید و سپس با راستکلیک، گزینه Inspect Element را انتخاب کنید. با این کار پنجرهای درون مرورگر باز میشود که منبع صفحه و استایلهای رندر عناصر را نشان میدهد. از درون این پنجره تنها باید تیک گزینه Elements را بزنیم تا ساختار HTML صفحه نمایش داده شود.
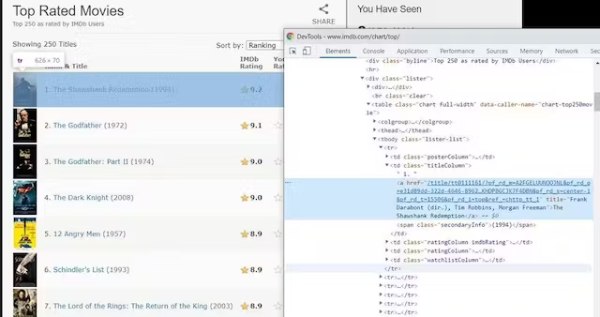
برای مثال در تصویر بالا صفحهای را میبینید که حاوی جدولی با کلاسهای «chart» و «full-width» است. در این جدول، هر سلول کلاس خودش را دارد (مثلا posterColumn و titleColumn و غیره) و میتوانیم از آن برای ساخت یک «انتخابگر» یا «Selector» استفاده کنیم. سپس میتوانیم تنها به داده مورد نیاز خود دسترسی پیدا کنیم.
اگر گیج شدهاید جای نگرانی نیست و در مراحل بعدی همهچیز واضحتر میشود.
۲. ارسال درخواست از PHP
ارسال درخواست یا Request اساسا به این معناست که از طریق کد PHP، دسترسی مستقیم به HTML یک صفحه پیدا میکنیم. پیش از هرچیز میتوانیم از کتابخانه php-curl کمک بگیریم که امکان دستکاری هدرها و بدنهای که در درخواست خود میفرستیم را مهیا کرده است:
<?php
header("Content-Type: text/plain");
$ch = curl_init("https://www.imdb.com/chart/top/");
curl_setopt($ch, CURLOPT_HEADER, 0);
$response = curl_exec($ch);
if (curl_error($ch)) {
echo curl_error($ch);
} else {
echo $response;
}
curl_close($ch);
یک گزینه دیگر هم استفاده از کدی تکخطی و استفاده از روش file_get_contents($url) است، هرچند که گاهی از اوقات کارایی لازم را ندارد. برای ارسال هدرها به این درخواست، لازم است از کانتکستی استفاده کنیم که با روش stream_context_create ساخته شده است:
<?php
header("Content-Type: text/plain");
echo file_get_contents('https://www.imdb.com/chart/top/');
بسته به اینکه اسکرپر مورد نظرتان چقدر پیچیده است باید یکی از این دو روش را برای پیشبرد کار انتخاب کنید.
هر دو کد بالا منبع HTML صفحهای که اسکرپ میکنیم را نشان میدهند و همین اطلاعات را میتوانید هنگام Inspect Element نیز مشاهده کنید. از نخستین خط کد برای نمایش نتایج به عنوان متن استفاده میکنیم، در غیر این صورت مستقیما در HTML رندر میشوند.
اگر تفاوتی از نظر ساختار HTML وجود داشته باشد، یک کد جاوا اسکریپت روی وبسایت به اجرا درمیآید و محتوایی که کاربر خواستار دسترسی به آن است را تغییر میدهد..
۳. استخراج داده
در این مثال تنها میخواهیم عنوان فیلمها و امتیاز هرکدام را از صفحه مورد نظرمان استخراج کنیم. همانطور که پیشتر نیز دیدیم، محتوا درون جدولی به نمایش درمیآید که هر سلول از آن کلاس مخصوص خود را داشته باشد.
خالا میتوانیم تصمیم به استخراج تمام ردیفهای جدول بگیریم. سپس هر ردیف یکتا را برای یافتن سلولهایی که برای ما جالب توجه به حساب میآیند، بررسی میکنیم.
کدی که در ادامه آوردهایم دقیقا همین کار را میکند:
<?php
header("Content-Type: text/plain");
include 'simple_html_dom.php';$html_dom =
file_get_html('https://www.imdb.com/chart/top/');
$table_rows = $html_dom->find('table.chart tbody tr');
foreach($table_rows as $table_row) {
$title_element = $table_row->find('.titleColumn a', 0);
$rating_element = $table_row->find('.ratingColumn strong', 0);
if (!is_null($title_element) && !is_null($rating_element)) {
echo $title_element->innertext . ' has rating ' . $rating_element->innertext .
PHP_EOL;
}
}
اگر دقت کنید میبینید که از انتخابگر «table.chart tbody tr» برای استخراج تمام ردیفهای جدول استفاده کردهایم. پیشنهاد میکنیم شما هم تا جای ممکن به سراغ انتخابگرهایی با کارکرد کاملا مشخص بروید تا بعدا بتوانید عناصر مختلف را از یکدیگر تمیز دهید.
بعد از گردآوری ردیفها، میان آنها لوپ میکنیم و به دنبال عناصری میگردیم که یکی از کلاسهای titleColumn یا ratingColumn را داشته باشند. اگر کد ما چنین ردیفهایی را پیدا کند، خاصیت innerText آنها را نشان میدهد.
بسیار مهم است بدانید که در این مثال به جای file_get_contents از file_get_html کمک گرفتهایم. به این خاطر که این تابع همراه با کتابخانه simple_html_dom از راه میرسد و نقش «رپر» (Wrapper) را برای تابع file_get_contents ایفا میکند.
۴. اکسپورت داده
در مثالهای بالا، داده سایت را جمعآوری کردیم و مستقیما روی صفحه به نمایش درآوردیم. حالا خوب است بدانید که هنگام اسکرپینگ با PHP میتوانید داده را به راحتی ذخیرهسازی نیز کنید. در واقع میتوانید دادههای اسکرپ شده را درون فایلی با پسوند txt. یا JSON یا CSV نگه دارید و حتی آن را مستقیما برای دیتابیس بفرستید. PHP در این زمینه حسابی به کارتان میآید. فقط کافی است داده را درون یک آرایه ذخیره کنیم و محتوای آرایه را درون فایلی جدید قرار دهیم.
<?php
include 'simple_html_dom.php';
$scraped_data = [];
$html_dom = file_get_html('https://www.imdb.com/chart/top/');
$table_rows = $html_dom->find('table.chart tbody tr');
foreach($table_rows as $table_row) {
$title_element = $table_row->find('.titleColumn a', 0);
$rating_element = $table_row->find('.ratingColumn strong', 0);
if (!is_null($title_element) && !is_null($rating_element)) {
$scraped_data[] = [
'title' => $title_element->innertext,
'rating' => $rating_element->innertext,
];
}
}
file_put_contents('file.json', json_encode($scraped_data));
// Saving the scraped data as a csv
$csv_file = fopen('file.csv', 'w');
fputcsv($csv_file, array_keys($scraped_data[0]));
foreach ($scraped_data as $row) {
fputcsv($csv_file, array_values($row));}
fclose($csv_file);
کد بالا همان محتوایی که پیشتر استخراج کردیم را برداشته و دو فایل با پسوندهای CSV و JSON ایجاد میکند که هر دو شامل اطلاعات برترین فیلمهای فهرست IMDB و امتیازهای هرکدام میشوند.
نکات و ترفندهای وب اسکرپینگ با PHP
حالا که تمام دانستیهای ضروری راجع به وب اسکرپینگ با PHP را فرا گرفتهایم، لازم است برخی نکات و ترفند ضروری را که معمولا کاربران را از سردردهای رایج نجات میدهند، بررسی کنیم.
۱. رسیدگی به خطا
هنگام کدنویسی به زبان PHP و اسکرپ کردن داده از وبسایتهایی که ممکن است هر لحظه تغییر کنند، طبیعی است که با ارورهای گوناگون روبهرو شوید. کدی که در پایین آوردهایم برای عیبیابی به کار میآید و باید آن را ابتدای هر اسکریپتی در PHP قرار دهید.
ini_set('display_errors', '1');
ini_set('display_startup_errors', '1');
error_reporting(E_ALL);سه خط بالا به شما کمک میکنند مشکلات موجود در کدها را سریعتر بیابید و در صورت نیاز، اسکریپت خود را بهروزرسانی کنید.
۲. تنظیم هدرها در درخواستها
گاهی از اوقات هنگام ارسال درخواست ممکن است نیاز به ارسال چند هدر هم داشته باشید. برای مثال هنگام سر و کله زدن با یک رابط برنامهنویسی یا API ممکن است نیاز به توکن احراز هویت (Authorization Token) داشته باشید یا شاید بخواهید محتوا را به جای متن عادی در قالب فایل JSON دریافت کنید. برای افزودن هدرها هم میتوان از cURL و هم file_get_contents استفاده کرد. روش کار با cURL را در ادامه آوردهایم:
$ch = curl_init("http://httpbin.org/ip");
curl_setopt($ch, CURLOPT_HEADER, [
'accept: application/json'
]);
$response = curl_exec($ch);$opts = [
"http" => [
"method" => "GET",
"header" => "accept: application/json\r\n"
]
];
$context = stream_context_create($opts);
$result = file_get_contents("http://httpbin.org/ip", false, $context);۳. استفاده از cURL یا file_get_contents همراه با simple_html_dom
زمانی که محتوا را از سایت IMDB استخراج کردیم، از تابع file_get_html درون simple_html_dom کمک گرفتیم. این رویکرد زمانی جواب میدهد که درخواستی ساده دارید و هنگام رسیدگی به درخواستهای پیچیدهتر آنقدرها بهینه ظاهر نمیشود. اگر نیاز به ارسال چند هدر دارید، بهتر است از متدی که در نکته قبلی آوردیم استفاده کنید.
برای استفاده از روشی دیگر به جای file_get_html، خیلی ساده را محتوا را استخراج کنید و سپس از str_get_html برای تبدیل کردن آن به یک شی dom کمک بگیرید، مانند کد زیر:
$opts = [
"http" => [
"method" => "GET",
"header" => "accept: text/html\r\n"]];
$context = stream_context_create($opts);
$result = file_get_contents("https://www.imdb.com/chart/top/", false, $context);
$html_dom = str_get_html($result);ضمنا در نظر داشته باشید که simple_html_dom به صورت پیشفرض محدودیتهای خاص خود را دارد (که میتوانید آنها را درون فایل simple_html_dom.php بیابید). به عنوان مثال محتوای وبسایت نباید بیش از ۶۰۰ هزار کاراکتر یا حرف باشد. اگر میخواهید این محدودیت را تغییر دهید، فقط باید پیش از اینکه بهکارگیری کتابخانه simple_html_dom، بیشینه را در بالای کد خود تعریف کنید:
define('MAX_FILE_SIZE', 999999999);جمعبندی آموزش وب اسکرپینگ با PHP
اکنون که به پایان مقاله رسیدهایم، به تمام اطلاعات مورد نیاز برای نخستین نخستین وب اسکرپر خود با زبان PHP دسترسی دارید. در این مقاله صرفا به بررسی گزینههای مربوط به کتابخانه simple_html_dom پرداختیم، اما انبوهی کتابخانه محبوب دیگر نیز وجود دارد که میتوانید بسته به نیازها و سلایق خود، به سراغ هرکدام بروید. فقط در نظر داشته باشید که سایتها – و به تبع آنها، دادهها – هر روز دچار تغییر میشوند.
اگر میخواهید وب اسکرپینگ با PHP به بهترین شکل پیش برود، از Selectorهای هدفمند و مشخص استفاده کنید. اما هیچ تضمینی وجود ندارد که وب اسکرپر شما تا ابد به فعالیت خود ادامه دهد و اصلا به همین خاطر است که دنیای وب اسکرپینگ نیازمند بهروزرسانی و توجه دائمی است.
+ منبع: WebScrappingAPI