درخت تصمیم (Decision Tree) – تعریف، مزایا و کاربردها
درخت تصمیم (Decision Tree) نوعی یادگیری ماشین نظارتشده (Supervised Machine Learning) است که برای طبقهبندی یا پیشبینی بر اساس پاسخ سؤالات قبلی استفاده میشود. این مدل، شکلی از یادگیری نظارتشده است؛ به این معنا که آموزش و آزمایش مدل بر روی مجموعهدادهای که شامل طبقهبندی موردنظر است، انجام میشود. ممکن است این مدل همیشه نتواند پاسخ قطعی و روشنی ارائه دهد. در عوض، گزینههایی را در اختیار دانشمندان داده قرار میدهد تا بتوانند بر اساس آنها تصمیماتی آگاهانه بگیرند. درختهای تصمیم از تفکر انسانی تقلید میکنند. بنابراین متخصصین داده معمولاً بهراحتی میتوانند نتایج را متوجه شده و تفسیر کنند.
عملکرد درخت تصمیم چگونه است؟
قبل از توضیح نحوهی عملکرد، بیایید برخی اصطلاحات مربوط به آن را تعریف کنیم:
- گره ریشه (Root Node): پایهی درخت تصمیم است.
- تقسیم (Splitting): فرایند تقسیم یک گره به چندین زیرگره را میگویند.
- گره تصمیم (Decision Node): زمانی که یک زیرگره به زیرگرههای بیشتری تقسیم میشود، به آن گرهی تصمیم میگویند.
- گره برگ (Leaf Node): زمانی که یک زیرگره به زیرگرههای بیشتری تقسیم نمیشود و در واقع نشاندهندهی خروجی احتمالی است، به آن گرهی برگ میگویند.
- هرس (Pruning): فرایند حذف زیرگرههای یک درخت تصمیم را میگویند.
- شاخه (Branch): زیرمجموعهای از درخت تصمیم است که از چندین گره تشکیل شده است.
درخت تصمیمگیری بسیار شبیه درخت معمولی است. در ابتدای درخت، گرهی ریشه قرار دارد. مجموعهای از گرههای تصمیم از گره ریشه منشعب میشوند که نشاندهندهی تصمیماتی هستند که باید گرفته شوند. از گرههای تصمیم به گرههای برگ میرسیم که نشاندهندهی نتایج آن تصمیمات هستند. هر گره تصمیم نشاندهندهی یک سؤال یا نقطهی انشعاب است و گرههای برگی که از یک گره تصمیم منشعب میشوند، نشاندهندهی پاسخهای ممکن هستند. درست مانند رشد برگ روی شاخه، گرههای برگ نیز از گرههای تصمیم ایجاد میشوند. به همین دلیل است که به زیرمجموعههای این الگوریتم شاخه میگوییم.
برای درک بهتر این موضوع اجازه دهید با هم یک مثال را بررسی کنیم. فرض کنید گلف بازی میکنید و آنقدر مهارت دارید که کیفیت پرتابهایتان در طول بازی متغیر نباشد. میخواهید پیشبینی کنید که هر روز امتیازتان کجا خواهد بود: پایینتر از حد انتظار یا بالاتر از آن.
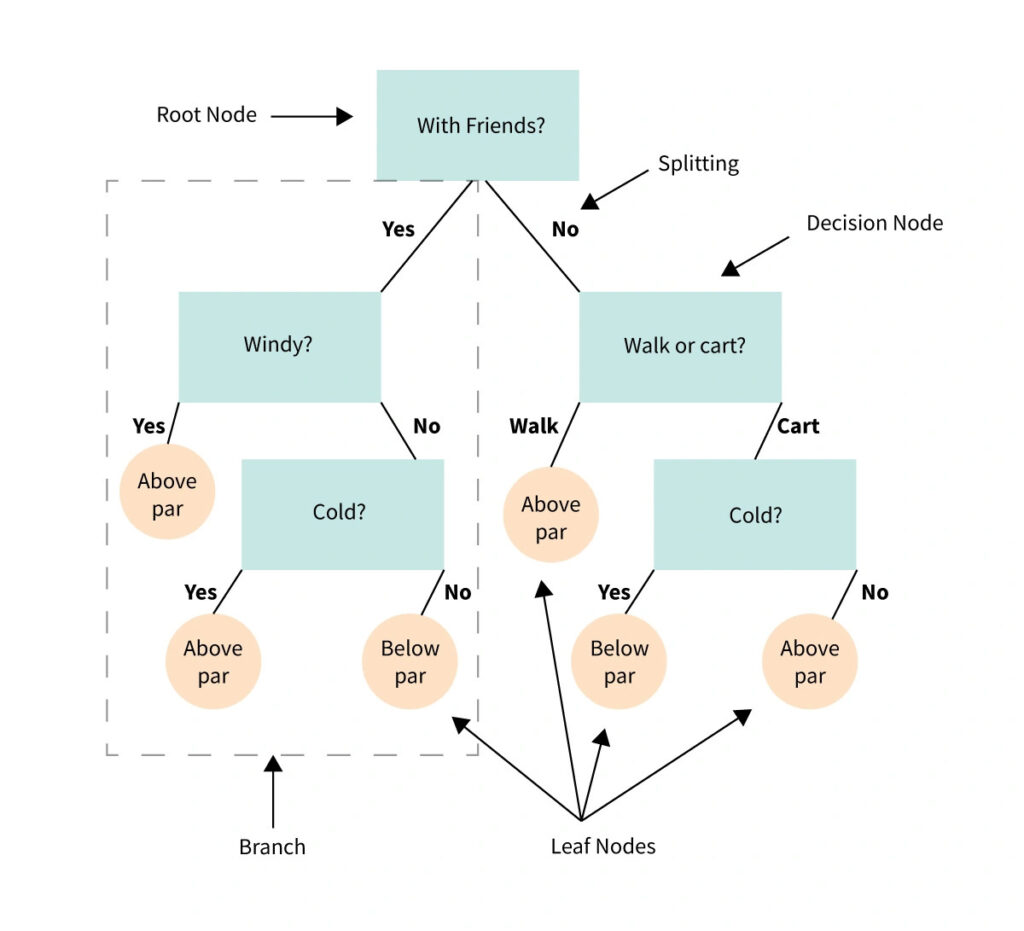
از انجا که گلفباز ماهری هستید و کیفیت پرتابهایتان در طول بازی متغیر نیست، امتیاز شما به مجموعهی محدودی از متغیرهای ورودی بستگی دارد؛ مثل سرعت باد، میزان ابر در آسمان و دما. بهعلاوه، امتیازتان میتواند به این موضوع هم بستگی داشته باشد که راه میروید یا از ماشین گلف استفاده میکنید. حتی این موضوع که با دوستانتان بازی میکنید یا با غریبهها هم میتواند تأثیرگذار باشد.
در این مثال، دو گره برگ داریم: پایینتر از حد انتظار یا بالاتر از آن. هر متغیر ورودی یک گره تصمیم خواهد بود. باد میوزید؟ هوا سرد بود؟ با دوستانتان بازی میکردید؟ راه میرفتید یا از ماشین گلف استفاده میکردید؟ اگر دادههای کافی در مورد عادات گلفبازی خود داشته باشید، درخت تصمیمگیری میتواند به شما کمک کند تا امتیازات هر روزتان را پیشبینی کنید.
متغیرها و طراحی درخت تصمیم
در مثال گلف، هر خروجی از تصمیمات قبلی مستقل است و به این بستگی ندارد که در تصمیم قبلی چه اتفاقی افتاده است. در مقابل متغیرهای وابسته تحتتأثیر اتفاقات قبل از خود قرار میگیرند.
برای ایجاد ساختار این مدل، باید ویژگیها و شرایطی که درخت را ایجاد میکنند، انتخاب کنید. پس از آن، درخت را هرس میکنید تا شاخههای بیربطی که میتوانند بر دقت تصمیمگیری تأثیرگذار باشند را حذف کنید. هرسکردن مستلزم شناسایی دادههای پرت است؛ یعنی نقاط دادهای که خیلی از محدودهی طبیعی فاصله دارند و با وزندهی زیاد به موقعیتهای نادر قادر به منحرفکردن تصمیمگیری هستند.
ممکن است در بازی گلف، دما تأثیر چندانی بر امتیاز شما نداشته باشد یا دادههای روزی که خیلی بد بازی کردید، درخت تصمیمتان را منحرف کند. زمانی که به دنبال داده برای درخت تصمیمتان هستید، میتوانید دادههای پرت را حذف کنید؛ مانند روزی که خیلی بد بازی کردید. همچنین میتوانید کل یک شاخه، مانند شاخهی دما که ربطی به دستهبندی دادههایتان ندارد را حذف کنید.مدلی که بهخوبی طراحی شده باشد دادهها را با تعداد کمی گره و شاخه نمایش میدهد. میتوانید درخت تصمیمتان را روی کاغذ یا تخته بکشید، اما برای تصمیمات پیچیدهتر لازم است از نرمافزارهای مخصوص استفاده کنید.
نرم افزارهای ساخت درخت تصمیم
ابزارها و نرمافزارهای زیادی برای رسم درخت تصمیم وجود دارند که کار را برای شما به مراتب آسانتر میکنند. نمونههایی از این نرمافزارها عبارتاند از:
انواع درخت تصمیم چیست؟
انواع اصلی درختهای تصمیمگیری عبارتاند از: درخت تصمیم با متغیر گسسته (Categorical Variable Decision Tree) و درخت تصمیم با متغیر پیوسته (Continuous Variable Decision Tree) که بر اساس نوع متغیر خروجیِ مورداستفاده ایجاد شدهاند.
درخت تصمیم با متغیر گسسته: در این مدل، جواب به یک طبقهبندی خاص نزدیک است. سکه شیر است یا خط؟ حیوان خزنده است یا پستاندار؟ در این نوع درخت تصمیمگیری، دادهها بر اساس تصمیماتی که در گرههای درخت گرفته شدهاند، در یک طبقهبندی خاص قرار میگیرند.
درخت تصمیم با متغیر پیوسته: در این مدل، یک جواب بله یا خیر مشخص وجود ندارد. به این نوع درخت، درخت رگرسیونی هم گفته میشود زیرا متغیر خروجی یا همان تصمیم گرفتهشده به تصمیمات قبلی بستگی دارد. مزیت درخت تصمیمگیری با متغیر پیوسته این است که میتوان خروجی را بر اساس چندین متغیر پیشبینی کرد. اما در مدل با متغیر گسسته، پیشبینی تنها بر اساس یک متغیر انجام میشود. در درخت تصمیمگیری با متغیر پیوسته، با انتخاب الگوریتم صحیح میتوان از هر دو روابط خطی و غیرخطی استفاده کرد.
مهمترین الگوریتمهای درخت تصمیم
ID3
الگوریتم ID3 (Iterative Dichotomiser 3) یکی از اولین الگوریتم هایی است که برای ساخت درخت تصمیمگیری ارائه شده است. این الگوریتم از معیار اطلاعات یا Information Gain برای انتخاب ویژگی ها برای تقسیم داده ها استفاده می کند.
C4.5
C4.5 نسخه ای به روز شده از ID3 است. در مقابل ID3 که فقط با ویژگی های گسسته کار می کند، C4.5 می تواند با ویژگی های گسسته و پیوسته کار کند. علاوه بر این، C4.5 از معیار Gain Ratio که نسبت Information Gain به انتروپی ویژگی است، برای انتخاب ویژگی ها استفاده می کند.
CART
CART (Classification and Regression Trees) یک الگوریتم دیگر برای ساخت درخت تصمیمگیری است که برای مسائل طبقه بندی و رگرسیون قابل استفاده است. CART از معیار Gini Impurity برای انتخاب ویژگی ها استفاده می کند و درخت های باینری (دو تایی) می سازد.
CHID
CHID (Chi-square Automatic Interaction Detector) الگوریتمی است که از آزمون آماری چی دوم (Chi-square) برای ارزیابی ویژگی ها و انتخاب بهترین ویژگی برای تقسیم داده ها استفاده می کند.
الگوریتم های دیگر
به غیر از الگوریتم های فوق، الگوریتم های دیگری نیز برای ساخت درخت تصمیم وجود دارند. مثلاً الگوریتم M5 که برای ساخت درخت تصمیم برای مسائل رگرسیون استفاده می شود، یا الگوریتم Random Forest که یک تکنیک انسمبل برای ساخت چندین درخت تصمیمگیری و ترکیب پیش بینی های آن ها است.
هر یک از این الگوریتم ها دارای مزایا و معایب خاص خود هستند و انتخاب بهترین الگوریتم بستگی به مسئله یادگیری ماشین مورد نظر دارد.
ممکن است علاقهمند باشید: یادگیری ماشین (Machine Learning) چیست؟
اجزای درخت تصمیم
درختهای تصمیم میتوانند با دادههای پیچیده سروکار داشته باشند. با این حال، این جمله بدان معنا نیست که درک عملکرد این الگوریتم دشوار است. تمام درختان تصمیم در هسته خود، از چهار بخش کلیدی تشکیل شدهاند:
- گره ریشه
گره ریشه گره بالای درخت است که نقطه شروع فرآیند تصمیمگیری را نشان میدهد. این گره حاوی ویژگی است که آن را تبدیل به مهمترین گره برای پیشبینی متغیر هدف میکند.
- گرههای داخلی
گرههای داخلی گرههایی حاوی گره فرزند هستند. آنها مراحل میانی در فرآیند تصمیمگیری را نشان میدهند. هر گره داخلی حاوی یک قانون تصمیمگیری است که دادهها را به دو یا چند شاخه تقسیم میکند. گرههای داخلی شامل سه گره متداول میشوند که موارد زیر را در برمیگیرند:
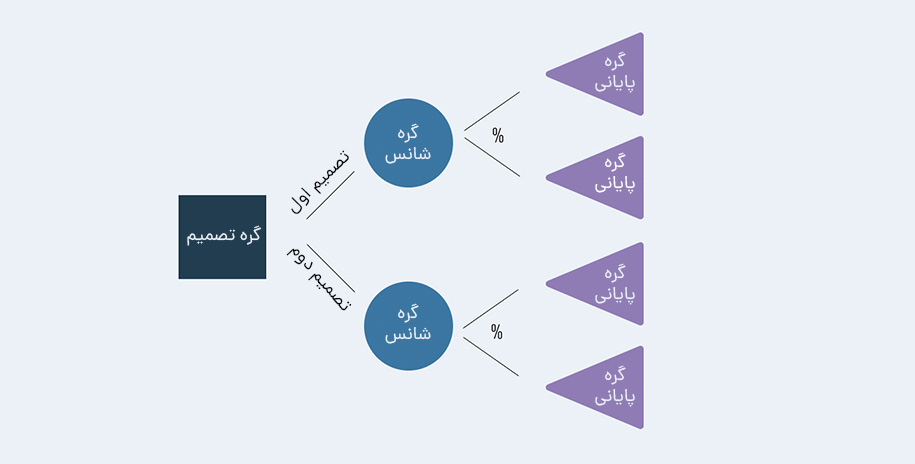
- گرههای تصمیم (Decision nodes): یک تصمیم را نشان میدهند (معمولا با مربع نشان داده میشود).
- گرههای شانس (Chance nodes): نشاندهنده احتمال یا عدم قطعیت هستند (معمولا این گرهها را با یک دایره نشان میدهیم).
- گرههای پایانی (End nodes): گرههای پایانی یک نتیجه را در معرض دید قرار میدهند (معمولا با یک مثلث مشخص میشوند).
اتصال این گرههای مختلف همان چیزی است که ما آن را «شاخه» (Branch) مینامیم. گرهها و شاخهها را میتوان بارهاوبارها در هر تعداد ترکیب برای ایجاد درختان با پیچیدگیهای مختلف استفاده کرد.
- شاخهها
شاخهها خطوطی هستند که گرهها را به یکدیگر متصل میکنند. آنها نتایج احتمالی یک تصمیم را نشان میدهند. هر شاخه به یک گره فرزند منتهی میشود.
- گرههای برگ
گرههای برگ، گرههایی هستند که هیچ گره فرزندی ندارند. آنها نشاندهنده نتیجه نهایی فرآیند تصمیمگیری هستند. هر گره برگ حاوی یک پیشبینی برای متغیر هدف است.
نحوه هرس درخت تصمیم
گاهی اوقات درختان تصمیم میتوانند بسیار پیچیده رشد کنند. در این موارد، آنها معمولا به دادههای نامربوط وزن زیادی میدهند. این گرهها مانع از رشد درخت به سمت عمق میشوند. برای جلوگیری از این مشکل، میتوانیم گرههای خاصی را با استفاده از فرآیندی به نام «هرس» حذف کنیم. هرس دقیقا همان چیزی است که بهنظر میرسد: اگر درخت شاخههایی را رشد دهد که به آنها نیاز نداریم، باید بهسادگی قطعشان کنیم. افزایش شاخههای بدون استفاده را با نام «بیشبرازش» یا “Overfitting” میشناسیم. درست مانند هر الگوریتم یادگیری ماشین دیگری، آزاردهندهترین اتفاقی که میتواند بیفتد، مشکل بیشبرازش است. درخت تصمیم به وفور با مشکل بیشبرازش روبهرو میشود.
دو نوع هرس Decision Tree وجود دارد: 1) قبل از هرس (Pre-pruning) و 2) پس از هرس (Post-pruning). در ادامه هر دو نوع را تشریح خواهیم کرد.
بیشتر بخوانید: آشنایی با Overfitting (بیشبرازش) و Underfitting (کمبرازش) در یادگیری ماشین
پیش هرس درخت تصمیم
پیش هرس درخت تصمیم تکنیکی برای جلوگیری از رشد بیش از حد این الگوریتم است. Decision Tree با عمق خیلی زیاد میتواند به خطر بیشبرازش دچار شود؛ به این معنی که دادههای آموزشی را بهدرستی یاد گرفته است و بهخوبی به دادههای جدید تعمیم نمیدهد. این مرحله به «توقف اولیه» مشهور است که رشد درخت تصمیم را متوقف میکند و مانع از رسیدن آن به عمق کامل میشود.
پیش هرس فرآیند درختسازی را متوقف میکند تا از تولید برگ با نمونههای کوچک جلوگیری شود. در طول هر مرحله از تقسیم درخت، خطای اعتبارسنجی متقاطع پایش میشود. اگر مقدار خطا دیگر کاهش نیابد، رشد درخت را متوقف میکنیم.
هایپرپارامترهایی (Hyperparameters) که میتوان برای توقف زودهنگام و جلوگیری از بیشبرازش تنظیم کرد عبارتند از:
max_depth, min_samples_leaf, min_samples_split
از همین پارامترها هم میتوان برای تنظیم کردن یک مدل قوی استفاده کرد. با این حال، باید محتاط باشید؛ زیرا توقف زودهنگام میتواند منجر به عدم تناسب در مدل و وقوع مشکل کمبرازش (Underfitting) شود.
پیش هرس درخت تصمیم به دو شیوه اصلی قابل پیادهسازی است:
- حداکثر عمق را برای درخت تنظیم کنید. این به این معنی است که درخت اجازه نخواهد داشت هیچ شاخهای عمیقتر از یک سطح خاص داشته باشد.
- حداقل تعداد نقاط داده را تنظیم کنید که باید قبل از تقسیم شدن در یک گره باشند. در این حالت درخت اجازه ندارد یک گره را تقسیم کند؛ مگر اینکه حداقل تعداد معینی از نقاط داده در آن باشد.
پیش هرس میتواند به بهبود دقت درخت تصمیم با جلوگیری از بیشبرازش آن کمک کند. همچنین تفسیر درخت در مرحله پیش هرس آسانتر است؛ زیرا کوچکتر و کمتر پیچیده خواهد بود.
پس هرس درخت تصمیم
پس هرس درخت تصمیم برعکس پیش هرس عمل میکند و به مدل اجازه میدهد که تا سطح عمیق و کامل خود رشد کند. هنگامی که مدل رشد کرد و به عمق کامل خود رسید، شاخههای درخت برداشته میشوند تا از احتمال بیشبرازش مدل جلوگیری شود.
الگوریتم به تقسیمبندی دادهها به زیرمجموعههای کوچکتر ادامه میدهد تا زمانی که زیرمجموعههای نهایی تولیدشده از نظر متغیر نتیجه مشابه باشند. زیرمجموعه نهایی درخت فقط از چند نقطه داده تشکیل شده است که به درخت اجازه میدهد تا دادهها را به شکل نمودار T یاد بگیرد. با این حال، وقتی یک نقطه داده جدید معرفی میشود که با دادههای آموختهشده متفاوت است، احتمال خطا در پیشبینی نتیجه بهوجود خواهد آمد.
هایپرپارامتری که میتواند برای پس هرس درخت تصمیم و جلوگیری از بیشبرازش تنظیم شود این است:
ccp_alpha
ccp مخفف Cost Complexity Pruning است و میتواند بهعنوان گزینه دیگری برای کنترل اندازه درخت استفاده شود. مقدار بالاتر ccp_alpha منجر به افزایش تعداد گرههای هرسشده میشود.
نمونه ها و مثال هایی از درخت تصمیم
اکنون که اصول اولیه را پوشش دادیم، مایلیم نمونه هایی از درخت تصمیم را با یکدیگر ببینیم.
درخت تصمیم در احساس گرسنگی
اولین مثال را با احساس گرسنگی پیش میبریم. به گزینههایی که هنگام گرسنگی در دسترسمان هستند فکر کنید. ممکن است این گزینهها را بهصورت زیر درنظر گرفته باشید:
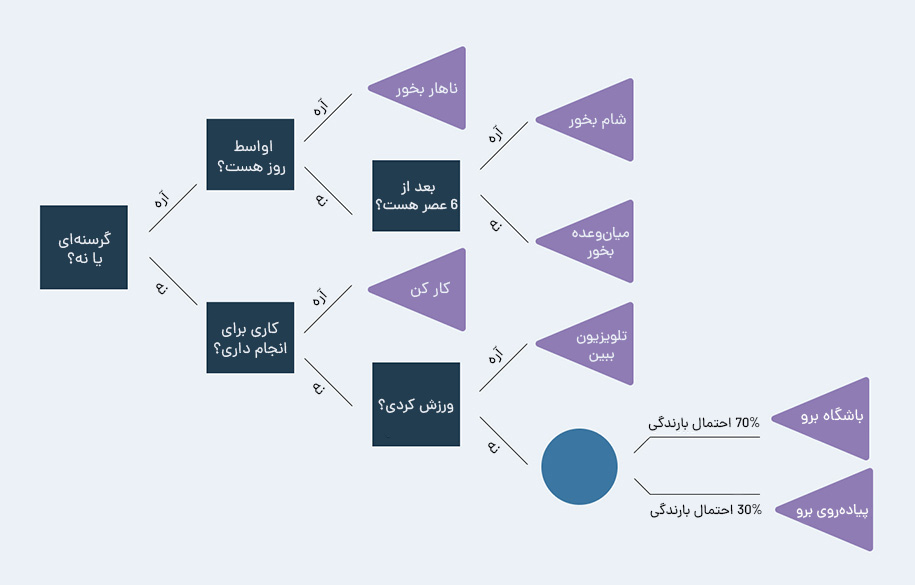
در این نمودار، گرههای تصمیم به رنگ آبی تیره، گرههای شانس آبی روشن و گرههای انتهایی بنفش هستند. با گنجاندن گزینههایی برای انجام کارهایی که در صورت گرسنه نبودن انجام میهیم، درخت تصمیم خود را بیش از حد پیچیده کردهایم. بههم ریختن درخت به این روش یک مشکل رایج است، بهخصوص زمانی که با حجم زیادی از دادهها سروکار داریم. این اتفاق اغلب منجر به استخراج معنا از اطلاعات نامربوط توسط الگوریتم میشود. این مشکل را بهعنوان بیشبرازش یا Overfitting میشناسیم. یکی از گزینههای اصلاح بیشبرازش، هرس درخت است. نمودار پیشین در صورت هرس به شکل زیر در خواهد آمد:
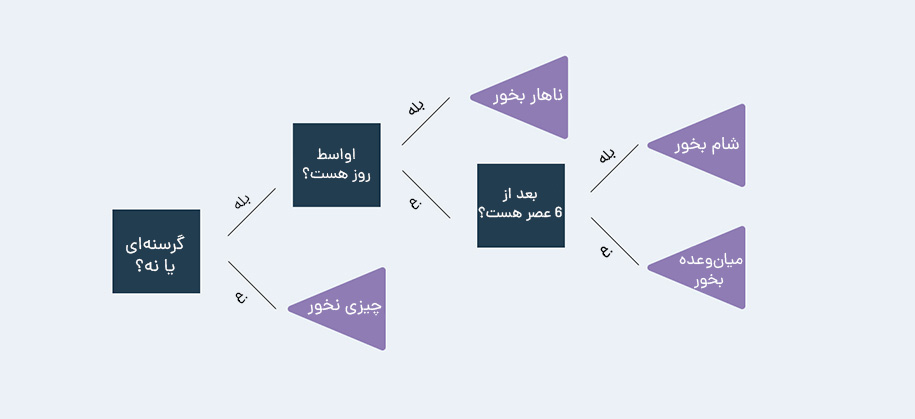
همانطور که میبینید، تمرکز درخت تصمیم ما اکنون بسیار واضحتر است. با حذف اطلاعات نامربوط (مثلا اگر گرسنه نیستیم چه کنیم) نتایج ما بر هدفی متمرکز میشود که در نظر داریم. این نمودار نمونهای از دامی است که درختان تصمیم میتوانند در آن بیفتند که با ترسیم شکل، دور شدن از آن را نشان دادیم.
درخت تصمیم در پذیرش یا رد پیشنهاد شغلی
فرض کنید کاندید شغلی وجود دارد که یک پیشنهاد دریافت کرده و میخواهد تصمیم بگیرد که آیا این پیشنهاد جذاب است یا خیر. کاندید این پیشنهاد را با درنظر گرفتن برخی پارامترها نظیر شرایط حقوق، فاصله خانه تا شرکت و حملونقل میسنجد. بنابراین، برای تصمیمگیری، درخت تصمیم با گره ریشه (ویژگی حقوق) ایجاد میشود. گره ریشه به گره تصمیم بعدی (فاصله تا دفتر) و یک گره برگ براساس برچسبهای مربوطه تقسیم میشود. گره تصمیم بعدی به یک گره تصمیم (شرایط حملونقل) و یک گره برگ تبدیل میشود. در نهایت، گره تصمیم به دو گره برگ (پیشنهاد پذیرفتهشده و پیشنهاد ردشده) تقسیم میشود. این مراحل را میتوانید در شکل زیر ببینید.
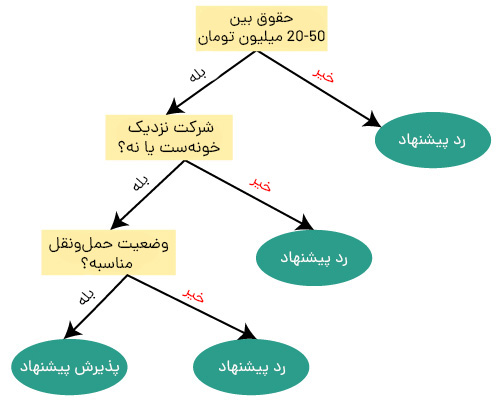
کاربرد درخت تصمیم چیست؟

درخت تصمیم برای طبقهبندی نتایج در زمانهایی کاربرد دارد که میتوان ویژگیها را بر اساس معیارهای معین مرتب کرد و به یک طبقهبندی نهایی رسید. درخت تصمیم خروجیهای احتمالی مجموعهای از انتخابهای مربوط به هم را ترسیم میکند. برخی از کاربردهای درخت تصمیم عبارتاند از:
موتورهای توصیهگر
مشتریانی که محصولات یا دستهبندیهای خاصی را خریداری میکنند، ممکن است تمایل به خرید محصولاتی مشابه با خریدهای قبل خود یا آنچه به دنبالش هستند نیز داشته باشند. اینجا است که موتورهای توصیهگر محصولاتی را به مشتری پیشنهاد میکنند. برای مثال میتوانند به خریدار چوبهای اسکی پیشنهاد کنند که یک جفت دستکش گرم هم بخرد یا وقتی آخر هفته فیلمی را تمام کردید، یک فیلم دیگر به شما معرفی کند. در ساختار موتورهای توصیهگر میتوان از درخت تصمیمگیری بهره گرفت که تصمیمات مشتری را در طی زمان در نظر میگیرد و بر اساس آنها محصولات جدیدی را پیشنهاد میکند.
حوزهی درمان
در سال 2009، مطالعهای در استرالیا انجام شد که 6000 نفر را در طی 4 سال مورد بررسی قرار داده بود تا ببیند در این مدت به اختلال جدی افسردگی دچار شدهاند یا نه. در نهایت این محققین دادههایی مانند استعمال دخانیات، مصرف الکل، وضعیت استخدامی و مواردی از این دست را در نظر گرفتند تا درخت تصمیمی ایجاد کنند که قادر به پیشبینی خطر ابتلا به اختلال جدی افسردگی باشد.
تصمیمات و تشخیصهای پزشکی به مجموعهای از دادههای ورودی بستگی دارند تا بتوانند وضعیت بیمار را درک کرده و بهترین درمان را شناسایی کنند. چنین استفادهای از این الگوریتم میتواند ابزار ارزشمندی برای حوزهی درمان باشد.
مزایا و معایب درخت تصمیم چیست؟
درخت تصمیمگیری نمایی از روابط علت و معلولی است که میتواند تصویری ساده از فرایندهای پیچیده ارائه میدهد. این مدل بهراحتی میتواند روابط غیرخطی را ترسیم کرده و برای مسائل گسسته و رگرسیونی راهحل ارائه کند. با درخت تصمیم میتوان میزان ریسک، اهداف و مزایا را مشخص کرد.
از آنجا که ساختار درخت تصمیمگیری یک فلوچارت ساده است، یکی از سریعترین روشها برای شناسایی متغیرهای تأثیرگذار و روابط بین دو یا چند متغیر محسوب میشود. اگر یک دانشمند داده روی مسئلهای با چندصد متغیر کار میکند، این مدل میتواند به او کمک کند تا تأثیرگذارترین آنها را شناسایی کند. از آنجایی که خروجی بهصورت بصری است، بهراحتی میتوان رابطهی بین متغیرها را مشاهده کرد. بنابراین برای درک درختهای تصمیم به دانش آماری چندانی احتیاج نیست و کسانی که پیشینهی تحلیلی ندارند نیز بهراحتی میتوانند آن را درک کنند.
با همهی اینها گاهی درخت تصمیم محدودیتهایی دارد. آگاهی از مزایا و معایب آن میتواند به شما کمک کند تا تشخیص دهید که برای چه مواردی بهتر است از آنها استفاده کنید.
مزایا:
- برای دادهها و متغیرهای گسسته و یا عددی به خوبی کار میکند.
- مسائل با چندین خروجی را مدلسازی میکند.
- نسبت به سایر روشهای مدلسازی داده، به پیشپردازش کمتری برای دادههای ورودی نیاز دارد.
- بهراحتی میتوان آن را برای کسانی که پیشینهی تحلیلی ندارند، شرح داد.
معایب:
- تحتتأثیر نویز در دادهها قرار میگیرد.
- برای مجموعهدادههای بزرگ ایدئال نیست.
- میتواند ویژگیها را بهطور نامتناسبی ارزشگذاری کند.
- از آنجایی که تصمیمها در گرهها محدود به خروجیهای باینری هستند، نمیتواند پیچیدگیهای زیاد را مدیریت کند.
- زمانی که با عدم قطعیت و خروجیهای زیادی سروکار داریم، درخت تصمیم میتواند خیلی پیچیده شود.
درخت تصمیم چیست؟ درخت تصمیم بخشی مهم از جعبه ابزار یک دانشمند داده است. الگوریتمهای این مدل، ابزاری قدرتمند برای طبقهبندی دادهها و ارزیابی هزینهها، خطرات و مزایای احتمالی ایدهها هستند و با استفاده از آنها میتوانید رویکردی اصولی و مبتنی بر حقایق برای تصمیمگیریهای به دور از سوگیری داشته باشید. خروجیها گزینههای در دسترس را در قالبی ارائه میدهند که بهسادگی قابل تفسیر است. این موضوع باعث میشود که درخت تصمیمگیری در هر محیطی کاربرد داشته باشد.