آشنایی با الگوریتم های یادگیری ماشین

ML از طریق آموزش یادگیری ماشین به یک امر فراگیر تبدیل شده و امروزه بر جنبههای بسیار زیادی از امور و سرگرمیهای ما سایه انداخته است؛ از الگوریتمهای رتبهبندی موتورهای جستوجو و تجزیهوتحلیل تصاویر اشعه ایکس تا پیشنهاد ویدیو در یوتیوب. با چنین طیف گستردهای از کاربردها، با توجه به تحقیقات موسسه Fortune Business Insights، پیشبینی میشود که بازار جهانی Machine Learning از 21.7 میلیارد دلار در سال 2022 به 209.91 میلیارد دلار تا سال 2029 برسد. در این مقاله از کوئرا بلاگ تلاش داریم 10 مورد از معروف ترین الگوریتم های یادگیری ماشین را با یکدیگر بررسی کنیم و به عملکرد هر یک بپردازیم.
اگر هنوز مطمئن نیستید که یادگیری برنامهنویسی برایتان مناسب است یا نه، یا نمیدانید از کجا شروع کنید، ما یک کوییز ساده و جذاب آماده کردهایم که میتواند به شما کمک کند مسیر درست را پیدا کنید.
همین حالا امتحان کنید: برنامه نویسی را از کجا شروع کنیم
یادگیری ماشین چیست؟
یادگیری ماشین (ML) شاخهای از هوش مصنوعی و علوم کامپیوتر است که برای یادگیری انجام امور بر استفاده از دادهها و الگوریتمها تمرکز دارد و به تدریج با گذر زمان دقت خود را بیشتر میکند. الگوریتم های یادگیری ماشین در بسیاری از برنامهها و ابزارهایی که روزانه از آنها استفاده میکنیم وجود دارند؛ مانند موتور جستوجوی گوگل. یکی از دلایل قدرت روزافزون این موتور جستوجو قدرت یادگیری رتبهبندی صفحات است که بدون برنامههای از پیش نوشتهشده انجام میشود. این الگوریتمها برای اهداف مختلفی مانند دادهکاوی، تجزیهوتحلیل، پردازش تصویر و پیشبینی استفاده میشوند. مزیت اصلی استفاده از یادگیری ماشین این است که یکبار به ماشین آموزش میدهیم که چه کاری انجام دهد؛ سپس ماشین پردازش اطلاعات و انجام امور را بهصورت اتوماتیک پیش خواهد برد.
بیشتر بخوانید: یادگیری ماشین چیست؟ همه چیز درباره Machine Learning
بیشتر بخوانید: پردازش تصویر چیست و چه کاربردهایی دارد؟
چند نوع الگوریتم یادگیری ماشین داریم؟
به زبان ساده، الگوریتم های ماشین لرنینگ مانند دستورالعملی هستند که به رایانهها اجازه میدهند انجام امور را یاد بگیرند و از دادهها و تحلیل آنها بهمنظور پیشبینی استفاده کنند. به جای اینکه صریحا به رایانه بگوییم چه کاری انجام دهد، مقدار زیادی داده در اختیار آن قرار میدهیم تا الگوها و روابط را کشف کند. در حال حاضر سه نوع از انواع الگوریتم های یادگیری ماشین داریم که عبارتند از:
یادگیری تحت نظارت (Supervised Learning)
یادگیری تحت نظارت نوعی از الگوریتم های یادگیری ماشین است که در آن از مجموعه دادههای برچسبگذاری شده برای آموزش مدل استفاده میکنیم. هدف این الگوریتم یادگیری تشخیص الگوها در میان دادههای ورودی است که به آن امکان میدهد پیشبینیها یا طبقهبندیهایی را روی دادههای جدید انجام دهد. این نوع شامل دو الگوریتم Regression و Classification میشود.
یادگیری بدون نظارت (Unsupervised Learning)
یادگیری بدون نظارت نوعی از الگوریتم های ماشین لرنینگ است که در آن الگوریتمها برای یافتن الگوها، ساختار یا رابطه درون مجموعهای از اطلاعات، از دادههای انبوه و بدون علامت استفاده میکنند. در این الگوریتمها، ماشین با استفاده از تحلیل دادههای بدون دسته یا برچسبهای از پیش تعریفشده پیشبینی و عملکرد را بررسی میکند. این نوع الگوریتم یادگیری ماشین شامل دو نوع Clustering و Dimensionality Reduction نیز میشود.
یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی نوعی از الگوریتم های یادگیری ماشین است که در آن یک عامل یاد میگیرد با تعامل با محیط اطراف خود تصمیمات صحیح بگیرد. هدف عامل کشف تاکتیکهای بهینه است تا در طول زمان از طریق آزمونوخطا پاداشها را به حداکثر برساند. یادگیری تقویتی اغلب در سناریوهایی به کار میرود که در آن عامل باید یاد بگیرد که چگونه در یک محیط حرکت کند، بازی را انجام دهد، رباتها را مدیریت یا در موقعیتهای نامشخص قضاوت کند.
بیشتر بخوانید: یادگیری تقویتی یا Reinforcement Learning چیست؟
معروف ترین الگوریتم های یادگیری ماشین
معروف ترین الگوریتم های یادگیری ماشین از انواع یادگیری تحت نظارت، بدون نظارت و یادگیری تقویتی هستند که در ادامه به آنها اشاره خواهیم کرد.
1.Linear Regression
این الگوریتم در زبان فارسی با نام «رگرسیون خطی» یا «پیشبینی خطی» خوانده میشود. از رگرسیون خطی برای پیشبینی مقادیر پیوسته مانند قیمت خانه، فروش یا حقوق استفاده میشود. Linear Regression توسط یافتن یک رابطه خطی بین متغیر وابسته (چیزی که میخواهید پیشبینی کنید) و یک یا چند متغیر مستقل (چیزهایی که میتوانند بر متغیر وابسته تاثیر بگذارند) کار خود را انجام میدهد.
رگرسیون خطی به ما کمک میکند بفهمیم که چگونه عوامل مختلف میتوانند بر قیمت یک چیز تاثیر بگذارند و بر اساس آن رابطه بین دادهها را پیشبینی کنیم. این کار مانند یافتن یک روند یا الگو در دادهها است که به ما کمک میکند تا حدسهای آگاهانهای درباره آینده داشته باشیم. این الگوریتم برای پیشبینی استفاده میشود و برای دستهبندی ورودیها کاربردی ندارد.
مثال پیشرو، پیشبینی فروش اسباببازی بر اساس ویژگیهای آن است. تصور کنید یک دسته اسباببازی دارید و میخواهید بدانید با چه قیمتی میتوانید آنها را بفروشید. رگرسیون خطی مانند تلاش برای یافتن یک خط مستقیم است که رابطه بین قیمت اسباببازی و ویژگیهای مختلف آن مانند اندازه، رنگ یا سن را به بهترین نحو نشان دهد.
بنابراین، با جمعآوری دادههایی در مورد میزان فروش هر اسباببازی در گذشته، همراه با ویژگیهای آنها شروع میکنید. سپس، روی یک نمودار خطی میکشید که تا حد امکان به تمام نقاط داده نزدیک باشد. این خط نشاندهنده رابطه بین ویژگیهای اسباببازی و قیمت آن است.
2.Logistic Regression
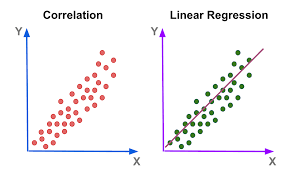
رگرسیون لجستیک نوعی الگوریتم Supervised Learning است که میتواند برای پیشبینی نتایج باینری استفاده شود، مانند اینکه آیا مشتری محصولی را میخرد یا نه، آیا فرد مبتلا به بیماری است یا نه، یا اینکه دانشآموز نمره قبولی را اخذ میکند یا نه.
رگرسیون لجستیک تصمیمگیری را بر اساس یافتن رابطه بین متغیر وابسته (نتیجه باینری که میخواهید پیشبینی کنید) و یک یا چند متغیر مستقل (چیزهایی که میتوانند بر متغیر وابسته تاثیر بگذارند) انجام میدهد.
بهطور مثال تصور کنید مجموعه دادهای از مشتریان و تاریخچه خرید آنها دارید. حال میخواهید از این مجموعه داده برای آموزش یک مدل رگرسیون لجستیک برای پیشبینی اینکه آیا مشتری جدید یک محصول را خریداری میکند یا خیر استفاده کنید.
مدل رگرسیون لجستیک رابطهای بین سابقه خرید مشتری و اینکه آیا محصول را خریده است یا خیر پیدا میکند. بهعنوان مثال، مدل ممکن است متوجه شود که مشتریانی که محصولات مشابهی را در گذشته خریداری کردهاند، احتمالا محصول جدید را نیز میخرند.
هنگامی که مدل توسط الگوریتم رگرسیون لجستیک آموزش داده شد، میتوانید از آن برای پیشبینی اینکه آیا مشتری جدید محصول را میخرد یا خیر، با دادن تاریخچه خرید مشتری به آن استفاده کنید.
میتوان از این الگوریتم برای برنامههایی مانند طبقهبندی ایمیلهای اسپم و کنترل کیفیت در خط تولید استفاده کرد. این مدل برای دستهبندی مقادیر ورودی بهترین گزینه است.
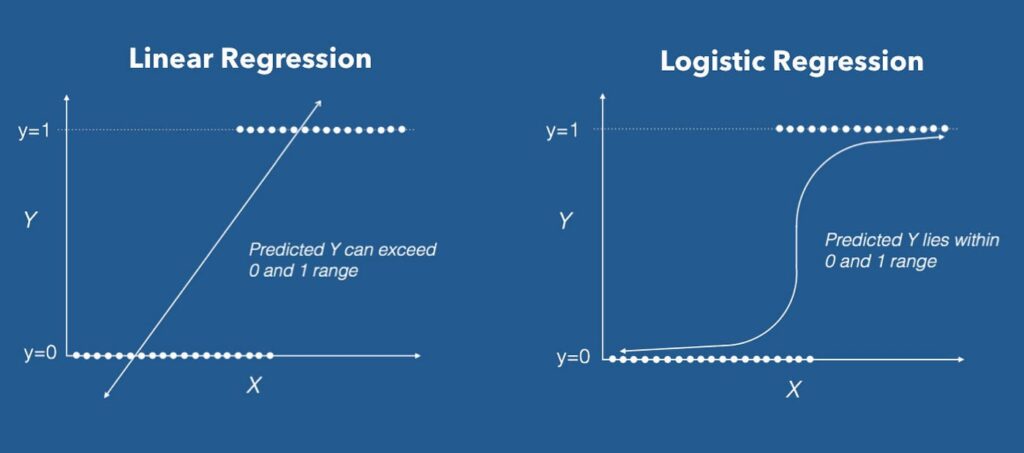
3.KNN (K-nearest Neighbour)
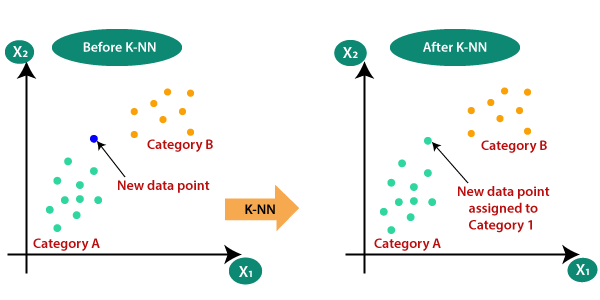
در این الگوریتم تصمیمگیری مدل بر اساس همسایههای نزدیک نقطه جدید است. K در واقع مجموعهای از نزدیکترین همسایهها هستند که میتوانند به مدل کمک کنند نقطه جدید را برچسبگذاری کند و آن را در گروه خاصی قرار دهد. در واقع مدل یاد میگیرد که با نگاه کردن به همسایههای نقطه جدید، ویژگیهای آن را تشخیص دهد.
این مثال ساده در دنیای واقعی میتواند نحوه عملکرد الگوریتم KNN را نشان دهد. یک شرکت میخواهد سیستم توصیه محصول برای وبسایت خود طراحی کند. این شرکت مجموعه دادهای از تاریخچه خرید مشتری و اطلاعات محصول دارد. حال میتواند از این مجموعه داده برای آموزش یک مدل KNN استفاده کند. این مدل رابطه بین محصولاتی را که مشتریان در گذشته خریداری کردهاند و محصولاتی که احتمالا در آینده خواهند خرید را یاد میگیرد. پس از آموزش مدل، شرکت میتواند از آن برای توصیه محصولات به مشتریان جدید بر اساس سابقه خرید آنها استفاده کند.
KNN یک الگوریتم ساده و همه کاره است که میتواند برای کارهای طبقهبندی و پیشبینی استفاده شود. این الگوریتم یادگیری ماشین اغلب برای دستهبندی تصاویر، متن و تشخیص تقلب استفاده میشود. KNN بهترین الگوریتم برای خوشهبندی مقادیر است.
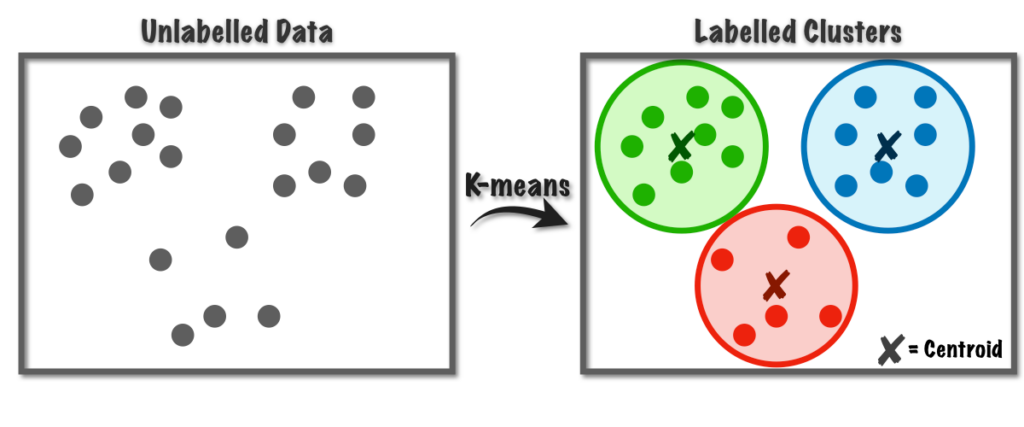
4.K-Means Clustering
خوشهبندی K-Means یک رویکرد یادگیری بدون نظارت است که میتواند برای گروهبندی دادهها در خوشهها استفاده شود. این الگوریتم مشابه KNN است؛ زیرا همچنان از روش نزدیکترین همسایه و گروهبندی همسایهها با یکدیگر استفاده میکند. خوشهها به گروهی از نقاط داده میگویند که مشابه یکدیگر و با نقاط داده در سایر خوشهها متفاوت هستند. خوشهبندی K-Means کار خود را با انتخاب مرکز خوشه، k شروع میکند. سپس بهصورت تصادفی هر نقطه داده را به یکی از خوشههای k اختصاص میدهد. پس از آن مرکز هر خوشه را محاسبه میکند. هنگامی که مرکزها محاسبه شدند، K-Means Clustering هر نقطه داده را به خوشهای که نزدیکترین مرکز را دارد، اختصاص میدهد. این فرآیند تا زمانی تکرار میشود که هیچ نقطه دادهای باقی نماند. در این الگوریتم نقاط داده در هر خوشه تا حد امکان شبیه یکدیگر و در عین حال تا حد ممکن از نقاط داده در سایر خوشهها متمایز هستند.
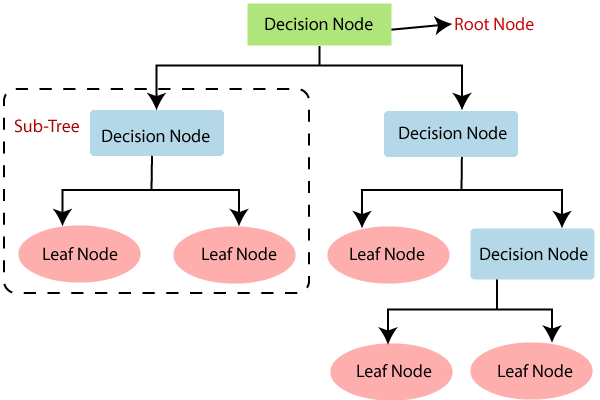
5.Decision Tree
درخت تصمیم نوعی تکنیک یادگیری با نظارت (Supervised Learning) است که برای طبقهبندی و همچنین رگرسیون استفاده میشود. این الگوریتم با تقسیم دادهها به گروههای کوچکتر تصمیم میگیرد؛ تا زمانی که دیگر دادهای وجود نداشته باشد. در واقع درخت تصمیم یک ساختار درختمانند است که با یک گره ریشه شروع و به گرههای فرزند منشعب میشود. هر گره یک شرط را بررسی میکند و برگهای درخت در Decision Tree نتایج ممکن هستند. فرض کنید میخواهید تصمیم بگیرید امروز چه لباسی را بپوشید. ممکن است انتخاب لباس مناسب را با پرسیدن چند سوال از خود شروع کنید:
- بیرون گرم است یا سرد؟
- آفتابی است یا بارانی؟
- در حال رفتن به محل کار هستم یا مدرسه؟
هر سوال یک گره است که ما را به شاخههای مختلفی هدایت میکند. هر شاخه نیز دارای برگهایی است که این برگها معادل پاسخی برای پرسش هستند. در نهایت تصمیمگیری نهایی زمانی انجام میشود که به آخرین برگ برسیم و دیگر سوالی وجود نداشته باشد. درخت تصمیم یکی از بهترین الگوریتم های یادگیری ماشین است که آن را مناسبترین گزینه برای حل مسائل پیچیده میسازد.
بیشتر بخوانید: درخت تصمیم (Decision Tree) – تعریف، مزایا و کاربردها
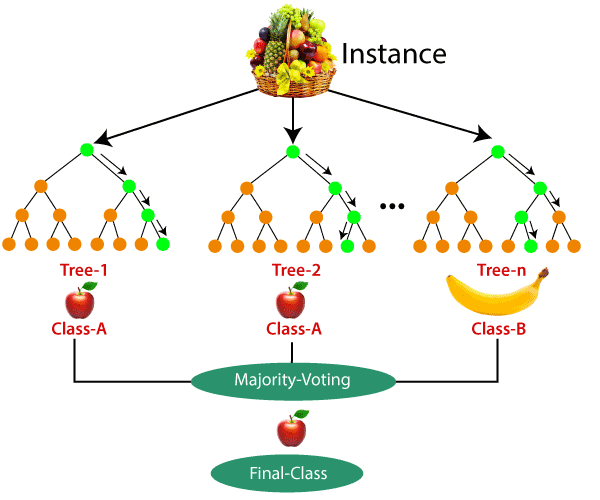
6.Random Forest
یکی از مشکلات درخت تصمیم دشواری آن در تعمیم یک مسئله است. برای حل این مشکل، نوع جدیدی از الگوریتم درخت تصمیم با جمعآوری درختهای متعدد ایجاد شد. در این الگوریتم که جنگل تصادفی نام دارد، تصمیمگیری درباره بهترین نتیجه با استفاده از یک سیستم رایگیری یا میانگینگیری از هر گروه انجام میشود. جنگل تصادفی نوعی روش یادگیری گروهی است که در آن درختان برای تصمیمگیری و پیشبینی با یکدیگر همکاری میکنند.
تصور کنید در حال انجام بازی قایمباشک با دوستان خود هستید. در این بازی تلاش دارید بهترین نقطه برای قایم شدن را بیابید؛ بنابراین تصمیم میگیرید از هر یک از دوستانتان نظرشان را بپرسید. هر یک از آنها پیشنهاد متفاوتی میدهد. برخی از پیشنهادها خوب و برخی بد هستند. اما اگر همه پیشنهادها را بشنوید و از همه آنها یک میانگین بگیرید، به احتمال زیاد مکانی خوب برای پنهان شدن پیدا خواهید کرد. پرسیدن نظر همه دوستانتان بهتر از تصمیمگیری انفرادی است. اساسا الگوریتم جنگل تصادفی نیز به همین صورت عمل میکند. این الگوریتم یک دسته از درختان تصمیمگیری را جمع میکند و از پیشبینی آنها میانگین میگیرد. این کار باعث میشود الگوریتم جنگل تصادفی دقیقتر از درخت تصمیم باشد.
بیشتر بخوانید: آشنایی کامل با الگوریتم Random Forest
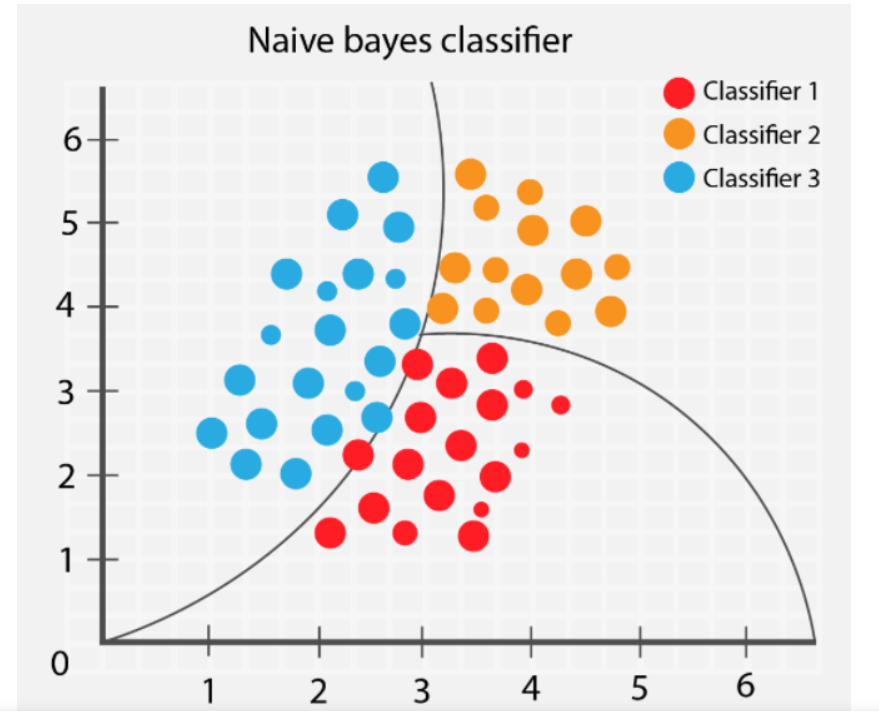
7.Naive Bayes
بیز ساده یک الگوریتم ماشین لرنینگ بر اساس قضیه بیز است که برای دستهبندی استفاده میشود. این الگوریتم با فرض اینکه ویژگیهای یک نقطه داده مستقل از یکدیگر هستند کار میکند. عملکرد Naive Bayes به این صورت است که احتمال یک نقطه داده متعلق به یک کلاس خاص را محاسبه و بر اساس احتمال هر یک از ویژگیهای نقطه داده متعلق به آن کلاس کار میکند. برای درک این موضوع مبحث را با یک مثال پیش میبریم.
تصور کنید یک کیسه میوه دارید و میخواهید بدانید که آیا این کیسه حاوی سیب است یا پرتقال. میتوانید از الگوریتم Naive Bayes برای پیشبینی این موضوع با محاسبه احتمال هر یک از ویژگیهای میوه (بهعنوان مثال، رنگ، شکل، اندازه) متعلق به هر کلاس (سیب یا پرتقال) استفاده کنید. برای مثال، میدانید که سیبها بیشتر گرد هستند و رنگ قرمز دارند، در حالیکه پرتقالها به احتمال زیاد نارنجیرنگ و بیضیشکل هستند. میتوانید از این اطلاعات برای محاسبه احتمال سیب یا پرتقال بودن میوه موجود در کیسه خود استفاده کنید. بیز ساده به تمام ویژگیها بهصورت مستقل نگاه میکند؛ اما در نهایت آنها را بهمنظور کشف گروهی که متغیر به آن تعلق دارد، با یکدیگر ترکیب میکند.
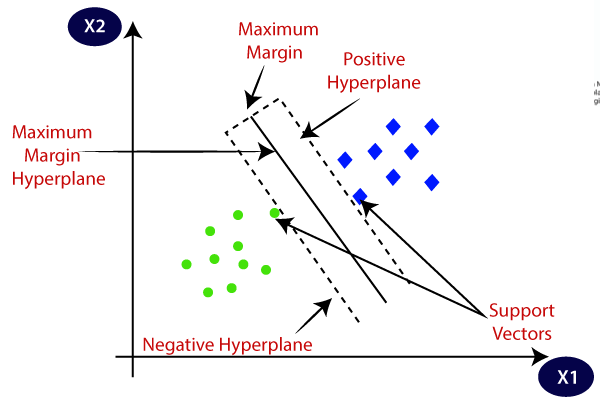
8.SVM (Support Vector Machine)
الگوریتم ماشین بردار پشتیبان یکی از الگوریتمهای مفید برای دستهبندی و پیشبینی وظایف است؛ حتی زمانی که با حجم کمی از دادهها روبهرو هستیم. SVMها یک Hyperplane پیدا میکنند که نقاط داده را در یک مجموعه به دو قسمت تقسیم میکند. هدف SVM ایجاد بهترین خط یا مرز تصمیم است که بتواند فضای n بعدی را به کلاسها تفکیک کند تا بتوانیم بهراحتی نقطه داده جدید را در دستهبندی صحیح قرار دهیم. این مرز بهترین تصمیم، ابرصفحه (Hyperplane) نامیده میشود. تصور کنید مجموعه دادهای از تصاویر گربهها و سگها داریم. ما ابتدا مدل خود را با مجموعه تصاویر این دو حیوان آموزش میدهیم تا بتواند با ویژگیهای مختلف گربهها و سگها آشنا شود. الگوریتم SVM خطی (هایپرپلن) را در مجموعه داده پیدا میکند که به واسطه آن تصاویر گربه از تصاویر سگ جدا میشوند. حال مدل با مشاهده تصاویر هر گروه تشخیص میدهد که عکس جدید گربه است یا سگ.
9.Apriori
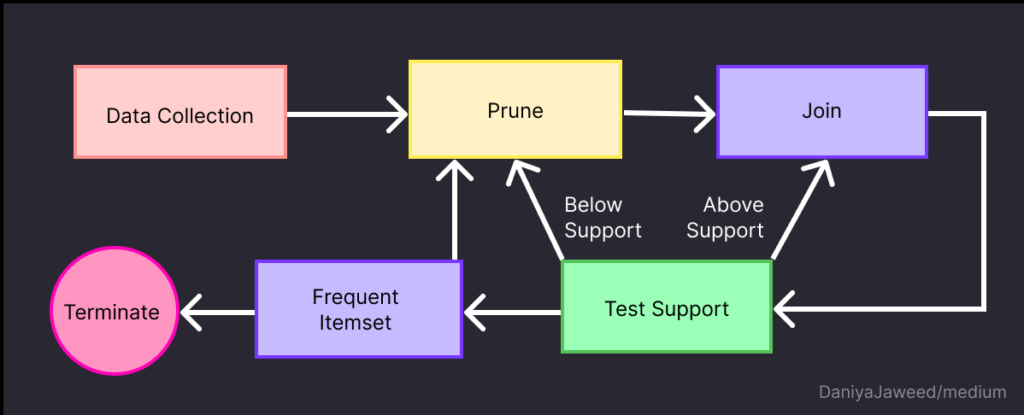
Apriori جزو الگوریتمهای Rule Based است و بهمنظور یافتن ویژگیهای آیتمهای مکرر در یک مجموعه داده بهکار میرود. این الگوریتم اغلب برای تحلیل سبد خرید مشتریان استفاده میشود؛ جایی که هدف یافتن ارتباط بین مواردی است که اغلب با هم خریداری میشوند. Apriori با ساخت مکرر مجموعه آیتمهای بزرگتر از مجموعه آیتمهای کوچکتر کار میکند. شروع کار پیشبینی الگوها با کوچکترین مجموعههای آیتمهای ممکن، که آیتمهای مفرد هستند، انجام میشود. سپس، الگوریتم مجموعه آیتمها را با یکدیگر ترکیب میکند تا مجموعه بزرگتری را تشکیل دهد. این روند تا زمانی ادامه مییابد که به آستانه اندازه معینی برسد یا دیگر نتواند مجموعه آیتمهای مکرری را پیدا کند.
تصور کنید یک مجموعه داده تراکنش از یک فروشگاه مواد غذایی دارید. هر تراکنش اقلامی دارد که مشتری خریداری کرده است. مرحله اول این الگوریتم Data Collection است که در آن الگوریتم دادهها را جمعآوری میکند. حال اولین مرحله جمعآوری اقلام خریداریشده از فروشگاه است و نتیجه زیر بهدست میآید:
- خرید اول: گوجه، کلم بروکلی، گوشت
- خرید دوم: گوجه، نان
- خرید سوم: پرتقال، بروکلی، نان، گوشت
- خرید چهارم: گوجه، نان
- خرید پنجم: پرتقال، بروکلی، نان
در ادامه الگوریتم Apriori تعداد هر آیتم را میشمارد و نتیجه زیر بدست میآید:
- گوجه: 3
- بروکلی: 3
- گوشت: 2
- نان: 4
- پرتقال: 2
در قدم دوم باید حداقل آستانه پشتیبانی (Minimum Support Threshold) را برای شناسایی مجموعه اقلام مکرر تنظیم کنیم. فرض کنید آستانه ما 3 باشد. این بدان معناست که یک مجموعه آیتم باید حداقل در سه تراکنش ظاهر شود تا آن را مکرر بنامیم. آیتمهایی که کمتر از سه بار در هر خرید تکرار شدهاند به اصطلاح Prune یا حذف و آیتمهای مکرر با یکدیگر ادغام میشوند (Join). در مرحله سوم، الگوریتم اقلام مکرر (که حداقل 3 بار تکرار شدهاند) را محاسبه میکند و نتیجه زیر را نشان میدهد:
- {گوجه}: 3 (مکرر)
- {بروکلی}: 3 (مکرر)
- {گوشت}: 2 (غیر مکرر)
- {نان}: 4 (مکرر)
- {پرتقال}: 2 (غیر مکرر)
در مرحله چهارم الگوریتم جفت آیتمهای مکرر با طول 2 را با استفاده از مجموعه آیتمهای مکرر مرحله قبل محاسبه میکند و نتیجه زیر بهدست میآید. این مرحله Test Support نام دارد.
- {گوجه، بروکلی}: 2 (غیر مکرر)
- {گوجه، گوشت}: 1 (غیر مکرر)
- {گوجه، نان}: 3 (مکرر)
- {گوجه، پرتقال}: 1 (غیر مکرر)
- {بروکلی، گوشت}: 1 (غیر مکرر)
- {بروکلی، نان}: 2 (غیر مکرر)
- {بروکلی، پرتقال}: 1 (غیر مکرر)
- {گوشت، نان}: 1 (غیر مکرر)
- {گوشت، پرتقال}: 1 (غیر مکرر)
- {نان، پرتقال}: 2 (غیر مکرر)
در مرحله پنجم فرآیند را تکرار میکنیم؛ اما این بار با مجموعه آیتمهایی به طول 3، 4 و غیره؛ تا زمانی که دیگر مجموعه آیتمهای مکرر پیدا نشود.
در این مثال به طول 2 اکتفا میکنیم. این مرحله پنجم یا Frequent Itemset است. با توجه به این موضوع، مجموعه آیتمهای مکرر شامل موارد زیر هستند:
- گوجه
- بروکلی
- نان
این مجموعه اقلامی را نشان میدهد که اغلب با هم خریداری میشوند. در نهایت الگوریتم به مرحله Terminate میرسد؛ مرحلهای که در آن دیگر نباید مجموعه آیتمهای جدیدی تولید شود. با این اطلاعات، فروشگاه مواد غذایی میتواند تصمیمات استراتژیک مانند قرار دادن سیب، کلم بروکلی و نان در نزدیکی یکدیگر برای تشویق فروش بیشتر بگیرد.
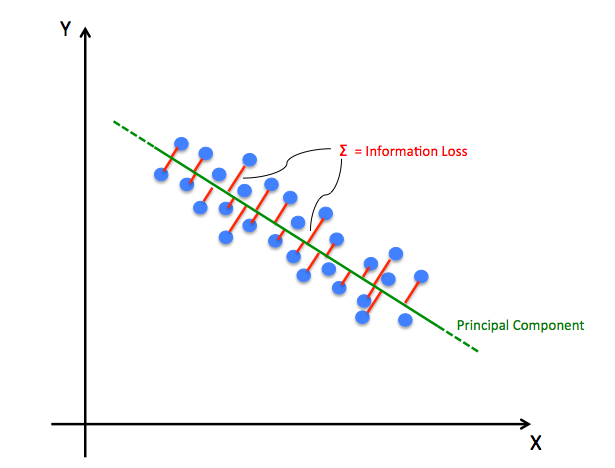
10.PCA (Principal Component Analysis)
الگوریتم یادگیری ماشین PCA بهمنظور کاهش ابعاد یک مجموعه و سادگی پردازش اطلاعات استفاده میشود. کاهش ابعاد، فرآیند کاهش تعداد ویژگیهای یک مجموعه داده بدون از دست دادن اطلاعات زیاد است. این الگوریتم اجزای اصلی یک مجموعه داده را نگه میدارد و ویژگیهای جدیدی که با این مجموعه همبستگی ندارند را حذف میکند. این حذف بهگونهای انجام میشود که تا آنجا که ممکن است واریانس دادهها حفظ شوند. بهعنوان مثال، الگوریتم PCA ممکن است متوجه شود که قد و وزن حیوانات با هم ارتباط زیادی دارند. این بدان معناست که ما میتوانیم از یک ویژگی واحد مانند قد برای نشان دادن قد و وزن استفاده کنیم.
آنچه در الگوریتم های یادگیری ماشین خواندیم
با افزایش روزافزون حجم دادهها، استفاده از سریعترین الگوریتم های ماشین لرنینگ ضروری بهنظر میرسد. الگوریتم های یادگیری ماشین برای دستهبندی، پیشبینی و محاسبات استفاده میشوند. هر یک از آنها در موارد خاصی بهکار میروند و بازدهی بیشتری دارند. این الگوریتمها امکان یافتن اطلاعات ضروری در میان انبوهی از دادهها را فراهم میآورند؛ کاری که بهصورت دستی امکانپذیر نیست.
سوالات متداول
سرعت کدام الگوریتم بیشتر است؟
سرعت الگوریتمهای جنگل تصادفی و درخت تصمیم در پردازش اطلاعات طولانی بیشتر است؛ در حالیکه الگوریتم Naive Bayes از نظر زمان اجرا سرعت بیشتری دارند.
کدام یک برای شروع یادگیری سادهتر است؟
انتخاب سادهترین الگوریتم برای شروع یادگیری بستگی به ترجیحات فردی دارد؛ اما الگوریتمهای رگرسیون خطی، رگرسیون لجستیک و KNN برای شروع یادگیری سادهتر هستند.
بهترین الگوریتم یادگیری ماشین برای پیشبینی کدام است؟
انتخاب بهترین الگوریتم پیشبینی به عواملی همچون ماهیت مشکل، نوع دادهها و الزامات منحصربهفرد بستگی دارد. الگوریتمهای SVM و جنگل تصادفی برای پیشبینی محبوبتر هستند.