یادگیری تقویتی یا Reinforcement Learning چیست؟

به طور کلی یادگیری تقویتی (Reinforcement Learning) تکنیکی در Machine Learning و روش آموزش یادگیری ماشین است که در آن عامل کامپیوتری یاد میگیرد که یک کار را از طریق تعاملات تکراری و توسط آزمون و خطا با محیط پویا انجام دهد. این شیوه سیستم خودمختار و خودآموزی است که میتواند محیط اطرافش را درک و تفسیر کند، اقداماتی انجام دهد و از طریق آزمون و خطا یاد بگیرد. در این مقاله از کوئرا بلاگ به طور دقیقتری بررسی میکنیم که یادگیری تقویتی چیست و به جوانب دیگر یادگیری تقویتی از جمله شیوه کارکرد آن، انواع وظایف، کاربردها و… نیز خواهیم پرداخت.
یادگیری ماشین به زبان ساده
یادگیری ماشین (Machine Learning-ML) شاخهای از هوش مصنوعی (AI) و علوم کامپیوتر است که بر استفاده از دادهها و الگوریتمها تمرکز میکند. این علم هوش مصنوعی را قادر میسازد تا روشی را که انسانها یاد میگیرند تقلید کند و بهتدریج دقت خود را بهبود بخشد.
به عبارت سادهتر، یادگیری ماشین کامپیوترها را قادر میسازد تا از دادههای دریافتشده بیاموزند و بدون برنامهریزی مستقیم توسط توسعهدهنده، تصمیمگیری یا پیشبینی امور و فرآیندها را انجام دهند.
یادگیری تقویتی چیست؟
یادگیری تقویتی یکی از چندین رویکرد توسعهدهندگان برای آموزش سیستمهای یادگیری ماشینی است. چیزی که این رویکرد را مهم میسازد این است که به یک عامل -چه ویژگی در یک بازی ویدیویی باشد و چه رباتی در محیط صنعتی- قدرت میدهد تا یاد بگیرد در پیچیدگیهای محیطی که برای آن ایجاد شده است حرکت کند و اقدامات صحیحی انجام دهد. با گذشت زمان، از طریق یک سیستم بازخورد که معمولا شامل پاداش و مجازات است، عامل از محیط خود می آموزد و رفتارهایش را بهینه میکند. در این روش فرآیند یادگیری عامل، پاداش و مجازات برای به حداکثر رساندن بهترین نتایج ادامه مییابد.
شاید علاقهمند باشید: یادگیری ماشین چیست؟
یادگیری تقویتی چطور کار میکند؟
مکانیسم آموزشی پشت یادگیری تقویتی، سناریوهای زیادی از دنیای واقعی را منعکس میکند. به عنوان مثال، آموزش حیوانات خانگی را از طریق ارائه پاداش به آنها در نظر بگیرید.
مثال اول نحوه کار یادگیری تقویتی
به این شکل دقت کنید.
هدف در این مورد آموزش سگ (عامل) برای تکمیل یک کار در محیط است که شامل محیط اطراف سگ و همچنین مربی میشود. ابتدا مربی دستور یا نشانهای را صادر میکند که سگ آن را میبیند (Observation یا مشاهده). سپس سگ با انجام یک اقدام به دستور مربی پاسخ میدهد. اگر عمل نزدیک به رفتار مورد انتظار باشد، مربی احتمالا پاداشی مانند غذا یا اسباببازی به او میدهد. در غیر این صورت پاداشی به سگ تعلق نمیگیرد.
در ابتدای آموزش، سگ احتمالا اقدامات اشتباهی مانند غلت زدن در زمانی که فرمان داده شده «بنشین» انجام میدهد؛ زیرا سعی دارد مشاهدات خاص را با اقدامات و پاداشها مرتبط کند. این ارتباط یا الگوبرداری بین مشاهدات و اقدامات خطمشی (Policy) نامیده میشود. از دیدگاه سگ حالت ایدهآل این است که به هر نشانهای به درستی پاسخ دهد، بهطوری که تا حد امکان پاداش بگیرد. بنابراین تمام معنای آموزش یادگیری تقویتی این است که ذهن سگ را به گونهای آموزش دهید که رفتارهای مورد نظر را بیاموزد و پاداشهای دریافتی را به حداکثر برساند. پس از اتمام آموزش، سگ باید بتواند صاحبش را مشاهده کند و اقدامات مناسب را انجام دهد. بهعنوان مثال، با استفاده از آموزشهای پیشین و ذهنیت صحیح کنونیاش، زمانی که دستور «نشستن» داده میشود، بنشیند. با اجرای صحیح دستورات، سگ قطعا پاداش دریافت میکند.

مثال دوم نحوه کار یادگیری تقویتی
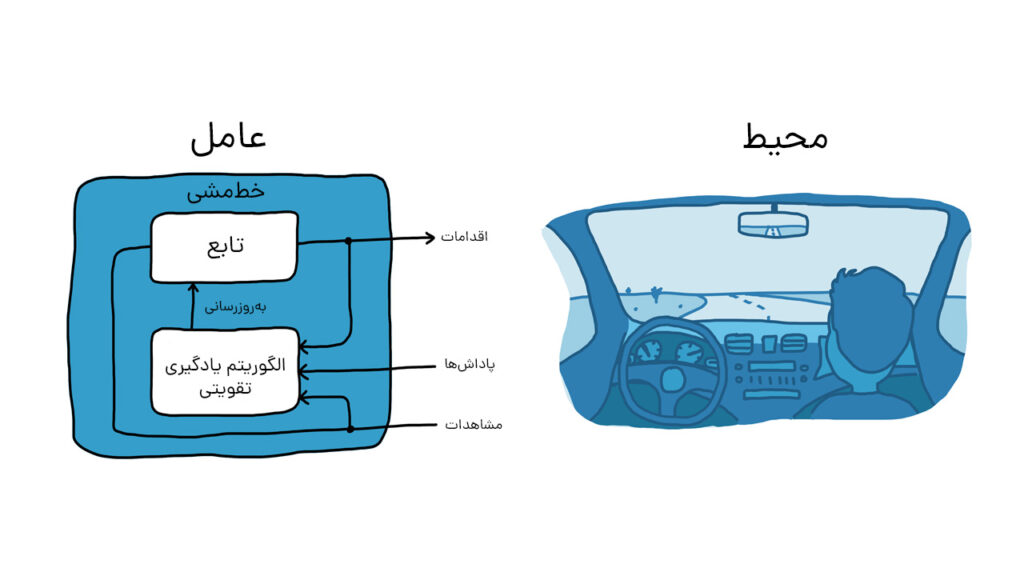
با در نظر گرفتن مثال آموزش سگ، وظیفه پارک وسیله نقلیه با استفاده از سیستم رانندگی خودکار را پیش میبریم (شکل زیر).
هدف این است که کامپیوتر (عامل) خودرو را با یادگیری تقویتی در محل صحیح پارک کند. در مثال آموزش سگ آنچه در خارج از عامل قرار دارد، محیط نامیده میشود، در این مثال نیز محیط میتواند شامل حرکت وسیله نقلیه در خیابان، حرکت وسایل نقلیه دیگری که ممکن است در نزدیکی باشند، شرایط آب و هوایی و غیره باشد. در طول تمرین، عامل از خواندن دادهها که توسط حسگرهایی مانند دوربینها، جیپیاس و لیدار بهعنوان مشاهدات دریافت میشوند برای تولید فرمانهایی نظیر ترمز و شتاب (عملکرد) استفاده میکند. برای یادگیری نحوه انجام اقدامات صحیح در مقابل مشاهدات (تنظیم خطمشی یا Policy)، کامپیوتر بارها سعی میکند وسیله نقلیه را با استفاده از فرآیند آزمون و خطا پارک کند. پس از انجام اقدام صحیح توسط عامل، یک سیگنال پاداش ارسال میشود تا این پیام را برساند که عمل بهدرستی انجام شده و فرآیند یادگیری باید ادامه یابد.
جمعبندی مثالها
در مثال آموزش سگ، یادگیری در مغز این حیوان اتفاق میافتد. در مثال پارک خودکار، آموزش توسط یک الگوریتم آموزشی مدیریت میشود. الگوریتم آموزشی مسئول تنظیم خطمشی عامل بر اساس دادههای دریافتی، اقدامات و پاداشهای جمعآوریشده است. پس از اتمام آموزش، کامپیوتر خودرو باید تنها با استفاده از خطمشی تنظیمشده و پردازش اطلاعات دریافتی از سنسورها بتواند پارک کند.
نکتهای که باید در نظر داشت این است که یادگیری تقویتی نمونهای کارآمد نیست؛ یعنی برای یادگیری و جمعآوری دادهها نیاز به تعداد زیادی تعامل بین عامل و محیط دارد. بهعنوان مثال، AlphaGo، اولین برنامه کامپیوتری برای شکست یک قهرمان جهانی در بازی Go، بدون وقفه برای مدت چند روز با انجام میلیونها بازی آموزش داده شد و هزاران سال دانش بشری را در حافظه خود ذخیره کرد. حتی برای برنامههای نسبتا ساده، زمان آموزش میتواند از چند دقیقه تا ساعتها یا روزها طول بکشد. همچنین شبیهسازی یک مشکل بهطور صحیح میتواند چالشبرانگیز باشد؛ زیرا فهرستی از مشکلات وجود دارد که باید طراحی شوند و برای یافتن راهحل مناسب ممکن است عامل به چندین بار تکرار عمل نیاز داشته باشد.
اما نام برخی از مهمترین روشهای تصمیمگیری در یادگیری تقویتی چیست؟ در ادامه به بررسی آنها میپردازیم.
روشهای تصمیمگیری در یادگیری تقویتی
چندین روش تصمیمگیری در یادگیری تقویتی وجود دارد که تفاوت آنها عمدتا به دلیل استراتژیهای مختلفی است که برای کشف محیط خود استفاده میکنند. در ادامه به برخی از پرکاربردترین روشهای تصمیمگیری در یادگیری تقویتی اشاره خواهیم کرد.
روشهای مبتنی بر ارزش (Value-Based)
این روشها بر میانگین ارزشهای آموختهشده تمرکز میکنند. روشهای مبتنی بر ارزش شامل جدولی از مقادیر هستند که عامل باید آنها را فرا بگیرد. این مقادیر نشاندهنده پاداش مورد انتظار برای انجام اقدامی خاص در یک وضعیت بهخصوص است. مقادیر در این روش پس از هر تعامل با محیط، بر اساس تفاوت بین پاداش مورد انتظار و پاداش واقعی بهروز میشوند. این بهروزرسانی به عامل اجازه میدهد تا از تعداد بیشتری از حالتها و اقدامات درس بگیرد و نتایج بهتری را به موقعیتهای جدید تعمیم دهد. Q-Learning و Deep Q-Learning دو نمونه از روشهای مبتنی بر ارزش هستند.
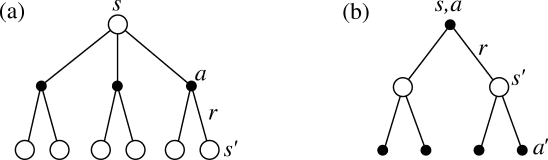
در شکل زیر عامل از حالت s با عمل a به وضعیت شکل دوم (b) رسیده است. سپس حالتهای s و a یک جفت شدهاند. پس از تعیین جفت s,a، عامل انتخاب ارزش تخمینی جفت حالت- عمل بعدی را توسط عمل r انجام میدهد و به همین ترتیب به بیشترین ارزش هر جفت میرسد.
یادگیری تقویتی مبتنی بر ارزش مانند داشتن یک نقشه گنج است که در آن ارزش مکانهای مختلف را با حفاری و یافتن پاداش میآموزید.
تصور کنید در حال کاوش در یک جزیره جدید به دنبال گنجینههای پنهان هستید. شما نقشهای دارید که میگوید کدام مکانها ممکن است گنج داشته باشند. هر بار که در یکی از آن مکانها مشغول حفاری میشوید، مقداری طلا پیدا میکنید. با گذشت زمان، متوجه میشوید که نقاط خاصی روی نقشه شما ارزشمندتر هستند؛ زیرا طلای بیشتری دارند.
یادگیری تقویتی مبتنی بر ارزش مشابه همین روش است. در این مورد شما کاوشگر یا عامل هستید، جزیره محیط است، نقشه درک عامل از اینکه کدام اقدامات یا تصمیمات ارزشمند هستند و طلا پاداشهایی است که عامل دریافت میکند. کاوشگر با انجام مکرر اقدامات، دریافت پاداش و بهروزرسانی درک خود از بهترین اقدامات برای به حداکثر رساندن پاداش، میآموزد که کدام اقدامات یا تصمیمات ارزشمندتر هستند.
در یادگیری تقویتی مبتنی بر ارزش، عامل بهترین اقدامات را برای به حداکثر رساندن پاداشها بر اساس تعامل خود با محیط میآموزد.
روش یادگیری مونت کارلو (Monte Carlo)
این روش نوعی الگوریتم یادگیری تقویتی است که از تجربه یاد میگیرد. عامل شروع یادگیری را با پاداشهایی که برای اقدامات مختلف دریافت میکند، کاوش تصادفی محیط و جمعآوری دادهها انجام میدهد. سپس از این دادهها برای تخمین ارزش هر جفت حالت- عمل استفاده میشود. در نهایت عامل اقدامی که بالاترین ارزش تخمینی را در پی دارد، انتخاب میکند.
تصور کنید سعی دارید بهترین راه را برای انجام یک بازی ویدیویی جدید بیابید. اما قوانین و اینکه کدام اقدامات منجر به بالاترین امتیاز میشوند را نمیدانید.
مونت کارلو در یادگیری تقویتی مانند این است که پس از چندین بار انجام بازی از دوستان خود راهنمایی بخواهید. شما بازی میکنید، اقداماتی را انجام میدهید و نتایج اقدامات خود را میبینید. هر بار که بازی را تمام میکنید، از دوستانتان میپرسید که در مورد اقدامات و نتیجه بازیتان چه فکر میکنند. در طول زمان، با جمعآوری نظرات آنها پس از بازیهای زیاد، شروع به دریافت ایدههای خوب میکنید که کدام اقدامات منجر به امتیازات بیشتر میشوند.
به عبارت فنیتر، مونت کارلو توسط یادگیری از تجربیات قبلی با شبیهسازی بسیاری از قسمتهای تعامل با محیط، کسب حداکثر پاداش را یاد میگیرد. پس از هر اپیزود از بازخوردی که از آن تجربیات دریافت کردهاید، استفاده میکنید تا درک خود را از اینکه کدام اقدامات خوب هستند و کدامها خوب نیستند، بدون نیاز به دانستن قوانین دقیق بازی از همان ابتدا، بهبود ببخشید.
روشهای تفاوت زمانی (Temporal Difference)
روشهای تفاوت زمانی یا TD (Temporal Difference) نوعی الگوریتم یادگیری تقویتی هستند که از تفاوت بین پاداش مورد انتظار و پاداش واقعی یاد میگیرند. عامل شروع یادگیری را با تخمین ارزش هر جفت حالت- عمل انجام میدهد. سپس این تخمینها را پس از هر تعامل با محیط بهروز میکند. بهروزرسانی بر اساس تفاوت بین پاداش مورد انتظار و پاداش واقعی انجام میشود.
بهطور مثال تصور کنید در حال پختن کلوچه هستید؛ اما هنوز زمان دقیق پخت را نمیدانید. بعد از پخته شدن تعدادی کلوچه، شما طعم و بافت هر کدام را با آنهایی که در دفعات قبلی پخته شده بودند، مقایسه میکنید. سپس تخمین خود را با در نظر گرفتن تفاوت دسته فعلی با موارد قبلی بهروز میکنید. در این مثال شما عامل هستید و نحوه پخت کلوچهها اعمال. حال در یادگیری تقویتی، هوش مصنوعی عامل است. با گذشت زمان و تکرارهای بیشتر، تخمین عامل هوش مصنوعی از بهترین زمان پخت دقیقتر میشود که منجر به نتایج بهتر میشود.
روشهای گرادیان خطمشی (Policy Gradient)
نوعی دیگر از الگوریتم RL که یک خطمشی را یاد میگیرند. خطمشی تابعی است که از حالتها به اقدامات صحیح میرسد. این شیوه با تخمین پاداش مورد انتظار با توجه به هر خطمشی، گرادیان را بهروز میکند.
بهطور مثال، در آموزش سگ، تصور کنید که به او یاد میدهید که بنشیند، اما گاهی اوقات او خیلی آهسته مینشیند یا اصلا نمینشیند. با استفاده از گرادیان خطمشی، میتوانید بر اساس میزان پیروی از خطمشی، به سگ پاداشهای مختلفی بدهید. بهعنوان مثال، اگر سگ سریع بنشیند، میتوانید غذای زیادی به او بدهید، اما اگر آرام بنشیند، میتوانید غذای کمی در اختیارش بگذارید. این تفاوت در پاداشها به سگ کمک میکند تا بفهمد کدام اقدامات بهتر است و او را تشویق میکند تا رفتار مورد انتظار را بهطور موثرتری انجام دهد. با تکرار مکرر این فرآیند، سگ به تدریج یاد میگیرد که این سیاست را بهتر و بیشتر دنبال کند. بهطور مشابه، در هوش مصنوعی، ما مدل را با مثالهای زیادی آموزش میدهیم و زمانی که تصمیمهای خوب میگیرد به آن پاداش میدهیم و وقتی تصمیمات بد میگیرد، جریمه میکنیم. این کار به هوش مصنوعی اجازه میدهد تا سیاست خود را بهبود بخشد و در موقعیتهای مختلف تصمیمات بهتری بگیرد.
هر کدام از این روشها از نظر پیچیدگی متفاوتند و برای انواع مختلفی از مشکلات بر اساس ماهیت محیط و اطلاعات موجود مناسب هستند. علاوه بر روشهای فوق، تعدادی تکنیک دیگر وجود دارد که میتوان از آنها برای بهبود فرآیند تصمیمگیری در یادگیری تقویتی استفاده کرد. این تکنیکها شامل موارد زیر میشوند.
اکتشاف حریصانه اپسیلون
تکنیکی است که به عامل اجازه میدهد در عین حال که پاداشهای بهینه را یاد میگیرد، محیط را هم کاوش کند. عامل با کاوش تصادفی محیط یادگیری را شروع میکند؛ اما با یادگیری بیشتر در مورد محیط حریصتر میشود و اقدامی را با بالاترین ارزش تخمینی انتخاب میکند.
پاسخ بر اساس تجربه
تکنیکی که تجربیات عامل را در یک بافر ذخیره میکند. این تجربیات ذخیرهشده به عامل اجازه میدهد تا با یادگیری از تعداد بیشتری از تجربیات بهطور کارآمدتری فرآیند آموزش را طی کند.
شکلدهی پاداش
این تکنیک پاداشهای موجود در محیط را تغییر میدهد تا مشکل را آسانتر حل کند. این کار را میتوان با افزودن پاداش برای رفتارهای دلخواه یا با حذف پاداش برای رفتارهای ناخواسته انجام داد.
انواع روشهای یادگیری در یادگیری تقویتی
عمدتا دو نوع روش در یادگیری تقویتی وجود دارد که عبارتند از:
- تقویت مثبت
- تقویت منفی
در ادامه به تفصیل هر یک را توضیح خواهیم داد.

تقویت مثبت
یادگیری تقویتی به شیوه مثبت به این صورت تعریف میشود که یک رویداد به دلیل رفتاری خاص رخ میدهد که منجر به افزایش قدرت و فراوانی رفتار عامل میشود. ویژگیهای تقویت مثبت به شرح زیر است:
- عملکرد عامل را به حداکثر میرساند.
- تغییر را برای مدت طولانی حفظ میکند.
- تقویت بیش از حد رفتارهای صحیح میتواند نتایج درست را کاهش دهد.
تصور کنید یک سگ دارید و میخواهید او را برای نشستن آموزش دهید. میتوانید از تکنیکی به نام تقویت مثبت استفاده کنید که به معنای پاداش دادن به سگ برای نشستن است. هر بار که سگ مینشیند، به او جایزه میدهید. با گذشت زمان، سگ یاد میگیرد که نشستن چیز خوبی است و احتمال انجام آن بیشتر خواهد بود.
در تقویت مثبت عامل یاد میگیرد که اقداماتی را انجام دهد که احتمال بیشتری برای پاداش دارد.
تقویت منفی
یادگیری تقویتی منفی در مقابل تقویت مثبت است؛ زیرا با اجتناب از شرایط منفی، تمایل به تکرار رفتار خاص را افزایش میدهد. بهعبارتی این شیوه از یادگیری بهعنوان تقویت رفتار تعریف میشود؛ زیرا عامل از تکرار یک وضعیت منفی اجتناب میکند. این روش بسته به موقعیت و رفتار میتواند موثرتر از تقویت مثبت باشد. از مزایای تقویت منفی میتوان به موارد زیر اشاره کرد:
- رفتار صحیح را افزایش میدهد.
- سرپیچی را به حداقل میرساند.
- این شیوه برای انجام حداقل رفتار مناسب است.
بهطور مثال، کودکی را تصور کنید که همزمان در حال جیغ زدن و گریه کردن است. در تقویت منفی، والدین کودک به او میگویند: «ناله نکن؛ وگرنه اسباببازیت را میگیرم.» کودک غر زدن را متوقف میکند؛ زیرا نمیخواهد اسباببازی خود را از دست بدهد. بنابراین رفتار ناله نکردن با حذف محرک بد (تهدید از دست دادن اسباببازی) تقویت میشود.
مثال دیگری از تقویت منفی، دانشآموزی است که برای آزمون مطالعه میکند. دانشآموز به این دلیل مطالعه میکند که نمیخواهد در آزمون مردود شود. بنابراین رفتار مطالعه با حذف محرک بد (عدم شکست در آزمون) تقویت میشود.
توجه به این نکته ضروری است که تقویت منفی با تنبیه یکسان نیست. تنبیه اعمال یک محرک ناخوشایند و آزاردهنده برای حذف یک رفتار است. در مقابل، تقویت منفی حذف یک محرک ناخوشایند یا بد برای تشویق یک رفتار است. تقویت منفی میتواند راهی موثر برای تغییر رفتار باشد، اما استفاده از آن باید با دقت زیادی انجام شود.
انواع وظایف در یادگیری تقویتی چیست؟
وظیفه نمونهای از یک مشکل در یادگیری تقویتی است. انواع وظایف در یادگیری تقویتی شامل اپیزودیک و ادامهدار میشوند.
وظایف اپیزودیک
وظایف اپیزودیک وظایفی هستند که شروع و پایان مشخصی دارند. عامل در یک حالت شروع به کار میکند، دنبالهای از اقدامات را انجام میدهد و در نهایت به یک حالت پایانی میرسد. هدف عامل به حداکثر رساندن کل پاداشی است که در طول یک اقدام دریافت میکند. برخی از نمونههای وظایف اپیزودیک شامل انجام یک بازی تیک-تاک-تو و حرکت در هزارتو است.
وظایف ادامهدار
کارهای ادامهدار پایان مشخصی ندارند. عامل میتواند بهطور نامحدود به تعامل با محیط ادامه دهد. هدف عامل به حداکثر رساندن پاداش مورد انتظار در طول زمان است. برخی از نمونههای وظایف ادامهدار شامل معامله سهام یا کنترل یک ربات است.
یادگیری تقویتی با سایر روشهای یادگیری ماشین چه تفاوتی دارد؟
یادگیری تقویتی شاخهای از یادگیری ماشین است. با این حال، شباهتهایی با انواع دیگر Machine Learning دارد که به سه حوزه زیر تقسیم میشوند.
تفاوت یادگیری تقویتی با یادگیری تحت نظارت
در یادگیری نظارتشده (Supervised learning)، الگوریتمها توسط مجموعهای از دادههای برچسبدار و دستهبندیشده آموزش میبینند. الگوریتمهای یادگیری تحت نظارت فقط میتوانند ویژگیهایی را یاد بگیرند که در مجموعه دادهها مشخص شدهاند. این مدلها مجموعهای از تصاویر برچسبگذاریشده را دریافت میکنند و یاد میگیرند که ویژگیهای رایج تصاویر از پیش تعریفشده را تشخیص دهند. یکی از کاربردهای رایج یادگیری تحت نظارت، مدلهای تشخیص تصویر است.
تفاوت یادگیری تقویتی با یادگیری بدون نظارت
در یادگیری بدون نظارت (Unsupervised learning) توسعهدهندگان الگوریتمها را توسط دادههای بدون برچسب آموزش میدهند. الگوریتمها با فهرست کردن مشاهدات خود در مورد ویژگیهای داده، بدون اینکه به آنها گفته شود به دنبال چه چیزی بگردند، یاد میگیرند که چگونه نتایج صحیح ارائه دهند.
تفاوت یادگیری تقویتی با یادگیری نیمه نظارتی
یادگیری نیمه نظارتی (Semi Supervised learning) رویکردی میانی دارد. توسعهدهندگان مجموعه نسبتا کمی از دادههای آموزشی برچسبگذاریشده و همچنین مجموعه بزرگتری از دادههای بدون برچسب را به الگوریتم میدهند. سپس به الگوریتم دستور داده میشود تا آنچه را که از دادههای برچسبگذاری شده میآموزد به دادههای بدون برچسب تعمیم دهد و از مجموع آنها بهعنوان یک الگوی کلی نتیجهگیری کند.
یادگیری تقویتی شبیه یادگیری تحت نظارت است که توسعهدهندگان باید اهداف مشخصی را به الگوریتمها بدهند و توابع پاداش و مجازات را تعریف کنند. این بدان معناست که برنامهنویسی در یادگیری تقویتی بیشتر از یادگیری بدون نظارت نیاز است. اما زمانی که این پارامترها تنظیم شوند، الگوریتم به تنهایی عمل میکند که همین موضوع باعث میشود الگوریتمهای RL بیشتر از الگوریتمهای یادگیری تحت نظارت خودساخته باشند. به همین دلیل مردم گاهی از یادگیری تقویتی بهعنوان شاخهای از یادگیری نیمه نظارتی یاد میکنند.
یادگیری تقویتی چه کاربردهایی دارد؟

یادگیری تقویتی امروزه بهعنوان یک رویکرد در حال بررسی است و توسط کمپانیهای مشهور در مرحله آزمایش قرار دارد. در ادامه به انواع کاربردهای یادگیری تقویتی میپردازیم.
رباتیک
RL در مسیریابی ربات، فوتبال رباتیک، پیادهروی، شعبدهبازی و غیره استفاده میشود.
کنترل
یادگیری تقویتی را میتوان برای کنترل تطبیقی مانند فرآیندهای تولید در کارخانه و کنترل پذیرش در مخابرات استفاده کرد. خلبان هلیکوپتر نمونهای از یادگیری تقویتی است.
بازی
RL را میتوان در بازیهایی مانند تیک-تاک-تو (Tic-Tac-Toe)، شطرنج و غیره استفاده کرد.
علم شیمی
Reinforcement Learning میتواند برای بهینهسازی واکنشهای شیمیایی استفاده شود.
تولید
در شرکتهای مختلف خودروسازی، رباتها از یادگیری تقویتی برای چیدن کالاها و قرار دادن آنها در برخی ظروف استفاده میکنند.
بخش مالی
RL در حال حاضر در بخش مالی برای ارزیابی استراتژیهای معاملاتی استفاده میشود.
ماشینهای خودران
اتخاذ تصمیمات رانندگی بر اساس دادههای ورودی از دوربین و میکروفن و… است که یادگیری تقویتی را مناسب ماشینهای خودران میکند.
برنامهریزی
مشکلات زمانبندی در بسیاری از موقعیتها از جمله کنترل چراغ راهنمایی و هماهنگی منابع در کارخانه مشهود است. یادگیری تقویتی جایگزین خوبی برای حل این گونه مسائل است. RL امروزه برای برنامهریزی استراتژی کسبوکار هم استفاده میشود.
کالیبراسیون
برنامههایی که شامل کالیبراسیون دستی پارامترها میشوند، مانند کالیبراسیون واحد کنترل الکترونیکی (ECU)، ممکن است نامزدهای خوبی برای یادگیری تقویتی باشند.
شاید علاقهمند باشید: کاربردهای یادگیری ماشین
آیا کار با یادگیری تقویتی مشکل است؟
پاسخ کوتاه به این سوال «بله» است. کار با یادگیری تقویتی کمی دشوار بوده و نیاز به زمان زیادی دارد. در ادامه به برخی از چالشهای یادگیری تقویتی اشاره میکنیم.
نیاز به دادههای زیاد
الگوریتمهای یادگیری تقویتی به دادههای زیادی برای یادگیری نیاز دارند. جمعآوری این دادهها بهخصوص در محیطهای پیچیده و پویا میتواند دشوار و پر هزینه باشد.
برقراری تعادل بین اکتشاف و اقدامات
عوامل یادگیری تقویتی باید بین کاوش حالتها و اقدامات جدید تعادل برقرار کنند. این تعادل بهمنظور یادگیری از محیط و به حداکثر رساندن پاداشها انجام میشود. مدیریت این امر میتواند سخت باشد، بهخصوص در محیطهایی با پاداشهای کم.
پایداری
الگوریتمهای یادگیری تقویتی میتوانند ناپایدار باشند؛ به این معنی که امکان دارد واگرا شوند یا در انتخاب بهترین پاسخ گیر کنند. پرداختن به این موضوع بهویژه در محیطهای پیچیده و پویا میتواند چالشبرانگیز باشد.
تفسیرپذیری
الگوریتمهای یادگیری تقویتی جزو الگوریتمهای جعبههای سیاه هستند؛ به این معنی که درک دلیل تصمیمگیری آنها ممکن است دشوار باشد. این موضوع میتواند یک چالش برای برنامههای کاربردی ایمنی و حیاتی باشد.
علیرغم این چالشها، یادگیری تقویتی یک تکنیک قدرتمند است که میتواند برای حل طیف گستردهای از مشکلات استفاده شود. همانطور که یادگیری تقویتی در حال توسعه است، به این چالشها هم رسیدگی میشود؛ بدین معنا که در آینده شاهد دسترسیپذیری و کاربردهای بیشتر این شیوه خواهیم بود.
انواع رویکردهای یادگیری تقویتی
هدف انواع رویکردهای یادگیری تقویتی به حداکثر رساندن پاداش در طول زمان است که در ادامه آنها را بررسی میکنیم.
یادگیری تقویتی ارزش محور
در این روش، تمرکز بر یادگیری تابع مقدار بهینه است که با Q* یا V* نشان داده میشود. تابع ارزش پاداشهای تجمعی آینده مورد انتظار را برای قرار گرفتن در یک وضعیت معین و پیروی از سیاست فعلی پس از آن تخمین میزند. روشهای متداول ارزش محور عبارتند از یادگیری Q، SARSA و یادگیری تفاوت زمانی (TD).
سیاست محور
روش های یادگیری تقویتی سیاست محور بهطور مستقیم خط مشی مدل را بهینه میکنند؛ درحالیکه تکنیکهای مبتنیبر ارزش بهدنبال یافتن تابع ارزش بهینه هستند که به نوبه خود بهترین خط مشی را ارائه میدهد.
یادگیری تقویتی سیاست محور از سه الگوریتم Q-Learning، SARSA و Actor-Critic استفاده میکند.
مدل محور
یادگیری تقویتی مدل محور مانند پسر عموی باهوش خانواده RL است؛ جاییکه عامل بهشکل کورکورانه به محیط واکنش نشان نمیدهد. در عوض با ایجاد نسخه کوچکی از خود تلاش دارد رویدادهای آینده را پیشبینی کند. این مدل حرکات مختلف را امتحان میکند تا ببیند در آینده چه اتفاقی میافتد.
در این شیوه، عامل میتواند سناریوهایی را در مدل خود اجرا کند، بدون آنکه نتیجه منفی بگیرد؛ درست مانند چیدن استراتژی حرکت در بازی شطرنج پیش از لمس مهره.
یادگیری تقویتی عمیق
یادگیری تقویتی عمیق (Deep Reinforcement Learning (DRL)) ادغام دو حوزه هوش مصنوعی قدرتمند است: شبکههای عصبی عمیق و یادگیری تقویتی.
در این روش مزایای شبکههای عصبی مبتنیبر داده و تصمیمگیری هوشمند ادغام و قدرتی خارقالعاده به مدل اعطا میشود.
یادگیری تقویتی عمیق با تعامل مکرر با یک محیط و انتخابهایی که پاداشهای تجمعی را به حداکثر میرساند، عوامل را قادر میسازد تا استراتژیهای پیچیده را بیاموزند.
عاملها به لطف DRL قادرند بهصورت مستقیم قوانین را از ورودیهای حسی بیاموزند. سپس با کمک گرفتن از توانایی یادگیری عمیق، ویژگیهای پیچیده را از دادههای بدون ساختار استخراج میکند.
DRL بهشدت به یادگیری Q، روشهای گرادیان خط مشی و سیستمهای Actor-Critic متکی است.
کاربردهای DRL حوزههای گستردهای را پوشش میدهد؛ ازجمله رباتیک، بازی، بانکداری و مراقبتهای بهداشتی.
محدودیت های یادگیری تقویتی
محدودیت های یادگیری تقویتی میتواند مهندسان و توسعهدهندگان هوش مصنوعی را آگاه سازد تا با دانش کافی، از بهترین روشهای یادگیری ماشین استفاده کنند. در ادامه به این محدودیتها اشاره خواهیم کرد.
- یادگیری تقویتی برای حل مسائل ساده پیشنهاد نمیشود؛
- این روش به دادههای بسیار و محاسبات زیادی نیاز دارد؛
- یادگیری تقویتی بهشدت به کیفیت عملکرد پاداش بستگی دارد. اگر تابع پاداش بد طراحی شده باشد، ممکن است عامل رفتار موردنظر را یاد نگیرد؛
- اشکالزدایی و تفسیر الگوریتمهای یادگیری تقویتی گاهی دشوار است. همیشه مشخص نیست که چرا عامل به روش خاصی رفتار میکند. این موضوع میتواند تشخیص و رفع مشکلات را دشوار کند.
آنچه در یادگیری تقویتی خواندیم
یادگیری تقویتی (Reinforcement Learning) حوزهای از یادگیری ماشینی (Machine Learning) است. یادگیری تقویتی مانند یادگیری نظارتشده از پیش آموزش نمیبیند؛ بلکه عامل که عموما یک کامپیوتر است یاد میگیرد که چگونه با انجام آزمون و خطا، پاسخهای صحیح را افزایش داده و انجام امور متفاوت را یاد بگیرد. درواقع عامل یادگیری تقویتی باید در غیاب یک مجموعه داده آموزشی از تجربه خود درس بگیرد.
در RL دادهها توسط سنسورها، میکروفن و… جمعآوری میشوند و عامل با پردازش این اطلاعات سعی در انتخاب بهترین تصمیم میگیرد.
یادگیری تقویتی از الگوریتمهایی استفاده میکند که از نتایج درس گرفته و تصمیم میگیرند کدام اقدام بعدی را بهدرستی انجام دهند. پس از هر اقدام، الگوریتم بازخوردی دریافت میکند که امکان تشخیص درست، خنثی یا نادرست بودن تصمیم را به عامل میدهد. این فرآیند یک تکنیک خوب برای استفاده از سیستمهای خودکار است که باید تصمیمات کوچک زیادی را بدون راهنمایی انسان بگیرند.
در این مقاله تلاش کردیم تا ضمن پاسخ دادن به پرسش «یادگیری تقویتی چیست؟» شما را با مفاهیم پیرامون این حوزه کمی آشنا تر کنیم. اگر سوال و ابهامی دارید یا اگر نکتهای در ذهن شماست که میتواند برای دوستانتان مفید باشد حتما آن را در بخش نظرات با ما و دوستانتان به اشتراک بگذارید.
1. یادگیری تقویتی و هدف آن چیست؟
یادگیری تقویتی تکنیکی در Machine Learning و توسعه هوش مصنوعی است که در آن یک عامل با انجام اقداماتی در محیط و دریافت پاداش (بازخورد مثبت) یا جریمه (بازخورد منفی) اعمال خود، رفتارهای بعدی را یاد میگیرد. هدف این تکنیک به حداکثر رساندن پاداش است.
1) عامل: تصمیمگیرندهای که در محیط به انجام اقداماتی میپردازد. 2) محیط: از طریق پاداش یا جریمه به عامل بازخورد میدهد.
آموزش عوامل هوش مصنوعی برای انجام بازیها (مانند بازی AlphaGo)، بهینهسازی سیستمهای کنترل چراغ راهنمایی یا وظایف مربوط به کنترل ربات، همگی از نمونههای بهکارگیری Reinforcement Learning در دنیای واقعی هستند.