یادگیری ماشین چیست؟ همه چیز درباره Machine Learning

آیا تا به حال فکر کردهاید که چگونه قابلیت «People you may know» در فیسبوک همیشه فهرستی درست از افرادی که در زندگی واقعی میشناسید و در فیسبوک نیز میتوانید با آنها در ارتباط باشید را در اختیار شما قرار میدهد؟ چگونه فیسبوک از این موضوع مطلع میشود و چگونه این توصیهها را به شما ارائه میدهد؟ یادگیری ماشین (Machine Learning) پاسخ این سوال است. اما منظور از یادگیری ماشین چیست؟
در این مقاله تلاش میکنیم تا به این سوال و دیگر سوالات احتمالی شما درباره یادگیری ماشین پاسخ دهیم تا دید بهتری نسبت به این مفاهیم پیدا کنید. پس تا انتهای این مطلب همراه کوئرا بلاگ باشید.
یادگیری ماشین چیست؟
Machine Learning یا یادگیری ماشین که زیرمجموعهای از هوش مصنوعی و حوزهای از علوم محاسباتی است، بر تجزیهوتحلیل و تفسیر الگوها و ساختار دادهها تمرکز دارد. به زبان ساده، یادگیری ماشین زمینهای از علوم کامپیوتر است که این امکان را فراهم میکند تا ماشین بتواند بهتنهایی و بدون اینکه صریحاً برنامهنویسی شده باشد، یاد بگیرد.
بنابراین اساساً آنچه اتفاق میافتد این است که بهجای اینکه کد هر بار برای یک مسئلهی جدید نوشته شود، الگوریتم با دادهها تغذیه شده و سپس دادهها را تجزیهوتحلیل کرده و توصیهها و تصمیماتی را تنها بر اساس دادههای ورودی و بدون دخالت انسان ارائه میکند.
نکتهای که باید در اینجا به آن توجه شود این است که الگوریتمهای یادگیری ماشین درست مانند انسانها میتوانند از تجربیات گذشته خود یاد بگیرند! شما هنگامی که دادههای جدید را به آنها میدهید، این الگوریتمها یاد میگیرند، تغییر میکنند و بدون نیاز به تغییر هربارهی کد، رشد میکنند. ممکن است در ابتدا نتایج بهدستآمده از دقت بالایی برخوردار نباشند، اما الگوریتم یادگیری ماشین میتواند از دادههای خروجی خود برای بهبود نتایج در آینده استفاده کند.
تاریخچه مختصری از یادگیری ماشین
ممکن است فکر کنید که یادگیری ماشین (Machine Learning) یک موضوع نسبتاً جدید است، اما مفهوم یادگیری ماشین در سال 1950 مطرح شد؛ هنگامی که آلن تورینگ (بله، شخصیت اصلی فیلم The Imitation Game) مقالهای در پاسخ به این سؤال که «آیا ماشینها میتوانند فکر کنند؟» منتشر کرد.
در سال 1957، فرانک روزنبلات اولین شبکه عصبی را که امروزه به آن مدل پرسپترون میگویند، برای رایانهها طراحی کرد. شبکه عصبی یکی از الگوریتم های یادگیری ماشین است که مطابق مغز انسان مدل شده است و انواع مختلفی دارد. شبکه عصبی بازگشتی (recurrent neural networks) و شبکه عصبی کانولوشن (CNN) دو نمونه از انواع شبکههای عصبی هستند. مدل پرسپترون نیز یک الگوریتم طبقه بندی باینری در یادگیری تحت نظارت (Supervised Learning) است.
دو سال بعد و در سال 1959، برنارد ویدرو و مارسیان هاف دو مدل شبکه عصبی به نام ADALINE ایجاد کردند که میتوانستند الگوهای باینری و MADALINE را تشخیص دهند و انعکاس صدا در خطوط تلفن را از بین ببرند.
در حدود سال 1967، الگوریتم Nearest Neighbor نوشته شد که به رایانهها اجازه میداد از تشخیص الگوهای ابتدایی استفاده کنند.
جرالد دی جونگ در سال 1981 مفهوم یادگیری مبتنی بر توضیح (explanation-based learning) را مطرح کرد که در آن رایانه دادهها را تجزیهوتحلیل و یک قانون کلی برای کنار گذاشتن اطلاعات بیاهمیت ایجاد میکند.
در طول دهه 90 میلادی، کار بر روی یادگیری ماشین از رویکرد دانشمحور به رویکرد بیشتر دادهمحور تغییر کرد. در این دوره، دانشمندان شروع به ایجاد برنامههایی برای رایانهها کردند تا حجم زیادی از دادهها را تجزیهوتحلیل کرده و نتیجهگیری کنند و از نتایج آنها یاد بگیرند. سرانجام در طول زمان و پس از پیشرفتهای متعدد، یادگیری ماشین به شکل امروزی آن ارائه شد.
بیشتر بخوانید: شبکه عصبی کانولوشن (CNN) چیست؟
بیشتر بخوانید: تاریخچه یادگیری ماشین
اهمیت یادگیری ماشین چیست؟
تصور هرگونه فعالیت صنعتی بدون استفاده از یادگیری ماشین (Machine Learning) یا هوش مصنوعی (Artificial Intelligence) بسیار دشوار است. اهمیت یادگیری ماشین به دلیل طیف گستردهای از کاربردها و توانایی باورنکردنی آن در تطبیق و ارائه راهحلهای سریع، مؤثر و بهینه برای مشکلات است.
یادگیری ماشین تولید سریع و خودکار مدلهایی که بتوانند دادههای بزرگتر و پیچیدهتر را تجزیهوتحلیل کرده و نتایج سریع و دقیقتری را حتی در مقیاس بسیار بزرگ ارائه دهند، امکانپذیر کرده است. با ایجاد مدلهای دقیق، شانس بیشتری برای شناسایی فرصتهای سودآور یا اجتناب از خطرات ناشناخته وجود دارد.
شروع یادگیری ماشین
اگر به تازگی به دنیای جذاب یادگیری ماشین وارد شدهاید و به دنبال منبعی برای آموزش یادگیری ماشین هستید تا به شما برای ورود به بازار کار ماشین لرنینگ کمک کند، به شما دوره «یادگیری ماشین» کوئرا کالج را پیشنهاد میکنیم. این دورهها از کوئرا کالج، با داشتن تمرینهای کاربردی در کنار درسنامهی روان و قابل فهم، میتواند تمام انتظاراتی که از یک دوره خوب یادگیری ماشین دارید را برآورده کند. اگر با این حوزه هیچگونه آشنایی ندارید، به شما پیشنهاد میکنیم که همین حالا با دوره رایگان «یادگیری ماشین ۰ | دروازه ورود» شروع کنید.
برای این که بتوانید دید بهتری نسبت به مسیر خود بدست آورید نیز به شما پیشنهاد میکنیم تا مطلب «نقشه راه یادگیری ماشین» را در کوئرا بلاگ مطالعه کنید.
الگوریتمهای یادگیری ماشین چگونه کار میکنند؟
الگوریتمهای یادگیری ماشین (Machine Learning) از تکنیکهای مختلفی برای مدیریت حجم زیادی از دادههای پیچیده برای تصمیمگیری استفاده میکنند. این الگوریتمها کار یادگیری از دادهها را با ورودیهای خاصی که به دستگاه داده میشود، انجام میدهند. درک نحوهی عملکرد این الگوریتمها و سیستمهای یادگیری ماشین برای دانستن نحوهی استفاده از آنها در آینده بسیار اهمیت دارد.
همه چیز با آموزش الگوریتم با استفاده از مجموعه دادههای آموزش برای ایجاد یک مدل شروع میشود. سپس الگوریتم برای دادههای ورودی جدید یک پیشبینی ارائه میکند. پیشبینیها و نتایج برای بررسی دقت، ارزیابی میشوند. اگر پیشبینی مطابق انتظار نباشد، الگوریتم بارها و بارها آموزش داده میشود تا خروجی موردنظر به دست آید. این کار الگوریتم یادگیری ماشین را قادر میسازد تا بهتنهایی یاد بگیرد و یک پاسخ بهینه تولید کند که بهتدریج و در طول زمان دقت آن افزایش مییابد. پس از دستیابی به سطح دلخواه از دقت، الگوریتم یادگیری ماشین به کار گرفته میشود.
یک مثال ساده از نحوه کار یادگیری ماشین
وقتی در گوگل «Lion images» را جستجو میکنید، گوگل نتایج مرتبطی را به شما ارائه میکند. اما گوگل چگونه این کار را انجام میدهد؟
- گوگل ابتدا تعداد زیادی نمونه عکس (مجموعه داده) با برچسب «Lion» دریافت میکند.
- سپس الگوریتم به دنبال الگوهای پیکسل و الگوهای رنگی است که به آن در پیشبینی اینکه آیا تصویر «Lion» است یا خیر، کمک میکند.
- در ابتدا، رایانههای گوگل به طور تصادفی حدس میزنند که چه الگوهایی برای تشخیص تصویر «Lion» مناسب است.
- اگر الگوریتم اشتباه کند، مجموعهای از تغییرات انجام میشود تا بتواند درست تشخیص دهد.
- در نهایت، یک سیستم کامپیوتری بزرگ که از مغز انسان الگوبرداری شده است، از این مجموعه الگوها یاد میگیرد. این سیستم پس از آموزش، میتواند بهدرستی تصاویر «Lion» را شناسایی کرده و نتایج دقیقی را ارائه دهد.
اگر شما مسئول ساخت یک الگوریتم یادگیری ماشین برای تشخیص تصویر بین تصاویر شیرها و ببرها باشید. چگونه این کار را انجام میدهید؟
اولین قدم همان طور که در بالا توضیح دادیم، این است که باید تعداد زیادی عکس با برچسب «Lion» برای شیرها و «Tiger» برای ببرها جمعآوری کرد. سپس باید کامپیوتر را آموزش داد تا به دنبال الگوهای تصاویر برای شناسایی تصاویر شیرها و ببرها باشد. هنگامی که مدل یادگیری ماشین را train کردیم، میتوانیم تصاویر متفاوتی به آن بدهیم تا ببینیم که آیا میتواند بهدرستی تصاویر شیرها و ببرها را از همدیگر تشخیص دهد. یک مدل یادگیری ماشین آموزشدیده میتواند چنین درخواستهایی را بهدرستی تشخیص دهد.
اکنون که میدانیم الگوریتم یادگیری ماشین چیست و چگونه کار میکند، بیایید کمی عمیقتر به این موضوع بپردازیم و انواع مختلف یادگیری ماشین را بررسی کنیم.
ممکن است علاقهمند باشید: بهترین زبان برنامهنویسی برای یادگیری ماشین چیست؟
انواع یادگیری ماشین
یادگیری ماشین (Machine Learning) اغلب بر اساس نحوهی یادگیری الگوریتم طبقهبندی میشود. چهار رویکرد اصلی وجود دارد: یادگیری نظارتشده (supervised learning)، یادگیری بدون نظارت (unsupervised learning)، یادگیری نیمهنظارتی (semi-supervised learning) و یادگیری تقویتی (reinforcement learning). هر یک از این روشها طرز کار و هدف خاصی دارند.
یادگیری نظارتشده (supervised learning)
در یادگیری نظارتشده، دانشمندان داده الگوریتم را به کمک دادههای برچسبدار و متغیرهایی که میخواهند الگوریتم ارتباط آنها را ارزیابی کند، آموزش میدهند. هنگامی که مدل با مجموعهای از دادههای شناختهشده (برچسبدار) آموزش دید، دادههای ناشناخته (بدون برچسب) برای دریافت پاسخ جدید به مدل ارائه میشوند.
یادگیری ماشین نظارتشده مستلزم این است که دانشمندان داده، الگوریتم را با هر دو ورودی برچسبدار و خروجیهای موردنظر آموزش دهند.
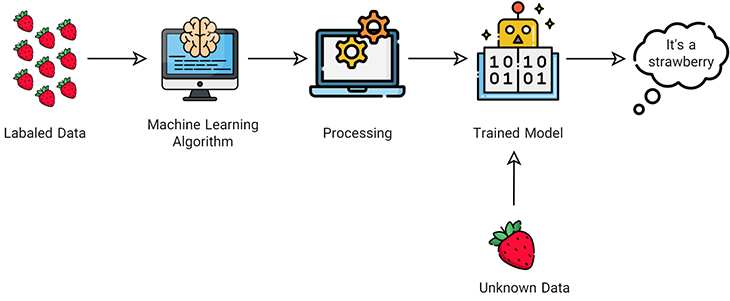
الگوریتمهای یادگیری نظارتشده برای کارهای زیر مناسب هستند:
- طبقهبندی دودویی: تقسیم دادهها به دو دسته
- طبقهبندی چندکلاسه: انتخاب بین بیش از دو دسته
- مدلسازی رگرسیون: پیشبینی مقادیر پیوسته
- کلاسهبندی جمعی: ترکیب پیشبینیهای چند مدل یادگیری ماشین برای تولید یک پیشبینی دقیق
یادگیری بدون نظارت (unsupervised learning)
این نوع یادگیری ماشین شامل الگوریتمهایی است که با استفاده از دادههای بدون برچسب یاد میگیرند. الگوریتمهای یادگیری ماشین بدون نظارت دادههای بدون برچسب را در جستجوی الگوهایی که میتوانند برای گروهبندی نقاط داده در زیرمجموعهها مورد استفاده قرار گیرند، بررسی میکنند.
نکتهای که باید به آن توجه شود این است که یادگیری بدون نظارت قادر به افزودن برچسب به دادهها نیست. به عنوان مثال، نمیتواند بگوید این گروهی از لیمو است یا توتفرنگی، اما همه لیموها را از توتفرنگیها جدا میکند.
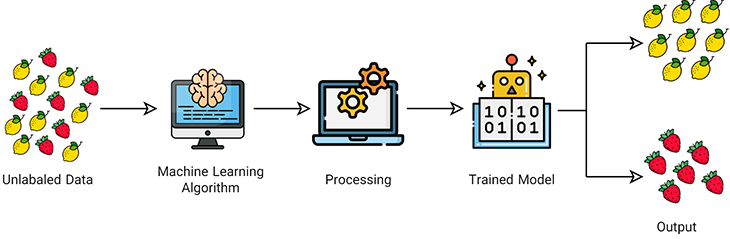
الگوریتمهای یادگیری بدون نظارت برای کارهای زیر مناسب هستند:
- خوشهبندی: تقسیم مجموعه دادهها به گروهها بر اساس شباهت
- تشخیص ناهنجاری: شناسایی نقاط داده غیرمعمول در یک مجموعه داده
- کاوش وابستگی: شناسایی مجموعهای از اقلام در یک مجموعه داده که اغلب با هم اتفاق میافتند.
- کاهش ابعاد: کاهش تعداد متغیرها در یک مجموعه داده. در واقع کاهش ابعاد زمانی اتفاق میافتد که بتوانیم دادهها را از جهات کمتری بررسی کنیم و نتیجه بررسی تفاوت فاحشی با حالت اولیه نداشته باشد.
در بخش بعدی بررسی میکنیم که رویکرد نیمهنظارتی یا semi-supervised learning در یادگیری ماشین چیست و کارکرد آن به چه صورت است.
یادگیری نیمهنظارتی (semi-supervised learning)
این رویکرد، ترکیبی از یادگیری نظارتشده (با دادههای آموزشی برچسبدار) و یادگیری بدون نظارت (بدون دادههای آموزشی برچسبدار) است. در یادگیری نیمهنظارتی فقط تعداد کمی از دادههای ورودی برچسبگذاری شدهاند.
در یادگیری ماشین نیمهنظارتی مدل ابتدا با استفاده از دادههای برچسبدار آموزش داده میشود. پس از آن دادههای بدون برچسب به مدل ارائه میشوند. مدل دادههای بدون برچسب را با دقت کمی برچسبگذاری میکند. به این دادهها، دادههای شبهبرچسبگذاریشده (Pseudo-labeled Data) میگوییم. در نهایت از ترکیب دادههای شبهبرچسبگذاریشده و دادههای برچسبدار اولیه برای بهبود دقت مدل استفاده میشود.
امروزه حجم عظیمی از دادهها در صنایع مختلف وجود دارد. اما برچسبگذاری دادههای جمعآوریشده به نیروی کار و منابع زیادی نیاز دارد و از این رو بسیار گران است. بنابراین بسیاری از پایگاههای داده واقعی در این دسته قرار میگیرند.
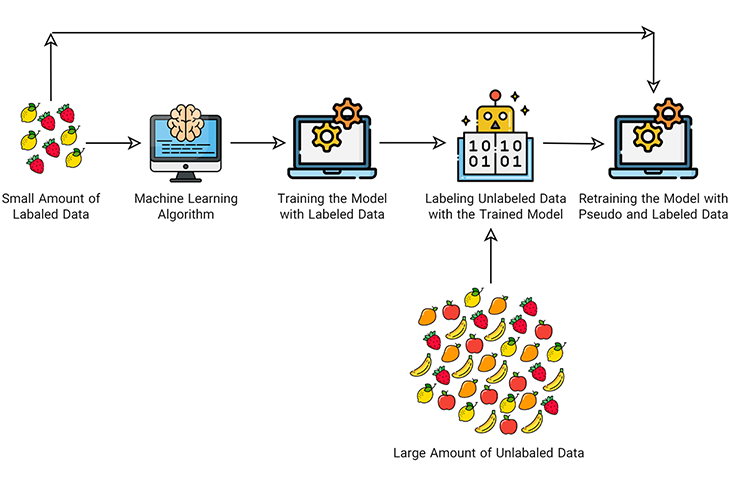
برخی از زمینههایی که در آنها از یادگیری نیمهنظارتی استفاده میشود، عبارتاند از:
- ترجمه ماشینی: آموزش الگوریتمهای ترجمه زبان
- تشخیص کلاهبرداری: شناسایی موارد کلاهبرداری هنگامی که فقط چند نمونه مثبت وجود دارد
- برچسب زدن دادهها: الگوریتمهای آموزش داده شده، به وسیله مجموعه دادههای کوچک میتوانند یاد بگیرند که برچسب دادهها را به صورت خودکار روی مجموعههای بزرگتر اعمال کنند.
یادگیری تقویتی (reinforcement learning)
رویکرد دیگر یادگیری ماشین، یادگیری تقویتی است. اما یادگیری تقویتی چیست؟ دانشمندان داده معمولاً از یادگیری ماشین تقویتی برای انجام یک فرایند چندمرحلهای که قوانین مشخصی برای آن وجود دارد، استفاده میکنند. آنها الگوریتم را برای انجام یک کار برنامهنویسی میکنند و در حالی که الگوریتم در تلاش برای انجام آن است، بازخوردهای مثبت یا منفی را به آن ارائه میدهند. وقتی مدل نتیجهای را پیشبینی یا تولید میکند، در صورت اشتباه بودن پیشبینی جریمه میشود و در صورت صحت پیشبینی پاداش میگیرد و بر این اساس، مدل خود را آموزش میدهد.
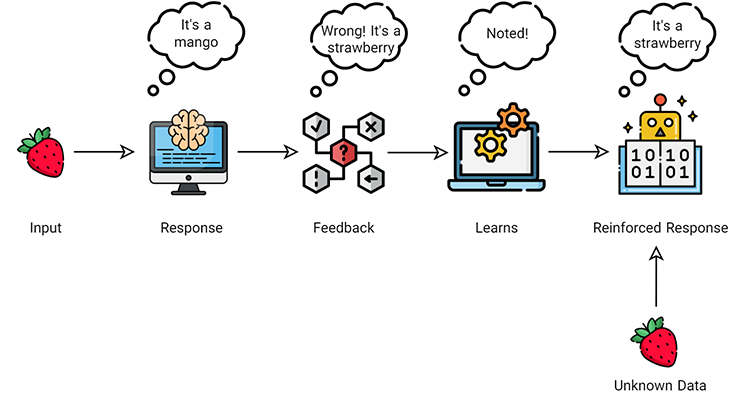
برخی از زمینههایی که در آنها از یادگیری تقویتی استفاده میشود، عبارتاند از:
- رباتیک: رباتها میتوانند با استفاده از این تکنیک، انجام وظایف دنیای واقعی را بیاموزند.
- بازیهای ویدئویی: از یادگیری تقویتی برای آموزش رباتها برای بازی در تعدادی از بازیهای ویدئویی استفاده شده است.
- مدیریت منابع: با توجه به منابع محدود و هدف مشخص، یادگیری تقویتی میتواند به شرکتها در برنامهریزی نحوه تخصیص منابع کمک کند.
اهمیت قابل تفسیر بودن مدلِ یادگیری ماشین چیست؟
توضیح نحوهی عملکرد یک مدل یادگیری ماشین پیچیده میتواند بسیار چالشبرانگیز باشد. دانشمندان داده در برخی صنایع از مدلهای ساده استفاده میکنند؛ زیرا توضیح چگونگی اتخاذ تصمیمها برای آن کسبوکار اهمیت دارد. مدلهای پیچیده میتوانند پیشبینیهای دقیقی را ارائه دهند، اما توضیح نحوه تعیین خروجی برای یک فرد با تخصص غیرمرتبط دشوار است.
تفاوتهای بین سه مفهوم هوش مصنوعی، یادگیری ماشین و یادگیری عمیق
حتی اگر مفهوم هوش مصنوعی(AI) و یادگیری عمیق (Deep Learning) را ندانید، احتمالا اسم آنها به گوشتان خورده است. اما دقیقا تفاوت هوش مصنوعی و یادگیری ماشین چیست و این دو چه تفاوتی با یادگیری عمیق دارند؟ امروزه هر دو این مفاهیم در کنار یادگیری ماشین نقش بسیار پررنگی در زندگی ما و پیشرفت سازمانهای مختلف ایفا میکنند. بنابراین بد نیست در این بخش کمی درمورد آنها صحبت کرده و تفاوتشان را بررسی کنیم.
هوش مصنوعی چیست؟
هوش مصنوعی به زبان ساده، شبیهسازی هوش انسان توسط دستگاهها به ویژه سیستمهای کامپیوتری است. این فرآیند شامل فراگیری و استفاده از دانش و انجام رفتار هوشمندانه میشود. به طور کلی هوش مصنوعی با جذب حجم بزرگی از دادههای آموزشی (Training Data) و لیبل دهی شده و تحلیل این دادهها برای یافتن الگویی برای پیشبینی وضعیت جدید کار میکند. مثلا یک ابزار تشخیص تصویر میتواند با بررسی میلیونها مثال، شیءها را در تصاویر شناسایی و توصیف کند.
یادگیری عمیق چیست؟
یادگیری عمیق در واقع یک زیرمجموعه از خانواده یادگیری ماشین است که از شبکههای عصبی برای شبیهسازی رفتار شبیه به مغز انسان استفاده میکند. همانطور که در بخشهای قبلی اشاره کردیم، شبکههای عصبی مشابه مغز انسان عمل کرده و از دادههای گذشته تجربه کسب میکنند. الگوریتمهای یادگیری عمیق مرکز خود را بر روی الگوهای پردازش اطلاعات متمرکز کرده تا بتواند امکان شناخت الگوها را فراهم کنند.
توجه کنید که هرچند یادگیری عمیق میتواند به صورت خودکار الگوهای پیچیده را از دادهها استخراج کند، اما به تنهایی نمیتواند درک کامل از مفاهیم و تفاوتهای مختلف را داشته باشد. به عنوان مثال، یادگیری عمیق نمیتواند به صورت خودکار از تفاوت بین دو تصویر “گربه” و “سگ” آگاهی پیدا کند، مگر اینکه به طور صریح به آن آموزش داده شود. بنابراین، یادگیری عمیق هوشمند است اما برای داشتن یک هوش مصنوعی کامل، باید از روشهای دیگر همچون استدلال، دانش و منطق نیز استفاده کرد.
تفاوتهای هوش مصنوعی و یادگیری عمیق با یادگیری ماشین چیست؟
میتوان گفت که یادگیری ماشین یک الگوریتم هوشمصنوعی یا زیرمجموعه آن است. یادگیری عمیق نیز زیرمجموعهای از یادگیری ماشین است که میتواند برای مقادیر زیاد اطلاعات به کار رود. نمونههایی از تفاوت این سه را در ادامه بررسی میکنیم.
- هدف هوش مصنوعی در اصل افزایش شانس موفقیت (Recall) است و دقت (accuracy) آن اهمیت زیادی ندارد، در یادگیری ماشین، هدف افزایش accuracy است و Recall از اهمیت کمتری برخوردار است. اما بالاترین میزان accuracy زمانی حاصل میشود که یادگیری عمیق با حجم بزرگی از اطلاعات آموزش داده شود.
- الگوریتمهای هوش مصنوعی با استفاده از تکنیکهای مختلفی مانند سیستمهای مبتنی بر قوانین، سیستمهای خبره (Expert System) و درخت تصمیمگیری توسعه داده میشوند. الگوریتمهای یادگیری ماشین با استفاده از روشهای مبتنی بر ریاضیات مانند شبکههای عصبی، درخت تصمیمگیری و رگرسیون لجستیک توسعه داده میشوند. الگوریتمهای یادگیری عمیق از شبکههای عصبی مصنوعی تشکیل شدهاند که شامل چندین لایه از نورونهای مصنوعی هستند.
- یادگیری ماشین از مقدار اطلاعات کمتری در مقایسه با هوش مصنوعی و یادگیری عمیق استفاده میکند.
- سیستمهای هوش مصنوعی میتوانند کاملا مستقل عمل کنند در حالی که در یادگیری ماشین، به درجهای از مداخله انسان نیاز است و در یادگیری عمیق، الگوریتمها برای آموزش و افزایش دقت به ارائه داده توسط انسان، ارزیابی عملکرد و بهینهسازی آن نیاز دارند.
مثالهایی از هوش مصنوعی، یادگیری عمیق و یادگیری ماشین
- هوش مصنوعی: هوش مصنوعی Google، برنامههایی مانند اوبر و لیفت که از هوش مصنوعی برای کنترل رانندگان و مسافران استفاده میکنند و پروازهای تجاری که از AI Autopilot استفاده میکنند.
- یادگیری ماشین: دستیارهای شخصی مجازی مانند سیری و الکسا، فیلترینگ اسپمها در ایمیل و …
- یادگیری عمیق: جمع کردن خبرهای بر اساس احساسات یا sentiment-based (خبرهایی که بر اساس احساسات و نگرشهایی که انتقال میدهند آنالیز و دستهبندی میشوند)، تحلیل تصویر، تولید عنوان و …
بیشتر بخوانید: پردازش تصویر چیست و چه کاربردهایی دارد؟
کاربرد یادگیری ماشین چیست؟
یادگیری ماشین در همهجا وجود دارد. ممکن است در زندگی روزمره بارها به نحوی از آن استفاده کنید و حتی از آن اطلاع نداشته باشید. مثالهایی از یادگیری ماشین:
تشخیص تصویر (Face Recognition)
تشخیص تصویر یکی از رایجترین کاربردهای یادگیری ماشین است. این فناوری، رایانهها و سیستمها را قادر میسازد تا اطلاعات معنیداری را از ورودیهای بصری بدست آورند.
تشخیص خودکار گفتار (Speech Recognition)
تشخیص خودکار گفتار برای تبدیل گفتار به متن استفاده میشود. کاربردهای آن در احراز هویت کاربران بر اساس صدای آنها و انجام وظایف بر اساس ورودی صدای انسان است.
سیستمهای توصیهگر (Recommendation System)
یادگیری ماشین بهطور گسترده توسط شرکتهای مختلف تجارت الکترونیک و سرگرمی برای توصیه محصول به کاربر استفاده میشود. الگوریتمهای یادگیری ماشین با استفاده از دادههای رفتار مصرف گذشته کاربر، علاقه کاربران را درک و مطابق با آن محصولاتی را به آنها پیشنهاد میکنند.
مدیریت ارتباط با مشتری (CRM)
نرمافزارهای مدیریت ارتباط با مشتری میتوانند از مدلهای یادگیری ماشین برای تجزیهوتحلیل ایمیل استفاده کرده و به اعضای تیم فروش توصیه کنند که ابتدا به مهمترین پیامها پاسخ دهند. برخی سیستمهای پیشرفتهتر حتی میتوانند پاسخهای مؤثر را توصیه کنند.
سیستمهای اطلاعات منابع انسانی (human resource information system)
سیستمهای منابع انسانی میتوانند از مدلهای یادگیری ماشین برای فیلتر کردن درخواستهای شغلی و شناسایی بهترین نامزدها برای یک موقعیت شغلی استفاده کنند.
تشخیص کلاهبرداری (Fraud Detection)
الگوریتمهای یادگیری ماشین با نظارت بر فعالیتهای هر کاربر، در تشخیص کلاهبرداری و فعالیتهای پولشویی بسیار عالی عمل میکنند و ارزیابی میکنند که آیا یک اقدام عملی معمولی برای آن کاربر است یا خیر.
فیلتر اسپم ایمیل (Spam Detection)
فیلتر هرزنامه ایمیل از یک مدل یادگیری ماشین نظارتشده برای فیلتر کردن ایمیلهای اسپم از صندوق پستی استفاده میکند.
معاملات خودکار سهام (Automated Trading Systems)
از آنجایی که در بازار سهام همیشه خطر بالا و پایین شدن سهام وجود دارد، از یادگیری ماشین بهطور گسترده در معاملات بازار سهام و برای پیشبینی الگوهای بازار سهام استفاده میشود. یادگیری ماشین سکوهای معاملاتی را قادر میسازد تا هزاران یا حتی میلیونها معامله را در روز و بدون دخالت انسان انجام دهند.
تشخیص بیماریها (Medical Diagnosis)
از الگوریتمهای یادگیری ماشین میتوان برای تشخیص بیماریها، تعیین بهترین دورهی درمان، کمک به تشخیص دقیقتر و… استفاده کرد. یادگیری ماشین همچنین قادر به ساخت مدلهای سهبعدی بهمنظور تعیین دقیق موقعیت ضایعات در مغز است.
مطلب مرتبط: کاربرد یادگیری ماشین چیست؟
مطلب مرتبط: یادگیری ماشین (Machine Learning) در امنیت سایبری
نحوهی انتخاب مدل یادگیری ماشین چیست؟
درک مسئله
ابتدا باید مسئله خود و اهدافی که قصد دارید با استفاده از یادگیری ماشین به آنها برسید را مشخص کنید. برای این کار میتوانید این سوالها را از خود بپرسید:
- مسئلهای که قصد دارید حل کنید چیست؟ (مثلا طبقهبندی، پیشبینی و غیره)
- فکر میکنید کدام الگوریتمهای یادگیری ماشین برای این مسئله مناسبتر هستند؟
- چه نوع دادههایی در اختیار دارید و چگونه میتوانید آنها را برای یادگیری ماشین استفاده کنید؟
بررسی دادهها
پس از درک مسئله، مرحله بعدی بررسی دادهها است. برای این کار بهتر است مراحل زیر را طی کنید.
- دادههای خام را پردازش و تمیز کنید.
- نمونههایی از دادهها را برای آموزش، تست و اعتبارسنجی تقسیم کنید.
- ویژگیهای مهم دادهها را شناسایی کنید.
انتخاب الگوریتم
در این مرحله، باید الگوریتمهای یادگیری ماشین مختلف را بررسی کرده و بر اساس نیازهای خود یک مدل مناسب را انتخاب کنید. برخی از معیارهای مهم عبارتاند از:
- سرعت آموزش و پیشبینی
- قابلیت تفسیر
- میزان پیچیدگی مدل
- عملکرد در برابر دادههای ناقص و نویزی
آموزش و اعتبارسنجی مدل
پس از انتخاب مدل مناسب، نوبت به آموزش و اعتبار سنجی آن میرسد. مراحل این بخش نیز به شرح زیر است:
- پارامترهای مدل را بهینهسازی کنید.
- مدل را با استفاده از دادههای آموزش آموزش دهید.
- عملکرد مدل را با استفاده از دادههای اعتبارسنجی ارزیابی کنید.
ارزیابی مدل
پس برای این که از عملکرد خوب مدل اطمینان حاصل کنید باید آن را ارزیابی کنید. اما چطور؟ موارد زیر برخی از روشهای این کار است.
- معیارهای ارزیابی مناسب را برای مسئله خود انتخاب کنید.
- مدل را با استفاده از دادههای تست ارزیابی کنید.
- نتایج را با الگوریتمهای رقیب مقایسه کنید.
بهینهسازی و تکرار
اگر با طی کردن مراحل بالا دیدید نتایج اولیه قابل قبول نیستند، باید به بهینهسازی و تکرار بپردازید. به این صورت که:
- پارامترها و تنظیمات مدل را بهینهسازی کنید.
- دادههای خود را مجددا بررسی و پردازش کنید.
- الگوریتمهای دیگری را بررسی و امتحان کنید.
به طور کلی انتخاب مدل یادگیری ماشین مناسب مسئله شما یک فرآیند تکاملی است و ممکن است نیاز به چندین بار تلاش و تکرار داشته باشد تا به بهترین مدل برای مسئله خود برسید. در نهایت، هدف اصلی ما انتخاب یک مدل است که بتواند به طور کارآمد و دقیق مسئله مورد نظر را حل کند.
تا اینجا درمورد این که یادگیری ماشین چیست، چه ویژگیها و کاربردهایی دارد و مطالبی از این دست صجبت کردیم. اما مهندس یادگیری ماشین به چه کسی گفته میشود؟ و این فرد چه وظایفی دارد؟
مهندس یادگیری ماشین کیست؟
مهندس یادگیری ماشین کسی است که سیستمها و راهحلهای یادگیری ماشین را طراحی، توسعه و پیادهسازی میکند. مهمترین وظایف و مسئولیتهای یک مهندس یادگیری ماشین عبارت است از:
طراحی و توسعه الگوریتمهای یادگیری ماشین
مهندسان یادگیری ماشین الگوریتمهای یادگیری ماشین، مانند درخت تصمیم، جنگل تصادفی و شبکههای عصبی را برای حل مسائل خاص طراحی، توسعه و پیادهسازی میکنند.
تحلیل داده
مهندسان یادگیری ماشین دادهها را با استفاده از تکنیکهای آماری و ریاضی تجزیه و تحلیل کرده و الگوها و روابطی که میتوانند برای آموزش مدلهای یادگیری ماشین استفاده شوند، شناسایی میکنند.
آموزش و ارزیابی مدل
مهندسان یادگیری ماشین مدلهای یادگیری ماشین را بر روی مجموعهدادههای بزرگ آموزش میدهند، عملکرد آنها را ارزیابی کرده و پارامترهای الگوریتمها را برای بهبود دقت تنظیم میکنند.
راهاندازی و نگهداری
مهندسان یادگیری ماشین مدلهای یادگیری ماشین را در محیطهای تولیدی راهاندازی کرده و آنها را به مرور زمان نگهداری و بهروزرسانی میکنند.
همکاری با دیگر بخشهای سازمان
مهندسان یادگیری ماشین بهطور نزدیک با دانشمندان داده، مهندسان نرمافزار و رهبران کسبوکار، همکاری میکنند تا نیازهای آنها را درک کنند و اطمینان حاصل کنند که راهحلهای یادگیری ماشین نیازهای آنها را برآورده میکنند.
تحقیق و نوآوری
مهندسان یادگیری ماشین با آخرین پیشرفتهای یادگیری ماشین آشنا هستند و به تحقیق و توسعه تکنیکها و الگوریتمهای جدید یادگیری ماشین کمک میکنند.
اگر میخواهید مهندس یادگیری ماشین شوید، باید دارای تخصص قوی در علوم کامپیوتر و ریاضیات و آمار و همچنین تجربه در توسعه الگوریتمها و راهحلهای یادگیری ماشین باشید. در ضمن، باید با زبانهای برنامهنویسی مانند پایتون و R آشنا بوده و تجربه کار با چارچوبها و ابزارهای یادگیری ماشین را نیز داشته باشید.
آینده یادگیری ماشین چگونه است؟
راهحلهای یادگیری ماشین همچنان در فرایندهای اصلی کسبوکارها تغییرات مهمی را ایجاد میکنند و در زندگی روزمره ما رایجتر میشوند. در حال حاضر بسیاری از شرکتها استفاده از یادگیری ماشین را به دلیل پتانسیل بالای آن برای پیشبینیهای دقیقتر و تصمیمگیریهای تجاری آغاز کردهاند. پیشبینی میشود بازار جهانی یادگیری ماشین از 8.43 میلیارد دلار در سال 2019 به 117.19 میلیارد دلار تا سال 2027 افزایش یابد.
با ادامهی گسترش فناوریهای جدید، میتوان از الگوریتمهای یادگیری ماشین بهرهورتری استفاده کرد. بهعنوان مثال با پیشرفت پردازندههای گرافیکی در آینده، محاسبه دادههای بزرگتر با سرعت بیشتری امکانپذیر خواهد بود.
یادگیری ماشین همچنین پتانسیل تحقیقاتی بالایی دارد. در حال حاضر یکی از موضوعات داغ در مقالات تحقیقاتی حوزهی علوم کامپیوتر، یادگیری ماشین (Machine Learning) است و از آن در صنایع و زمینههای تحقیقاتی مختلفی استفاده میشود. با این سرعت و افزایش نفوذ در بازار، یادگیری ماشین آینده درخشانی خواهد داشت.
جمعبندی
امروزه با توجه به رشد سریع فناوری و داده ها، یادگیری ماشین به عنوان یکی از رشته های پرطرفدار و جذاب در علوم کامپیوتر و داده ها شناخته میشود. اما یادگیری ماشین چیست؟ به طور خلاصه یادگیری ماشین با استفاده از الگوریتمهای خاص، امکان تحلیل دادهها و شناسایی الگوهایی برای پیشبینی دادههای آینده را به کامپیوتر میدهد.
در این مقاله علاوه بر پرداختن عمیقتر به مفهوم یادگیری ماشین، به مواردی همچون اهمیت یادگیری ماشین، انواع یادگیری ماشین، کاربردهای آن و… پرداختیم و تلاش کردیم تا به مهمترین چالشهای ذهنی علاقه مندان به این مفهوم پاسخ دهیم . خوشحال میشویم تا نظرات و سوالات خود را از طریق کامنت با ما در میان بگذارید.