دیتا ساینس (Data Science) چیست؟ همهچیز دربارهی علم داده

با ورود جهان به عصر کلانداده، نیاز به ذخیرهسازی داده نیز افزایش یافته. برای سالیان سال، چالش و دغدغه اصلی سازمانها ایجاد راهکارهایی نوین و پربازده برای ذخیرهسازی داده بود. اما اکنون که فریم ورک ها مشکل ذخیرهسازی را بهخوبی حل کردهاند، تمرکز بر روی پردازش دادهها معطوف شده و دیتا ساینس یا علم داده (Data Science) هم کلید پردازش کلاندادهها است. با این اوصاف، بسیار مهم است که بدانیم دیتا ساینس چیست و چگونه میتواند به سازمانها کمک کند استراتژیهای هوشمندانهتر در پیش بگیرند. با کوئرا بلاگ همراه باشید تا به شکلی مفصل بگوییم دیتا ساینس چیست و چه نقشی در استخراج اطلاعات معنادار از مجموعه دادههای بزرگ و پیچیده ایفا میکند.
دیتا ساینس چیست ؟
دیتا ساینس یا علم داده به معنی پژوهشی است که با هدف استخراج اطلاعات کاربردی برای کسبوکارها انجام میشود. این علم، بسیاری از علوم دیگر مانند ریاضی، آمار، هوش مصنوعی و مهندسی کامپیوتر را در بر میگیرد و با ادغام تمام آنها، پردازش و تحلیل دادههای کلان را امکانپذیر میکند. بنابراین دانشمندان داده (Data Scientists) نهتنها میتوانند دلایل وقوع اتفاقهای مختلف و نحوه وقوع را تشخیص دهند، بلکه قادر به پیشبینی آنچه قرار است اتفاق بیفتد نیز خواهند بود.

انواع دیتا ساینس چیست و چه اهمیتی دارند؟
از دیتا ساینس برای پژوهش داده به چهار روش اصلی استفاده میشود که هر یک انبوهی کاربرد و مزایا به همراه میآورند.
- تحلیل توصیفی (Descriptive Analysis): در تحلیل توصیفی، دادهها بررسی میشوند تا وقایعی که پیشتر روی داده تاثیر گذاشتهاند و یا همین حالا روی آن اثر میگذارند، شناسایی شوند. برجستهترین مشخصه این رویکرد، استفاده از انواع ابزارهای مصورسازی داده مانند نمودار دایرهای، میلهای، خطی و همینطور جداول است. برای مثال شرکتی که در زمینه رزرو پروازهای هوایی فعالیت دارد، هر روز انبوهی اطلاعات راجع به بلیتها ثبت و ذخیره میکند. با تحلیل توصیفی میتوان رشدها و سقوطهای ناگهانی فروش بلیت را شناسایی کرد و پربازدهترین ماههای سال را شناخت.
- تحلیل تشخیصی (Diagnostic Analysis): در این نوع از تحلیل، به بررسی عمیق دادههای دقیق میپردازیم تا متوجه شویم چرا اتفاقی بهخصوص رخ داده است. در این تحلیل از تکنیکهای مختلف مانند اکتشاف داده (Data Discovery)، استخراج داده (Data Mining) و تشخیص همبستگیها (Correlations) استفاده میشود. از سوی دیگر، داده ممکن است عملیاتها و فرایندهای دگرگونسازی مختلف را پشت سر بگذارد تا الگوهایی جدید در هر تکنیک یافت شود. برای مثال سرویس فروش بلیت مثال ما میتواند روی پربازدهترین ماهها عمیق شود و دلایل دقیق افزایش فروش را شناسایی کند. مثلا شاید در ماه مشخصی از سال، مردم به شهری بهخصوص میروند تا از نزدیک شاهد یک رویداد ورزشی باشند.
- تحلیل پیشگویانه (Predictive Analysis): در این تحلیل از داده تاریخی برای ارائه پیشبینیهای دقیق راجع به الگوهایی استفاده میشود که احتمالا در آینده تکرار میشوند. یادگیری ماشین (Machine Learning)، پیشبینی، تطبیق الگو و مدلهای پیشگویانه از برجستهترین اجزای این نوع تحلیل به حساب میآیند. در هر یک از این تکنیکها، کامپیوتر میآموزد که علیت روابط را مهندسی معکوس کند. شرکت مثال ما میتواند از علم داده برای پیشبینی الگوهای خرید بلیت در سال آینده کمک بگیرد. الگوریتم به دادههای پیشین نگاه و برای مثال پیشبینی میکند که فروش بلیت در ماه اردیبهشت برای فلان شهر افزایش مییابد. بنابراین میتوان تبلیغات هدفمند را از ماه فروردین آغاز کرد و به استقبال مشتریان رفت.
- تحلیل تجویزی (Prescriptive Analysis): این نوع تحلیل، تحلیل پیشگویانه را به سطح بعدی میبرد. بنابراین نهتنها وقایع احتمالی پیشبینی میشوند، بلکه پاسخ بهینه به هر خروجی هم ارائه خواهد شد. در واقع پیامدهای انتخابهای گوناگون بررسی و بهترین رویکرد ممکن ارائه میشود. در تحلیل تجویزی هم از تحلیل گراف، شبیهسازی، پردازش رخداد پیچیده، شبکههای عصبی (Neural Networks) و موتورهای پیشنهاددهی یادگیری ماشین استفاده میشود. در مثال شرکت فروشنده بلیت میتواند با بررسی دادههای کمپینهای تبلیغاتی قبلی، خروجیهای بالقوه کمپینهای آتی را در کانالهای ارتباطی مختلف بررسی کند. با این داده، کسبوکار تصمیماتی آگاهانهتر و موثرتر اتخاذ میکند.
اکنون که به سؤال اصلی این مقاله یعنی دیتا ساینس چیست پاسخ دادهایم، به سراغ دیگر ابعاد حوزه علم داده میرویم و سایر دانستنیها را با شما در میان میگذاریم.

دانشمند داده کیست و چه کاری انجام میدهد؟
دانشمندان داده (Data Scientists) کسانی هستند که با تخصص قوی خود در حوزههای مختلف، مسائل پیچیده مرتبط به داده را حل میکنند. آنها باید در چندین حوزه مرتبط با ریاضیات، آمار، علوم کامپیوتر و موارد مشابه سررشته داشته باشند تا بتوانند به درستی دادهها را تحلیل کنند (هرچند که ممکن است در همه این زمینهها متخصص نباشند). آنها از آخرین فناوریها برای یافتن راهکارهای بالقوه و رسیدن به نتایجی که برای رشد و توسعه یک سازمان حیاتی است، استفاده میکنند. دانشمندان داده، دادهها را به شکلی بسیار مفیدتر نسبت به دادههای خام دگرگون و ارائه میکنند.
ممکن است علاقهمند باشید: آیا «دانشمند داده» هنوز جذابترین شغل قرن بیستویک است؟
تفاوت هوش تجاری و دیتا ساینس چیست؟
در فضای کسبوکار، اغلب علم داده با هوش تجاری (Business Intelligence) اشتباه گرفته میشود. اما این دو چه تفاوتی با یکدیگر دارند؟ هوش تجاری و علم داده هر دو فرایندهایی متمرکز بر داده هستند و دادهها را با هدف اتخاذ تصمیمهای آگاهانه، به اطلاعات مفید تبدیل میکنند. با این حال، تفاوتهای ظریفی بین این دو رویکرد وجود دارد. بهطور کلی، هوش تجاری بر تجزیه و تحلیل رویدادهای گذشته تمرکز دارد، در حالی که هدف علم داده معمولا پیشبینی روندهای آینده است. جدول زیر مهمترین تفاوتها را تشریح میکند:
| هوش تجاری | علم داده | |
| هدف | بر شناسایی روندهای گذشته تمرکز دارد و به سوالاتی از این قبیل پاسخ می دهد: در دوره گذشته چه اتفاقاتی افتاده است؟ و یا چه روندهایی در حال توسعه است؟ | بر استخراج اطلاعات از مجموعهدادهها و ارائه پیشبینی براساس آنها تمرکز دارد. علم داده به سؤالهایی از این قبیل پاسخ میدهد: چه اتفاقی خواهد افتاد؟ یا محتملترین نتیجه کدام است؟ |
| مهارتهای مورد نیاز | نیازمند دانش بنیادین در زمینه آمار و مدیریت کسبوکار و همچنین مهارتهای تبدیل و مصورسازی دادهها | نیازمند مهارتهای فنی بیشتر مانند کدنویسی، دادهکاوی و همچنین دانش پیشرفتهتر از آمار و حوزه موردنظر |
| جمعآوری و مدیریت دادهها | برای مدیریت دادههایی که بهخوبی سازماندهی شدهاند استفاده میشود | برای مدیریت حجم زیادی از دادههای پویا و کمترساختاریافته استفاده میشود. |
| پیچیدگی | در مدیریت روزانه کسبوکارها کاربردیتر است و نیاز به هزینه و منابع کمتری دارد. | از نظر ظرفیت پیشبینی، توانایی مدیریت دادههای پویا و نیاز به مهارتهای پیشرفته، پیچیدهتر است. |
کاربرد دیتا ساینس برای کسبوکارها
با توجه به هرآنچه تا به اینجا کار خواندیم، بدیهی است که دیتا ساینس انقلابی در نحوه کارکرد کسبوکارها و سازمانها پدید آورده است. فارغ از اینکه ابعاد کسبوکار چقدر است، دیتا ساینس میتواند چنین مزایا مهمی به همراه آورد:
- شناسایی الگوهای ناشناخته: کسبوکارها به کمک علم داده قادر به شناسایی الگوها و ارتباطاتی هستند که میتوانند کارکرد سازمان را به کل دگرگون کنند. برای مثال ممکن است روشهایی برای کاهش هزینههای مدیریت منابع یافت شود که حاشیه سود را بالا میبرند. شرکتی که در حوزه بازرگانی الکترونیک فعالیت دارد میتواند با دیتا ساینس کشف کند که بخش اعظمی از کوئریهای کاربران در اوقات غیر کاری ثبت میشوند و اگر پاسخ کوئری طی روز کاری بعدی ارائه شود، مشتریان را از دست میدهد.
- بهبود محصولات و راهکارهای جدید: دیتا ساینس میتواند حفرهها و مشکلاتی که از چشم دور میمانند را نیز برملا کند. میتوان اطلاعات عمیقتر راجع به تصمیمگیری مشتریان، بازخوردهای مشتریان و فرایندهای کسبوکار به دست آورد و راهکارهای نوین ارائه کرد. برای مثال شرکتی که در زمینه پرداختهای آنلاین فعالیت دارد به کمک دیتا ساینس، نظرات مردم راجع به شرکت را از شبکههای اجتماعی گردآوری میکند. سپس تحلیلها نشان میدهند که مردم در اوقات اوج فروش، رمز عبور خود را فراموش میکنند و از سیستم بازیابی پسوورد کنونی نیز رضایت ندارند. با بازطراحی سیستم بازیابی رمز، فروش افزایش خواهد یافت.
- بهینهسازی در لحظه: واکنش نشان دادن سریع به تغییرات بازار برای هیچ کسبوکاری – بهخصوص سازمانهای بزرگ – آسان نیست. در عین حال اگر واکنش مناسب ارائه نشود باید منتظر ضرر مالی کلان و اختلال در فعالیتهای کسبوکار بود. دیتا ساینس میتواند به پیشبینی تغییرات و شناسایی بهترین واکنش به همین تغییرات کمک کند. برای مثال شرکتی که در حوزه خدمات پست با کامیون فعالیت دارد، از دیتا ساینس برای کاهش مدتزمان بیکاری در اوقات خرابی کامیونها کمک میگیرد. برای مثال مسیرهای جدید و الگوهای شیفتهای کاری شناسایی میشوند تا بازگشت کامیونها به کار با سرعت بیشتری پیش برود.
چرخهی عمر علم داده
اشتباه رایجی که در اغلب در پروژههای علم داده اتفاق میافتد، عجله در جمعآوری و تجزیهوتحلیل دادهها بدون درک پیشنیازها یا حتی چارچوببندی مناسب کسبوکار است. بنابراین، بسیار مهم است که تمام مراحل را در طول فرایند تحلیل دادهها دنبال کنیم تا از عملکرد روان پروژه مطمئن شویم. در ادامه مروری کوتاه بر مراحل اصلی «چرخه عمر علم داده» (Data Science Lifecycle) خواهیم داشت.
- تحقیق: بسیار مهم است که قبل از شروع پروژه، الزامات، نیازمندیها، اولویتها و بودجه موردنیاز را بررسی کنید. شما باید توانایی پرسیدن سؤالات درست نیز داشته باشید. در این مرحله باید بررسی کنید که آیا منابع موردنیاز از نظر نیروی انسانی، فناوری، زمان و داده را برای پشتیبانی از پروژه در اختیار دارید یا خیر. شما همچنین باید مشکل کسبوکار را چارچوببندی و فرضیههای اولیه را فرمولبندی کنید.
- آمادهسازی دادهها: در این مرحله به یک سندباکس تحلیلی (Analytical Sandbox) نیاز دارید که در آن بتوانید تجزیه و تحلیل دادهها را در تمام مراحل پروژه پیش ببرید. همچنین قبل از مدلسازی، باید دادهها را بررسی و پیشپردازش کنید. در این مرحله میتوانید از روشها و ابزارهای مختلف برای پاکسازی، تبدیل و مصورسازی دادهها کمک بگیرید. این کار به شما کمک میکند نقاط پرت را تشخیص دهید و بین متغیرها رابطه برقرار کنید.
- برنامهریزی مدل: هنگامی که دادهها را تمیز و آماده کردید، وقت آن است که با استفاده از فرمولهای آماری و ابزارهای مصورسازی مختلف، تحلیل اکتشافی انجام دهید. در این مرحله تعیین میکنید که از چه روشها و تکنیکهایی برای ترسیم روابط بین متغیرها استفاده خواهید کرد. این روابط پایه و اساسی برای پیادهسازی الگوریتمها در مرحله بعد خواهند بود. از ابزارهایی که از آنها برای برنامهریزی مدل استفاده میشود، میتوان به R ،SQL Analysis services و SAS/ACCESS اشاره کرد.
- مدلسازی: در این مرحله باید برای آموزش و تست مدل، مجموعهدادههایی را توسعه دهید. در این مرحله باید بررسی کنید که آیا ابزار شما برای اجرای مدلها کافی است یا به محیط قویتری برای پردازش سریع و موازی نیاز دارید. همچنین لازم است تکنیکهای مختلف مانند طبقهبندی (Classification)، پیوستگی (Association) و خوشهبندی (Clustering) را برای ساخت مدل بررسی کنید. از ابزارهایی مثل SAS Enterprise Miner ،WEKA ،SPCS Modeler ،Matlab ،Alpine Miner ،Statistica نیز میتوان برای ساخت مدل استفاده کرد.
- پیادهسازی: در این مرحله، گزارشهای نهایی، دستورالعملها، کدها و مستندات فنی را ارائه میکنید. علاوه بر این، یک پروژه آزمایشی را در «در لحظه» (Real-Time) به اجرا در میآورید. با این کار، قبل از تعهد کامل به پروژه، درک واضحی از عملکرد و سایر محدودیتهای آن در مقیاس کوچک پیدا خواهید کرد.
- ارائهی نتایج: اکنون باید ارزیابی کنید که آیا توانستهاید به هدفی که در مرحله نخست برای خود برنامهریزی کرده بودید برسید یا خیر. در آخرین مرحله، تمام یافتههای کلیدی را شناسایی میکنید، با دیگر اعضایت تیم ارتباط برقرار میکنید و بر اساس معیارهای توسعهیافته در مرحله اول، موفقیت یا شکست پروژه را تعیین میکنید.
مطالعهی موردی
اکنون که فهمیدیم دیتا ساینس چیست و فرایندهای تحلیل داده شامل چه مراحلی هستند، بیایید از یک مجموعهداده فرضی استفاده کرده و قدمبهقدم، چرخه عمر علم داده را برای پیشبینی احتمال ابتلا به دیابت طی کنیم:
قدم اول:
ابتدا دادهها را بر اساس تاریخچهی پزشکی بیماران جمعآوری میکنیم:
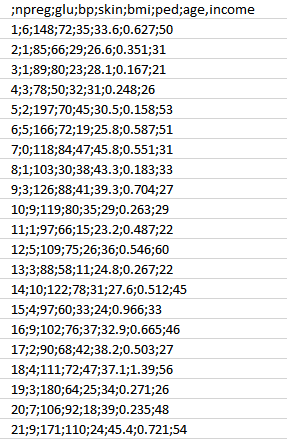
همانطور که میبینید در این مجموعه از داده، شاخصهای مختلفی داریم که در ادامه ذکر شدهاند:
شاخصها:
- NPREG – تعداد دفعات بارداری
- Glucose – غلظت گلوکز پلاسما
- BP – فشار خون
- Skin – ضخامت چربی عضله سهسر بازویی
- BMI – شاخص توده بدنی
- Ped – سابقهی خانوادگی دیابت
- Age – سن
- Income – درآمد
قدم دوم:
اکنون باید دادهها را پاکسازی و آماده کنیم. این داده مشکلات زیادی دارد، مانند از دست رفتن بخشی از داده، خالی ماندن برخی ستونها، مقادیر غیرمنتظره و فرمتهای اشتباهی که همگی باید تمیز شوند. دادهها را در یک جدول وارد کردهایم تا آمادهسازی و پاکسازی آنها آسانتر شود.
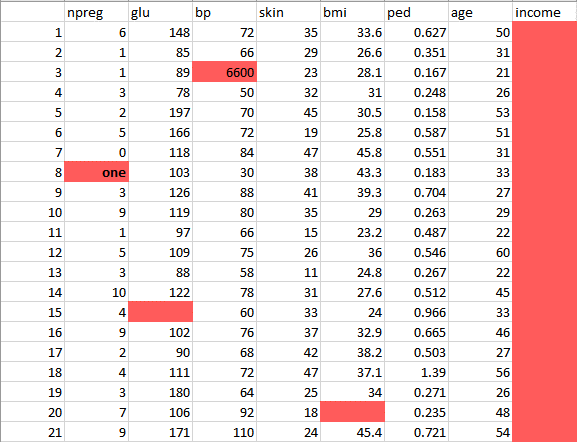
این دادهها دارای مشکلات زیاد هستند:
- در ستون npreg، یکی از دادهها در قالب کلمه نوشته شده، در حالی که باید به شکل عددی باشد.
- در ستون bp، یکی از مقادیر ۶۶۰۰ است که برای انسان غیرممکن است و bp نمیتواند به چنین مقداری برسد.
- همانطور که میبینید ستون درآمد یا Income خالی است و در پیشبینی دیابت نیز معنی ندارد. بنابراین، وجود آن در اینجا اضافی است و باید از جدول حذف شود.
بنابراین دادهها را با حذف اطلاعات پرت، پر کردن مقادیر تهی و اصلاح جنس داده، پاکسازی و پیشپردازش خواهیم کرد. در نهایت، دادههایی مطابق جدول زیر خواهیم داشت که میتوان از آنها برای تحلیل استفاده کرد.
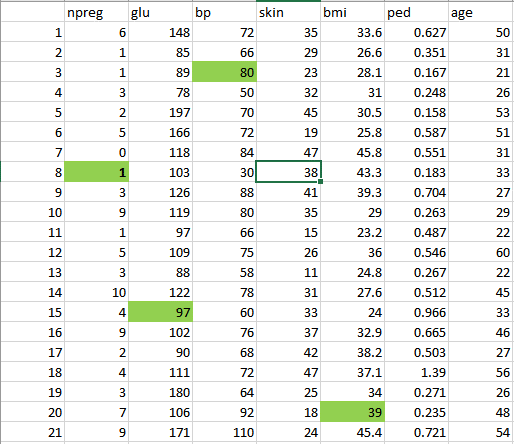
قدم سوم:
اکنون دادهها را در سندباکس تحلیلی بارگذاری کرده و توابع آماری مختلفی را روی آنها اعمال میکنیم. به عنوان مثال، R دارای توابعی مانند describe است که تعداد مقادیر از دسترفته و مقادیر منحصربهفرد را برمیگرداند. همچنین میتوانیم از تابع summary استفاده کنیم که اطلاعات آماری مانند میانگین، میانه، بازه، کمینه و بیشینه را به ما نشان میدهد. سپس از روشهای مصورسازی استفاده میکنیم تا درک درستی از توزیع داده به دست آوریم.
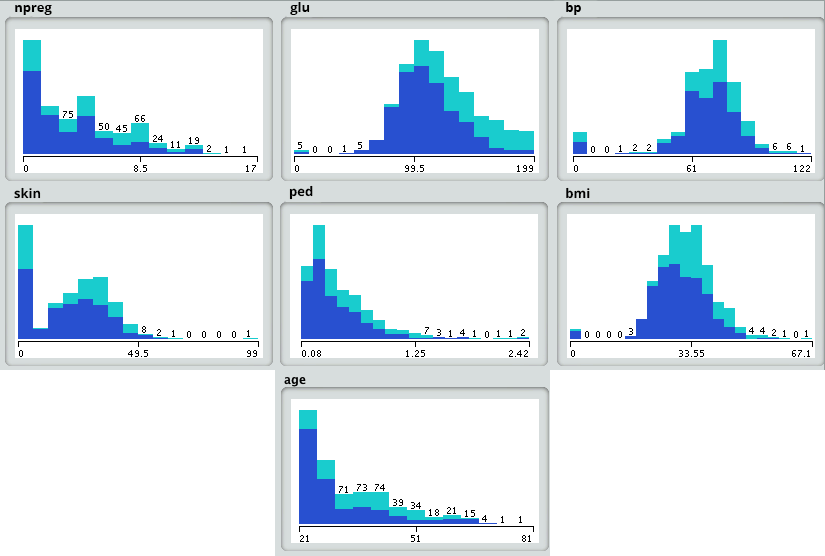
قدم چهارم:
از آنجا که از قبل شاخصههای اصلی مانند npreg ،bmi و… را در اختیار داریم، از تکنیک یادگیری نظارتشده برای ساخت مدل استفاده خواهیم کرد. علاوه بر این از درخت تصمیم (Decision Tree) استفاده میکنیم؛ زیرا همهی شاخصها چه آنهایی که رابطهی خطی دارند و چه آنهایی که رابطهی غیرخطی دارند را یکجا در نظر میگیرد.
در این مجموعه داده، یک رابطهی خطی بین npreg و سن وجود دارد، در حالی که رابطهی بین npreg و ped غیرخطی است. مدلهای درخت تصمیم بسیار قوی هستند؛ زیرا میتوانیم از ترکیب متفاوتی از شاخصها برای ایجاد درختهای مختلف استفاده کرده و درنهایت از مدلی که حداکثر کارایی را دارد استفاده کنیم. بیایید به درخت تصمیم خود نگاهی بیندازیم:
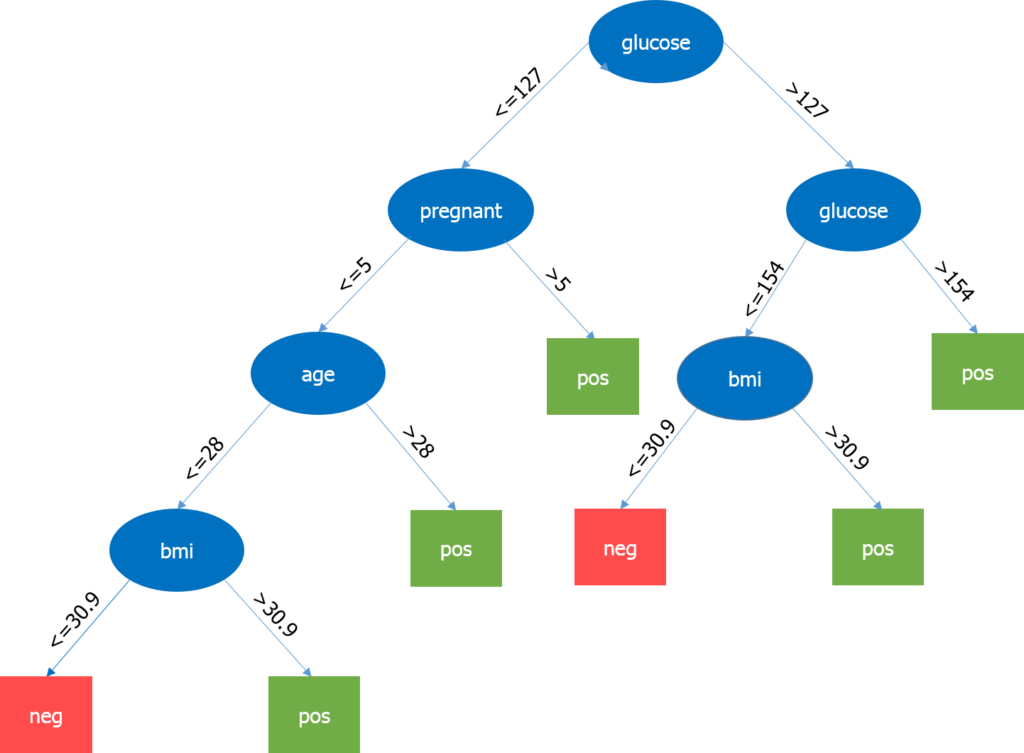
در اینجا مهمترین پارامتر سطح گلوکز است، بنابراین گره ریشه (Root Node) است. حالا گره فعلی و مقدار آن، پارامتر مهم بعدی را تعیین میکند. این کار ادامه پیدا میکند تا زمانی که به نتیجهی «pos» یا «neg» برسیم. pos به این معناست که فرد مستعد ابتلا به دیابت است و neg به این معنا که فرد احتمال ابتلا به دیابت وجود ندارد.
قدم پنجم:
در این مرحله، یک پروژه آزمایشی کوچک را اجرا خواهیم کرد تا بررسی کنیم که آیا نتایج ما مناسب هستند یا خیر. همچنین مدل را برای محدودیتهای عملکردی بررسی خواهیم کرد. اگر نتایج دقیق نیستند، باید مدل را دوباره برنامهریزی کرده و ایجاد کنیم.
قدم ششم:
هنگامی که پروژه را با موفقیت اجرا کردیم، خروجی را برای استقرار کامل به اشتراک خواهیم گذاشت.
چگونه دانشمند داده شویم؟
اکنون که میدانیم دیتا ساینس چیست این را هم میدانیم که علم داده نگاه ما به دنیای پیرامون و آکنده از داده خود تغییر کرده است. بنابراین اشتباه نخواهد بود که بگوییم آینده متعلق به دانشمندان داده است. همان طور که در تصویر زیر نشان داده شده است، یک دانشمند داده اساساً به مهارتهایی در سه حوزهی اصلی علوم کامپیوتر، ریاضیات و حوزهای که در آن مشغول به کار است، نیاز دارد.
شما باید مهارتهای سخت و نرم مختلفی را کسب کنید. برای تحلیل و مصورسازی دادهها باید دانش آمار و ریاضیات داشته باشید. نیازی به گفتن نیست که یادگیری ماشین قلب علم داده را تشکیل میدهد. بهعنوان یک دانشمند داده برای پیادهسازی الگوریتمهای مختلف، باید بتوانید کدنویسی کنید.
همچنین، باید درک کاملی از حوزهای که در آن کار میکنید داشته باشید تا بتوانید مشکلات کسبوکار را بهوضوح درک کرده، رشد کسبوکار را در سالهای آینده پیشبینی و استراتژیهایی را بر اساس دادهها ارائه کنید. علاوه بر همهی اینها مهارتهای ارتباطی خوب برای ارتباط مفید با سازمانها و سهامداران اهمیت دارد.