آشنایی با Overfitting (بیشبرازش) و Underfitting (کمبرازش) در یادگیری ماشین
پس از اتمام دوره یادگیری ماشین، نوبت به پیادهسازی دستورات و مفاهیمی که فرا گرفتهاید میرسد. در این هنگام با دو مفهوم Overfitting و Underfitting در یادگیری ماشین روبهرو میشوید. Overfitting و Underfitting دو مشکل اصلی در یادگیری ماشین هستند که عملکرد مدلها را کاهش میدهند. هدف اصلی هر مدل Machine Learning تعمیم صحیح مجموعه دادهها است. تعمیم به معنای توانایی یک مدل ML برای ارائه خروجی مناسب است؛ به گونهای که مجموعه دادهشده از ورودیهای ناشناخته بیشترین تطبیق را با مجموعه صحیح داشته باشند. به عبارتی دیگر، پس از ارائه آموزش به ماشین در مورد مجموعه داده، ماشین میتواند خروجی قابل اعتماد و دقیقی تولید کند. از این رو، Underfitting و Overfitting دو عبارتی هستند که باید برای عملکرد مدل و تعمیم صحیح بررسی شوند. در ادامه این مقاله از کوئرا بلاگ، دو مفهوم Overfit در یادگیری ماشین و Underfit در یادگیری ماشین را بررسی خواهیم کرد.
پیش از آنکه به سراغ تشریح این دو مفهوم برویم، باید چند اصطلاح را توصیف کنیم.
سیگنال: به الگوی واقعی دادهها اشاره دارد که به مدل یادگیری ماشین کمک میکند تا از دادهها یاد بگیرد.
نویز: دادههای غیرضروری و نامربوط است که عملکرد مدل را کاهش میدهد.
بایاس: بایاس یک خطای پیشبینی است که بهدلیل سادهسازی بیش از حد الگوریتمهای یادگیری ماشین در مدل معرفی میشود. همچنین بایاس به تفاوت میان مقادیر پیشبینی شده و مقادیر واقعی اشاره دارد.
واریانس: اگر مدل یادگیری ماشین با مجموعه داده آموزشی خوب عمل کند، اما با مجموعه داده آزمایشی عملکرد خوبی نداشته باشد، واریانس رخ میدهد.
بیشتر بخوانید: یادگیری ماشین چیست؟ همه چیز درباره Machine Learning
Overfitting در یادگیری ماشین
مفهوم Overfit در یادگیری ماشین در زبان فارسی با نام بیشبرازش خوانده میشود و زمانی اتفاق میافتد که مدل ما سعی میکند تمام نقاط داده یا بیشتر از نقاط داده مورد نیاز موجود در مجموعه داده را پوشش دهد. به همین دلیل، مدل شروع به ذخیره نویز و مقادیر نادرست موجود در مجموعه داده میکند و همه این عوامل کارایی و دقت آن را کاهش میدهند. مدل بیشبرازش دارای بایاس کم و واریانس بالا است.
احتمال بروز بیشبرازش به اندازهای که ما به مدل خود آموزش میدهیم افزایش مییابد. این بدان معناست که هر چه بیشتر مدل خود را آموزش دهیم، شانس بیشتری برای رخ دادن بیشبرازش بهوجود میآید. Overfitting یکی از مشکلات اصلی در یادگیری تحت نظارت است.
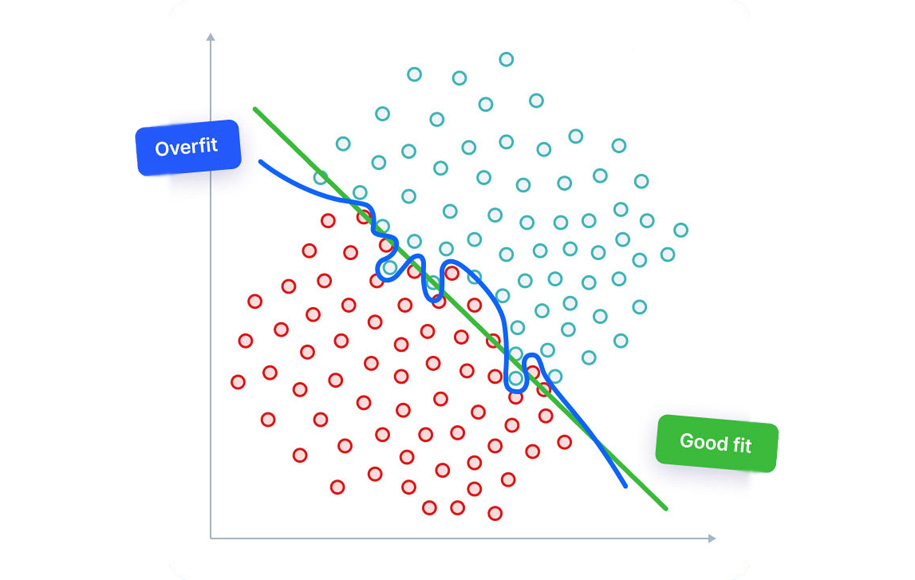
مفهوم بیشبرازش را میتوان با نمودار زیر که یک خروجی رگرسیون خطی است، درک کرد.
همانطور که از نمودار بالا مشخص است، مدل سعی میکند تمام نقاط داده موجود در نمودار پراکندگی را پوشش دهد. این شیوه ممکن است کارآمد به نظر برسد، اما در واقعیت اینطور نیست. از آنجاییکه هدف مدل رگرسیون یافتن بهترین خط برازش است، از این رو تلاش دارد بهترین تناسب را ایجاد کند؛ اما در اینجا ما بهترین تناسب را نداریم. بنابراین خطاهای پیشبینی ایجاد میشود.
دلایل ایجاد Overfitting
برخی از عوامل منجر به بروز بیشبرازش میشوند که در صورت وقوع، عملکرد مدل را با اختلال مواجه میکنند. در ادامه به دلایل ایجاد Overfitting اشاره خواهیم کرد.
- دادههای مورد استفاده برای آموزش پاک نمیشوند و حاوی نویز بالایی هستند.
- مدل دارای واریانس بالایی است.
- اندازه مجموعه داده آموزشی مورد استفاده کافی نیست.
- مدل خیلی پیچیده است.
جلوگیری از Overfitting
در پاسخ به پرسش «چگونه از وقوع بیشبرازش در مدل جلوگیری کنیم؟» باید بگوییم که اعمال برخی پارامترها روی مدل یا دادهها میتوانند از وقوع این اتفاق جلوگیری کنند که در ادامه هشت روش برای جلوگیری از Overfitting را تشریح خواهیم کرد.
1.گروهبندی (داده)
بهجای استفاده از تمام دادههایمان برای آموزش، میتوانیم بهسادگی مجموعه دادههای خود را به دو مجموعه تقسیم کنیم: آموزش و آزمایش. یک نسبت منطقی، تقسیم معمول 80 درصد برای آموزش و 20 درصد برای آزمایش است. ما مدل خود را تا زمانی آموزش میدهیم که نه تنها در مجموعه آموزشی، بلکه برای مجموعه تست نیز عملکرد خوبی داشته باشد. این موضوع نشاندهنده قابلیت تعمیم خوب است؛ زیرا مجموعه آزمایشی، دادههای دیده نشده را نشان میدهد که برای آموزش استفاده نشدهاند. با این حال، این رویکرد به یک مجموعه داده نسبتا بزرگ برای آموزش، حتی پس از تقسیم نیاز دارد.
بیشتر بخوانید: تاریخچه یادگیری ماشین
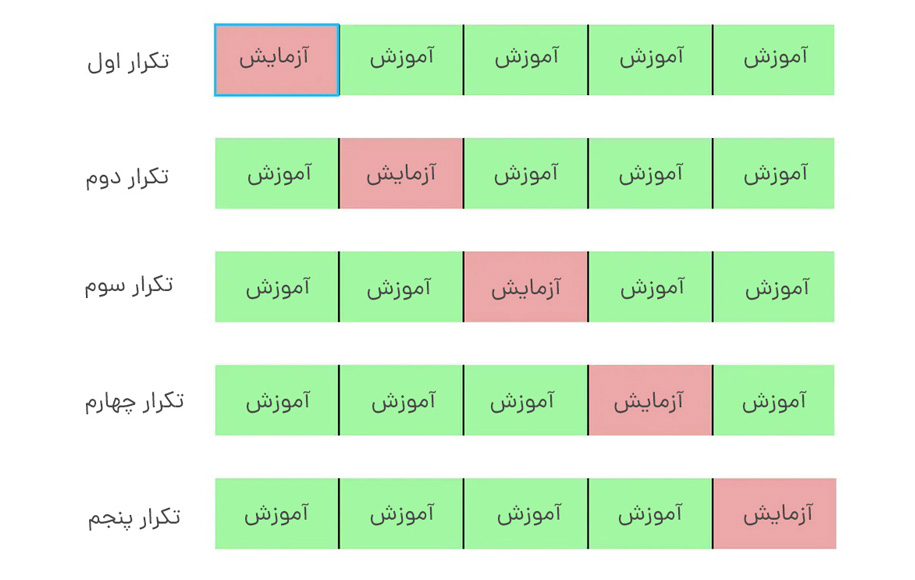
2.اعتبارسنجی متقابل (داده)
ما میتوانیم مجموعه دادههای خود را به k گروه تقسیم کنیم (اعتبارسنجی متقاطع k-fold). در این روش اجازه میدهیم یکی از گروهها مجموعه آزمایشی باشد و بقیه دادهها بهعنوان مجموعه آموزشی در مدل قرار بگیرند. این روند را تا زمانی که هر گروه جداگانه بهعنوان مجموعه تست استفاده شود، تکرار میشود. برخلاف گروهبندی دادهها، اعتبارسنجی متقابل اجازه میدهد تا در نهایت از تمام دادهها برای آموزش استفاده شود. اما از نظر محاسباتی گرانتر از گروهبندی خواهد بود.
3.افزایش دادهها (داده)
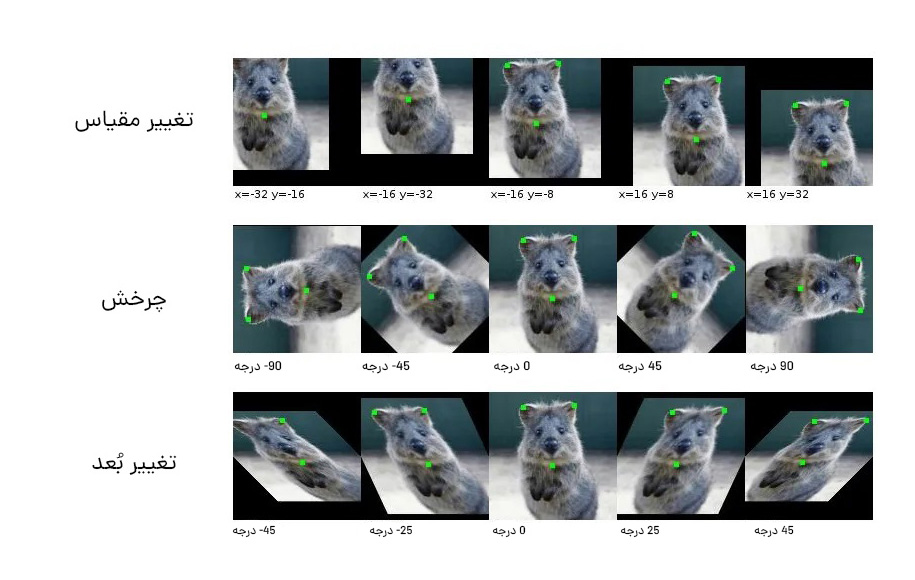
یک مجموعه داده بزرگتر باعث کاهش بیشبرازش میشود. اگر نمیتوانیم دادههای بیشتری جمعآوری کنیم و محدود به دادههایی هستیم که در مجموعه داده فعلی خود داریم، میتوانیم افزایش دادهها را برای افزایش مصنوعی اندازه مجموعه دادهمان اعمال کنیم. بهعنوان مثال، اگر در حال آموزش برای یک کار طبقهبندی تصویر هستیم، میتوانیم تغییر شکلهای تصاویر مختلف را در مجموعه دادههای تصویر خود انجام دهیم (بهعنوان مثال، چرخش، تغییر مقیاس، تغییر جهت).
4.انتخاب ویژگی (داده)
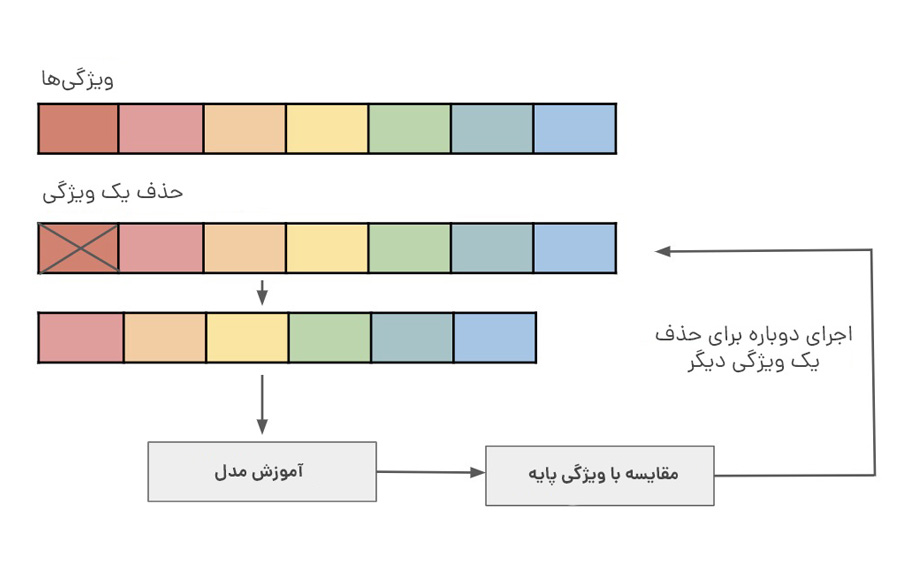
اگر فقط تعداد محدودی از نمونههای آموزشی داریم که هر کدام دارای تعداد زیادی ویژگی هستند، باید فقط مهمترین ویژگیها را برای آموزش انتخاب کنیم تا مدل ما نیازی به یادگیری برای این همه ویژگی نداشته باشد و در نهایت از وقوع بیشبرازش جلوگیری کنیم. ما میتوانیم بهسادگی ویژگیهای مختلف را آزمایش کنیم، مدلهای انفرادی را برای این ویژگیها آموزش دهیم و قابلیتهای تعمیم را ارزیابی کنیم. همچنین استفاده از یک روش انتخاب ویژگی بهمنظور جلوگیری از بیشبرازش مفید است.
5.منظمسازی L1 /L2 (الگوریتم یادگیری)
در منظمسازی L1 یا L2، میتوانیم یک عبارت جریمه بر تابع هزینه اضافه کنیم تا ضرایب تخمینی را به صفر برسانیم (و مقادیر شدیدتر را دریافت نکنیم). منظمسازی L2 به وزنها اجازه میدهد تا به سمت صفر کاهش یابند، اما صفر نشوند؛ در حالیکه تنظیم L1 به وزنها اجازه میدهد تا به صفر برسند.
| منظمسازی L1 | منظمسازی L2 |
| مجموع مقادیر مطلق وزنها را جریمه میکند. | مجموع مقادیر مربع وزنها را جریمه میکند. |
| مدلی را تولید میکند که ساده و قابل تفسیر است. | قادر به یادگیری الگوهای پیچیده دادهها است. |
| نسبت به موارد نامرتبط مقاوم است. | نسبت به موارد نامرتبط مقاوم نیست. |
6.حذف لایهها/ تعداد واحد در هر لایه (مدل)
همانطور که در منظمسازی L1 و L2 ذکر شد، یک مدل بسیار پیچیده ممکن است بیش از حد مناسب باشد. بنابراین، ما میتوانیم بهطور مستقیم پیچیدگی مدل را با حذف لایهها کاهش دهیم و از اندازه مدلمان بکاهیم؛ اما میتوانیم پیچیدگی را با کاهش تعداد نورونها در لایههای کاملا متصل کاهش دهیم. باید مدلی با پیچیدگی کافی داشته باشیم تا تناسب بین بیشبرازش و کمبرازش را رعایت کنیم.
7.توقف (مدل)
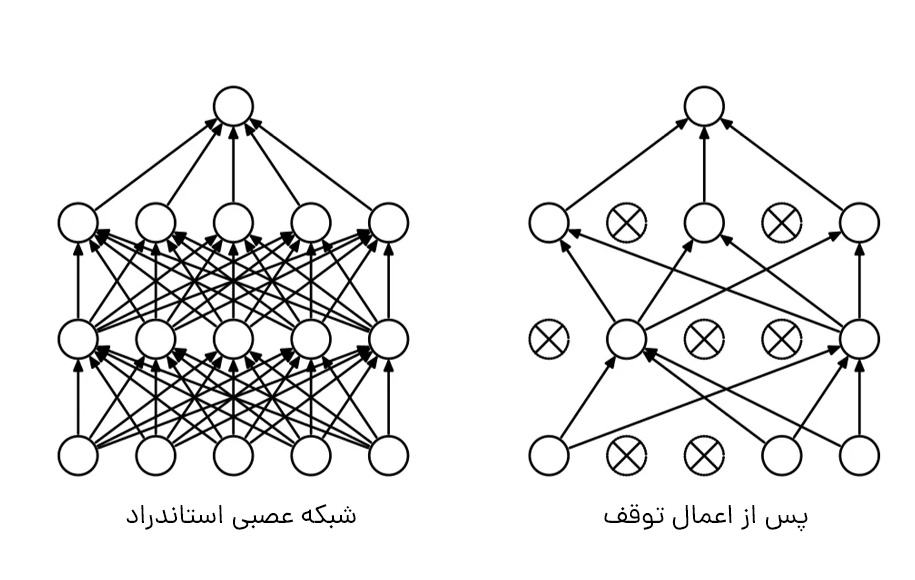
با اعمال توقف، که نوعی منظمسازی است، در لایههای خود، زیر مجموعهای از واحدهای شبکهمان را با احتمال مجموعه نادیده میگیریم. با استفاده از این روش، میتوانیم یادگیری وابسته به یکدیگر را در بین واحدها کاهش دهیم؛ زیرا این وابستگی ممکن است به بیشبرازش منجر شده باشد. با این حال، با اعمال توقف، به دورههای بیشتری برای همگرایی مدل خود نیاز خواهیم داشت.
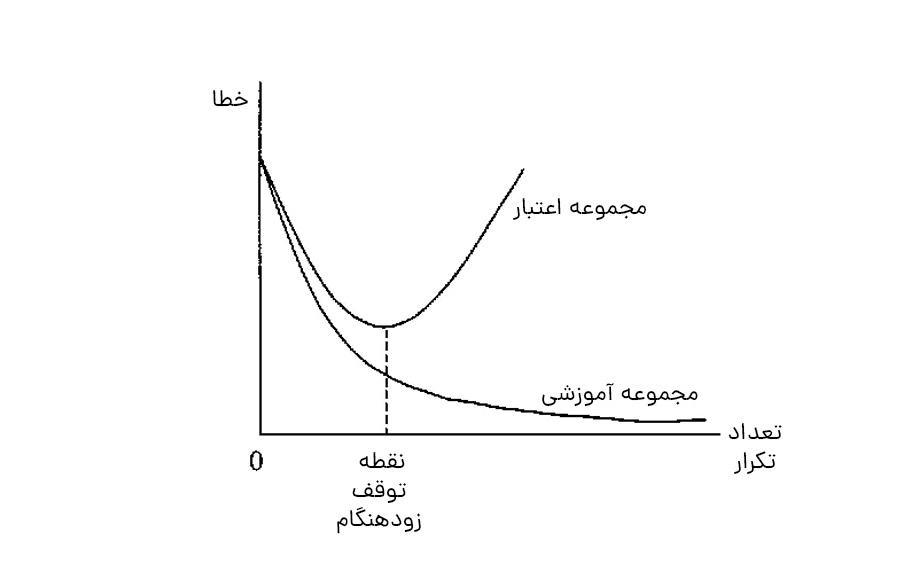
8.توقف زودهنگام (مدل)
ابتدا میتوانیم مدل خود را برای تعداد زیادی از دادهها آموزش دهیم و نمودار تلفات اعتبارسنجی را رسم کنیم (بهعنوان مثال، با استفاده از گروهبندی). هنگامی که از دست دادن اعتبار شروع به کاهش میکند، آموزش را متوقف و مدل فعلی را ذخیره میکنیم. میتوانیم این کار را با نظارت بر نمودار ضرر یا تنظیم یک نقطه توقف اولیه اجرا کنیم. مدل ذخیرهشده، مدل بهینه برای تعمیم بین مقادیر مختلف دادههای آموزشی خواهد بود.
Underfitting در یادگیری ماشین
Underfitting که در زبان فارسی با نام کمبرازش یا عدم تناسب هم شناخته میشود زمانی اتفاق میافتد که مدل یادگیری ماشین ما نتواند روند اساسی دادهها را ثبت کند. برای جلوگیری از بیشبرازش در مدل، ارائه دادههای آموزشی را میتوان در مراحل اولیه متوقف کرد. به همین دلیل ممکن است مدل به اندازه کافی از دادههای آموزشی یاد نگیرد. در نتیجه، احتمالا مدل نتواند بهترین تناسب روند غالب را در دادهها پیدا کند.
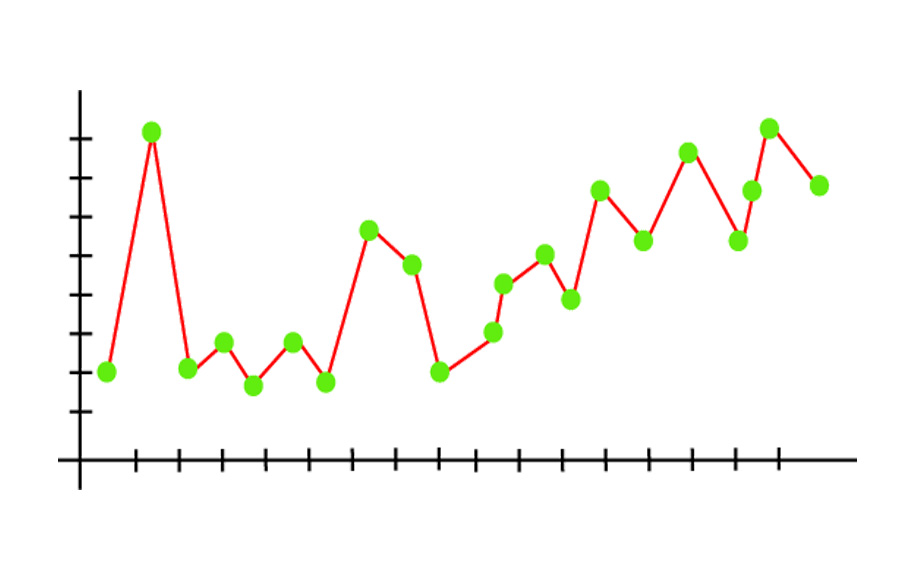
در Underfitting، مدل قادر به یادگیری کافی از دادههای آموزشی نیست و از این رو پیشبینیهای غیرقابل اعتمادی تولید میکند و دقت کاهش مییابد. یک مدل کمبرازش دارای بایاس بالا و واریانس کم است. مثال کمبرازش با استفاده از خروجی یک مدل رگرسیون خطی است، در ادامه میآید.
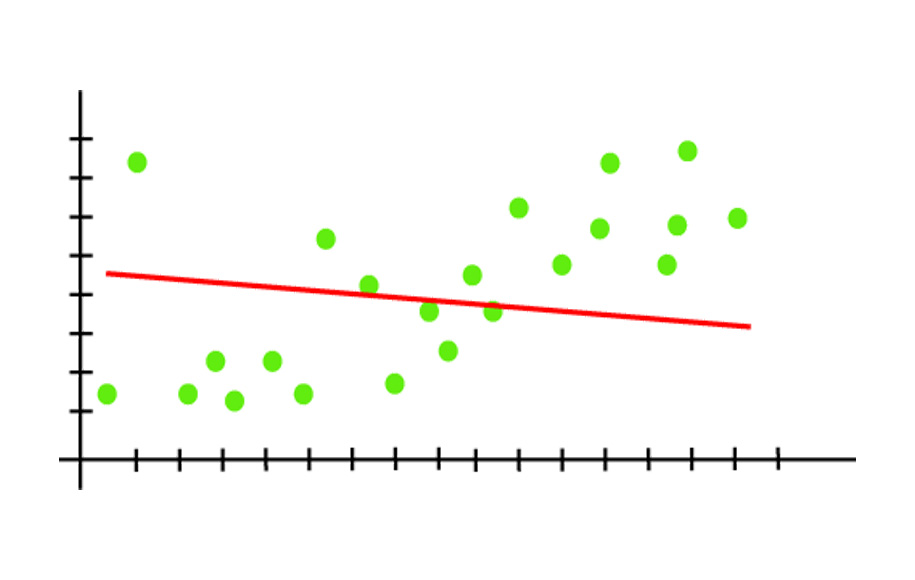
همانطور که در نمودار بالا میبینیم، مدل قادر به گرفتن نقاط داده موجود در نمودار نیست.
جلوگیری از Underfitting
از آنجایی که میتوانیم کمبرازش را بر اساس مجموعه آموزشی تشخیص دهیم، بهتر میتوانیم در ایجاد رابطه غالب بین متغیرهای ورودی و خروجی عمل کنیم. با حفظ پیچیدگی کافی مدل، میتوانیم از کمبرازش جلوگیری کنیم و پیشبینیهای دقیقتری انجام دهیم. در ادامه سه تکنیک را نام میبریم که میتوانیم از آنها برای کاهش کمبرازش استفاده کنیم.
1.کاهش منظمسازی
منظمسازی معمولا برای کاهش واریانس یک مدل با اعمال جریمه به پارامترهای ورودی با ضرایب بزرگتر استفاده میشود. روشهای مختلفی مانند منظمسازی L1، تنظیم کمند، انصراف و غیره وجود دارد که به کاهش نویز و نقاط پرت در یک مدل کمک میکند. با این حال، اگر ویژگیهای داده بیش از حد یکنواخت شوند، مدل قادر به شناسایی روند غالب نیست، که منجر به عدم تناسب یا Underfitting خواهد شد. با کاهش میزان منظمسازی، پیچیدگی و تنوع بیشتری به مدل وارد میشود که امکان آموزش موفق آن را فراهم میکند.
2.افزایش مدت زمان آموزش مدل
همانطور که قبلا ذکر شد، توقف زودهنگام تمرین مدل میتواند منجر به Underfitting شود. بنابراین با افزایش مدت زمان تمرین میتوان از وقوع آن جلوگیری کرد. با این حال، مهم است که با افزایش زمان تمرین، مدل را دچار Overfitting نکنیم. یافتن تعادل بین دو سناریو نکته مهم در آموزش مدل خواهد بود.
3.انتخاب ویژگی
در هر مدلی، از ویژگیهای خاص برای تعیین یک نتیجه معین استفاده میشود. اگر ویژگیهای پیشبینی کافی وجود نداشته باشد، باید ویژگیهایی با اهمیت بیشتر به مدل معرفی شوند. بهعنوان مثال، در یک شبکه عصبی ممکن است نورونهای پنهان بیشتری اضافه کنید و بهطور مشابهی به یک الگوریتم جنگل تصادفی، درختان بیشتری بیفزایید. این فرآیند پیچیدگی مضاعفی را به مدل تزریق میکند و نتایج آموزشی بهتری را بههمراه دارد.
چگونه تعادل و تناسب را در آموزش مدل برقرار کنیم؟
اصطلاح «تناسب کافی» از علم آمار و هدف مدلهای یادگیری ماشین برای دستیابی به تناسب خوب گرفته شده است. مدلسازی آمار مشخص میکند که نتایج یا مقادیر پیشبینیشده چقدر با مقادیر واقعی مجموعه داده مطابقت دارند.
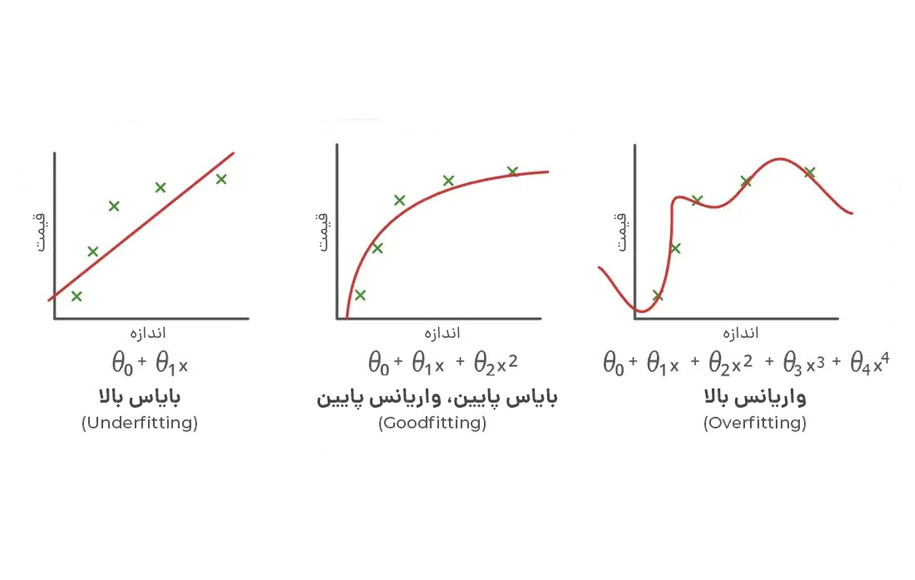
مدل با تناسب خوب بین مدل کمبرازش و بیشبرازش قرار میگیرد و در حالت ایدهآل با 0 خطا پیشبینی میکند؛ اما در عمل رسیدن به آن مشکل است.
همانطور که وقتی مدل خود را برای مدتی آموزش میدهیم، خطاهای دادههای آموزشی کاهش مییابد، همین امر در مورد دادههای آزمایشی نیز اتفاق میافتد. اما اگر مدل را برای مدت طولانی آموزش دهیم، ممکن است عملکرد آن به دلیل برازش بیش از حد کاهش یابد؛ زیرا نویز و اطلاعات غیرضروری موجود در مجموعه داده را یاد میگیرد.
بنابراین هر نقطه داده، درست قبل از افزایش خطاها، نقطه خوبی است و ما میتوانیم برای دستیابی به یک مدل خوب در همین محل توقف کنیم. تصاویر زیر تناسب خوب را نشان میدهند که برای ایجاد توازن در یادگیری بهکار میروند.
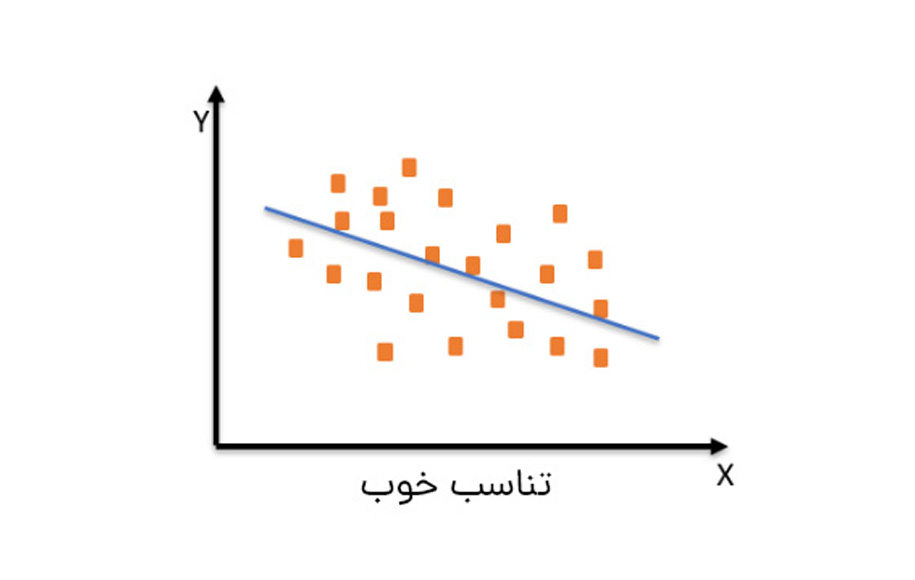
دو روش دیگر وجود دارد که از طریق آنها میتوانیم امتیاز خوبی برای مدل خود به دست آوریم. این دو روش، نمونهگیری مجدد برای تخمین دقت مدل و مجموعه داده اعتبارسنجی است.
Underfitting در مقابل Overfitting
به زبان ساده، Overfitting یا بیشبرازش در مقابل Underfitting یا کمبرازش است و زمانی که مدل بیش از حد آموزش دیده باشد یا زمانی که دارای پیچیدگی بسیار زیادی است، رخ میدهد. بیشبرازش منجر به نرخ خطای بالایی در دادههای آزمایشی میشود. بهطور معمول Overfitting یک مدل رایجتر از Underfitting است و Underfitting معمولا در تلاش برای جلوگیری از Overfitting از طریق فرآیندی به نام «توقف اولیه» اتفاق میافتد.
اگر کمآموزی یا عدم پیچیدگی منجر به عدم تناسب شود، یک استراتژی پیشگیری منطقی، افزایش مدت زمان آموزش یا افزودن ورودیهای مرتبط بیشتر خواهد بود. با این حال، اگر مدل را بیش از حد آموزش دهید یا ویژگیهای زیادی به آن بیفزایید، ممکن است مدل خود را دچار Overfitting کنید که منجر به بایاس کم اما واریانس بالا (یعنی مبادله بایاس- واریانس) میشود. در این سناریو، مدل آماری بسیار نزدیک به دادههای آموزشی خود بوده و با آنها تطابق دارد و باعث میشود دادهها به خوبی به نقاط داده جدید تعمیم داده نشوند. توجه به این نکته مهم است که برخی از انواع الگوریتمهای یادگیری ماشین، مانند Decision Tree یا KNN، میتوانند بیش از بقیه مستعد Overfitting شوند.
شناسایی بیشبرازش میتواند دشوارتر از کمبرازش باشد؛ زیرا بر خلاف کمبرازش، دادههای آموزشی با دقت بالایی در یک مدل بیشبرازش اجرا میشوند. برای ارزیابی دقت یک الگوریتم، معمولا از تکنیکی به نام اعتبارسنجی متقاطع k-folds استفاده میشود.
در اعتبارسنجی متقاطع k-folds، دادهها به زیر مجموعههای k با اندازه مساوی تقسیم میشوند که به آنها “folds” یا «چین» میگویند. یکی از k-foldها بهعنوان مجموعه آزمایشی عمل میکند که بهعنوان مجموعه نگهدارنده یا مجموعه اعتبارسنجی نیز شناخته میشود و چینهای باقیمانده مدل را آموزش میدهند. این روند تا زمانی تکرار میشود که هر یک از چینها بهعنوان یک چین نگهدارنده عمل کنند. پس از هر ارزیابی، یک امتیاز به چین اختصاص داده و حفظ میشود. هنگامی که تمام تکرارها به پایان رسید، از امتیازها برای ارزیابی عملکرد مدل کلی میانگین گرفته میشود.
سناریو ایدهآل هنگام آموزش یک مدل، یافتن تعادل بین بیشبرازش و کمبرازش است. شناسایی «تناسب خوب» بین این دو به مدلهای یادگیری ماشینی اجازه میدهد تا پیشبینیها را با دقت انجام دهند.
آنچه در مفاهیم بیشبرازش (Overfitting) و کمبرازش (Underfitting) خواندیم
Overfitting و Underfitting دو مفهوم حیاتی هستند که با مبادلات بایاس- واریانس در یادگیری ماشین مرتبط هستند. Overfitting به عملکرد خوب در دادههای آموزشی و تعمیم ضعیف به دادههای دیگر اشاره دارد؛ در حالیکه Underfitting به عملکرد ضعیف در دادههای آموزشی و تعمیم ضعیف به دادههای دیگر اشاره میکند. هر دو منجر به اختلال در عملکرد مدل یادگیری ماشین میشوند؛ اما با انجام برخی اقدامات میتوان از بروز این مشکلات جلوگیری کرد.