آشنایی کامل با الگوریتم Random Forest
Random Forest یکی از محبوبترین و پرکاربردترین الگوریتمهای یادگیری ماشین از نوع نظارتشده است که برای پیشبرد امور دستهبندی و رگرسیون از آن استفاده میشود و همچنین یکی از الگوریتمهای مورد توجه در دوره یادگیری ماشین است. جنگل تصادفی از مجموعهای از درختهای تصمیم چندگانه برای تولید پیشبینی یا طبقهبندی استفاده میکند. با ترکیب خروجیهای درختان، الگوریتم جنگل تصادفی نتیجه تلفیقی و دقیقتری ارائه میدهد. محبوبیت گسترده Random Forest ناشی از ماهیت کاربرپسند و سازگاری آن است که الگوریتم را قادر میسازد تا بهطور موثری با مشکلات طبقهبندی و رگرسیون مقابله و آنها را حل کند؛ زیرا قدرت این الگوریتم در توانایی مدیریت مجموعه دادههای پیچیده و کاهش بیشبرازش نهفته است. در ادامه مقاله «الگوریتم Random Forest چیست؟» با کوئرا بلاگ همراه باشید تا این الگوریتم پرکاربرد و مشهور را بررسی کنیم.
الگوریتم جنگل تصادفی چیست؟
در پاسخ به سوال «الگوریتم جنگل تصادفی چیست؟» مایلیم ابتدا انواع الگوریتمهای یادگیری ماشین را تشریح کنیم؛ زیرا به درک نحوه عملکرد Random Forest کمک میکند. یادگیری ماشین شامل سه نوع الگوریتم میشود که عبارتند از:
- یادگیری تقویتی (Reinforcement Learning): فرآیند آموزش ماشین برای تصمیمگیری درست با استفاده از آزمونوخطا.
- یادگیری بدون نظارت (Unsupervised Learning): در این نوع، مجموعهای از دادههای بدون برچسب برای آموزش مدل ارائه میشود. در این شیوه آموزش بهصورت غیرمستقیم انجام میشود.
- یادگیری تحت نظارت (Supervised Learning): مجموعهای از دادههای برچسبگذاریشده به مدل ارائه میشود تا بداند هر داده را در کدام دسته قرار دهد. این شیوه مبتنی بر آموزش مستقیم است.
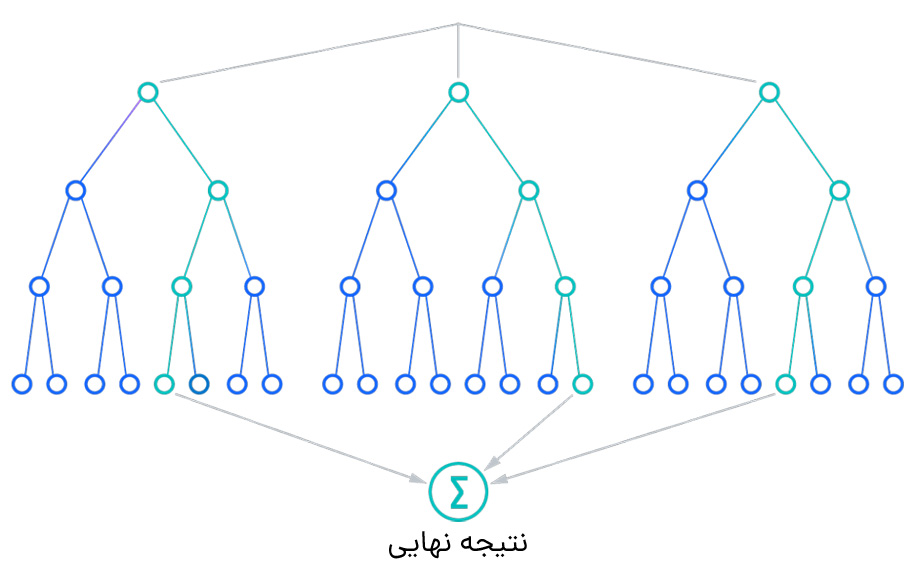
الگوریتم جنگل تصادفی نوعی الگوریتم یادگیری تحت نظارت است. در این نوع، دادههای آموزشی حاوی مقادیر ورودی و هدف هستند. الگوریتم الگویی را انتخاب میکند که مقادیر ورودی را به خروجی تعمیم میدهد و از این الگو برای پیشبینی مقادیر در آینده استفاده میکند. در شکل زیر نحوه عملکرد این الگوریتم ترسیم شده است.
این الگوریتم با طی کردن مراحل زیر تلاش دارد امور آینده را پیشبینی کند.
- مرحله اول: نمونههای تصادفی را از یک داده یا مجموعه آموزشی مشخص انتخاب میکند.
- مرحله دوم: این الگوریتم یک درخت تصمیم برای هر داده آموزشی میسازد.
- مرحله سوم: رایگیری با میانگینگیری از هر درخت تصمیم انجام میشود.
- مرحله چهارم: در نهایت، بیشترین رای بهعنوان نتیجه نهایی انتخاب میشود.
شاید علاقهمند باشید: یادگیری ماشین چیست؟
جنگل تصادفی در زندگی واقعی
برای درک بیشتر عملکرد جنگل تصادفی، بیایید به یک قیاس زندگی واقعی بپردازیم. دانشآموزی به نام X میخواهد بعد از دوران دبیرستان خود رشتهای را انتخاب کند و بر اساس مجموعه مهارت خود در انتخاب رشته دانشگاهی دچار سردرگمی میشود. بنابراین تصمیم میگیرد با افراد مختلفی مانند پسرعموها، معلمان، والدین، دانشجویان فارغالتحصیل و افراد شاغل مشورت کند. او از آنها سوالات مختلفی میپرسد، مانند اینکه چرا باید رشتههای بهخصوصی را انتخاب کند، فرصتهای شغلی هر رشته چه چیزهایی هستند، هزینه شرکت در دورههای آموزشی چگونه است و غیره. در نهایت، پس از مشورت با افراد مختلف در مورد بهترین انتخاب، تصمیم میگیرد رشته پیشنهادی که توسط اکثر افراد نام برده شد را ثبتنام کند.
جنگل تصادفی چگونه کار میکند؟
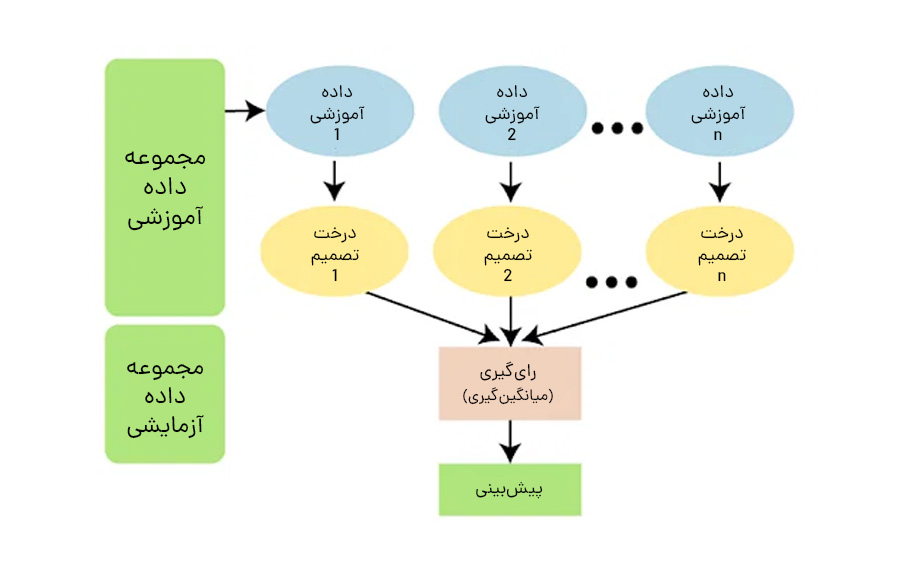
پیش از بررسی نحوه کارکرد این الگوریتم، باید تکنیک یادگیری تجمعی یا Ensemble را بررسی کنیم. جنگل تصادفی از تکنیک یادگیری گروهی برای تصمیمگیری نهایی استفاده میکند. یادگیری گروهی یک الگوی یادگیری ماشین است که در آن چندین مدل (اغلب یادگیرندگان ضعیف نامیده میشوند) برای حل مشکل آموزش داده و برای دستیابی به نتایج بهتر ترکیب میشوند. فرضیه اصلی در Ensemble این است که وقتی مدلهای ضعیف بهدرستی ترکیب شوند، میتوانیم مدلهای دقیقتر و قویتری بهدست آوریم.
در تئوری یادگیری گروهی، ما یادگیرندگان ضعیف (یا مدلهای پایه) را مدلهایی مینامیم که میتوانند به عنوان بلوکهای ساختمانی برای طراحی مدلهای پیچیدهتر با ترکیب چند مدل استفاده شوند. اغلب اوقات، این مدلهای پایه به خودیخود چندان خوب عمل نمیکنند، یا به این دلیل که دچار سوگیری بالایی هستند (مثلا مدلهایی با سوگیری کم) یا به این دلیل که واریانس زیادی برای قوی بودن دارند (مثلا مدلهای با سوگیری بالا).
ایده روشهای گروهی این است که سعی کنیم سوگیری و واریانس چنین یادگیرندگان ضعیفی را با ترکیب چند تا از آنها با هم کاهش دهیم تا یک یادگیرنده قوی (یا مدل گروهی) ایجاد کنیم که عملکرد بهتری را حاصل کند. یک نکته مهم این است که انتخاب یادگیرندگان ضعیف باید با روش جمعآوری این مدلها هماهنگ باشد. اگر مدلهای پایه با بایاس کم اما واریانس بالا را انتخاب کنیم، باید با روش تجمیعکنندهای باشد که تمایل به کاهش واریانس دارد؛ در حالیکه اگر مدلهای پایه با واریانس کم اما بایاس بالا را انتخاب کنیم، باید با روش تجمعی باشد که تمایل به کاهش بایاس دارد.
این موضوع ما را به این سوال میرساند که چگونه این مدلها را ترکیب کنیم. میتوان به سه نوع متا الگوریتم اصلی اشاره کرد که هدف آنها ترکیب یادگیرندگان ضعیف است:
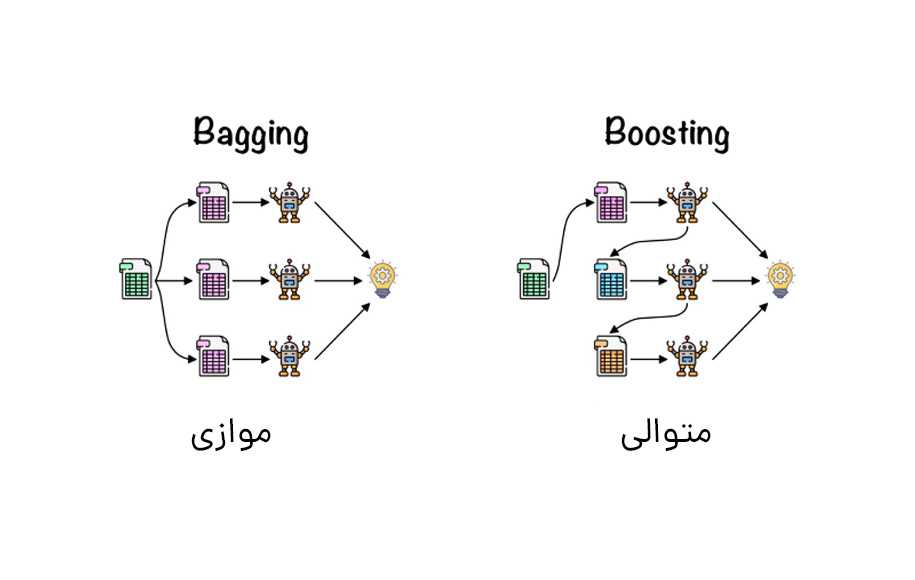
1. Bagging، که اغلب یادگیرندگان ضعیف همگن را در نظر میگیرد، آنها را بهطور موازی و مستقل از یکدیگر آموزش میدهد و در نهایت به دنبال نوعی فرآیند میانگینگیری قطعی، نمونهها را با هم ترکیب میکند.
2. Boosting، که اغلب یادگیرندگان ضعیف همگن را در نظر میگیرد، آنها را بهطور متوالی به روشی بسیار تطبیقی آموزش میدهد (یک مدل پایه به مدلهای قبلی بستگی دارد) و سپس بهدنبال یک استراتژی قطعی، آنها را با یکدیگر ترکیب میکند.
3. Stacking، که اغلب یادگیرندگان ضعیف ناهمگن را در نظر میگیرد، آنها را بهصورت موازی آموزش میدهد و با آموزش یک مدل متا برای ارائه خروجی یک پیشبینی بر اساس پیشبینیهای مختلف مدلهای ضعیف، آنها را ترکیب میکند.
بهطور تقریبی، میتوان گفت که Bagging عمدتا بر دستیابی به یک مدل مجموعه با واریانس کمتر از اجزای آن متمرکز است، در حالیکه Boosting و Stacking معمولا سعی میکنند مدلهای قویتری تولید کنند که سوگیری کمتری نسبت به اجزای آنها دارند (حتی اگر بتوان واریانس را کاهش داد). جنگل تصادفی بر اساس اصل Bagging کار میکند. حال در این بخش به بررسی جزئیات این روش خواهیم پرداخت.
در روشهای موازی، فراگیران مختلف را بهطور مستقل از یکدیگر برازش میدهیم و بنابراین امکان آموزش همزمان آنها وجود دارد. معروفترین چنین رویکردی “Bagging” (مخفف “Bootstrap Aggregating”) با هدف تولید یک مدل مجموعهای است که قویتر از مدلهای فردی سازنده عمل میکند.
Bootstrapping
بیایید با تعریف Bootstrapping شروع کنیم. این تکنیک آماری شامل تولید نمونههایی با اندازه B (به نام نمونههای راهانداز) از یک مجموعه داده اولیه با اندازه N با ترسیم تصادفی با مشاهدات جایگزین B است.
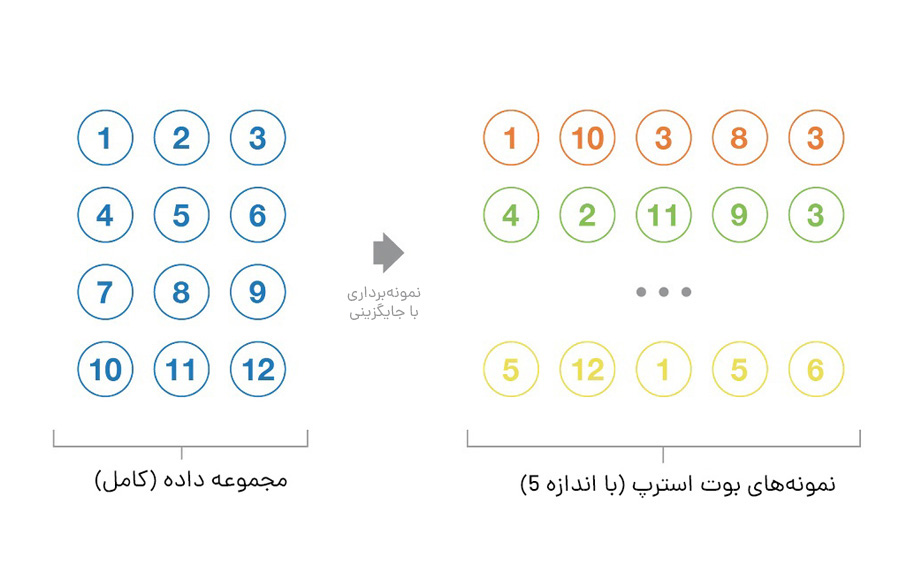
بر اساس برخی مفروضات، این نمونهها ویژگیهای آماری بسیار خوبی دارند: در تقریب اول، میتوان آنها را هم بهطور مستقیم از توزیع دادههای زیربنایی (و اغلب ناشناخته) و هم مستقل از یکدیگر در نظر گرفت. بنابراین، میتوان آنها را بهعنوان نمونههای نماینده و مستقل از توزیع واقعی دادهها در نظر گرفت.
فرضیههایی که برای معتبر ساختن این تقریب باید تایید شوند دو مورد هستند: اول، اندازه N مجموعه داده اولیه باید به اندازه کافی بزرگ باشد تا بیشتر پیچیدگی توزیع زیربنایی را به تصویر بکشد، بهطوری که نمونهبرداری از مجموعه داده، تقریب خوبی از نمونهبرداری از توزیع واقعی (بازنمایی) باشد. دوم، اندازه N مجموعه داده باید در مقایسه با اندازه B نمونههای راهانداز به اندازه کافی بزرگ باشد تا نمونهها بیش از حد همبستگی نداشته باشند (استقلال). توجه داشته باشید که در ادامه، گاهی اوقات به این ویژگیها (نمایندگی و استقلال) بهعنوان نمونههای بوت استرپ اشاره میکنیم و باید تقریبی بودن آنها را بهخاطر بسپارید.
نمونههای بوت استرپ اغلب برای ارزیابی واریانس یا فواصل اطمینان تخمینگرهای آماری استفاده میشوند. طبق تعریف، یک برآوردگر آماری، تابعی از برخی مشاهدات و بنابراین یک متغیر تصادفی با واریانس ناشی از این مشاهدات است. برای تخمین واریانس چنین برآوردگر، باید آن را بر چندین نمونه مستقل که از توزیع استخراج شدهاند، ارزیابی کنیم. در بیشتر موارد، در نظر گرفتن نمونههای مستقل به دادههای زیادی در مقایسه با مقدار واقعی موجود نیاز دارد. سپس میتوانیم از Bootstrapping برای تولید چندین نمونه بوت استرپ استفاده کنیم که میتوانند «تقریبا نماینده» و «تقریبا مستقل» در نظر گرفته شوند. این نمونههای بوت استرپ به ما امکان میدهند واریانس تخمینگر را با ارزیابی مقدار آن برای هر یک از نمونهها تقریبی کنیم.
هنگام آموزش یک مدل، مهم نیست که با یک مشکل طبقهبندی یا رگرسیون سروکار داریم، تابعی را به دست میآوریم که یک ورودی میگیرد، یک خروجی برمیگرداند و با توجه به مجموعه داده آموزشی تعریف میشود. ایده Bagging ساده است: ما میخواهیم چندین مدل مستقل را برازش کنیم و پیشبینیهای آنها را «میانگین» بگیریم تا مدلی با واریانس کمتر به دست آوریم. با این حال، در عمل نمیتوانیم مدلهای کاملا مستقل را متناسب کنیم؛ زیرا به دادههای زیادی نیاز داریم. بنابراین، به ویژگیهای تقریبی خوب نمونههای بوت استرپ (نمایندگی و استقلال) برای برازش مدلهایی که تقریبا مستقل هستند، تکیه میکنیم.
درختان یادگیری (Decision Trees) مدلهای پایه بسیار محبوب برای روشهای گروهی هستند. یادگیرندگان قوی متشکل از چندین درخت را میتوان «جنگل» نامید. درختانی که یک جنگل را تشکیل میدهند را میتوان بهصورت کم عمق یا عمیق انتخاب کرد. درختان کم عمق واریانس کمتر اما بایاس بیشتری دارند. از طرف دیگر، درختان عمیق سوگیری کم اما واریانس بالا دارند و بنابراین، گزینههای مناسبی برای روش Bagging هستند که عمدتا بر کاهش واریانس تمرکز دارد.
رویکرد جنگل تصادفی یک روش Bagging است که در آن درختان عمیق، نصبشده بر نمونههای بوت استرپ، برای تولید خروجی با واریانس کمتر ترکیب میشوند. با این حال، جنگلهای تصادفی از ترفند دیگری هم استفاده میکنند تا درختان چندگانه را مقداری کمتر با یکدیگر مرتبط کنند: هنگام رشد هر درخت، به جای نمونهبرداری از مشاهدات موجود در مجموعه داده برای تولید یک نمونه راهانداز، از ویژگیها نیز نمونهبرداری میکنیم و نگه میداریم تا یک زیر مجموعه تصادفی از آنها برای ساخت درخت ایجاد کنیم.
بیشتر بخوانید: الگوریتمهای یادگیری ماشین
ویژگیهای الگوریتم جنگل تصادفی
الگوریتم جنگل تصادفی دارای ویژگیهایی است که آن را نسبت به سایر الگوریتمهای یادگیری ماشین پایدارتر میکند تا قدرت تصمیمگیری و انتخاب نتیجه نهایی صحیح افزایش یابد. در ادامه به ویژگیهای الگوریتم جنگل تصادفی اشاره خواهیم کرد.
- تنوع: هر درخت دارای ویژگیهای منحصربهفرد و تنوع نسبت به درختان دیگر است. در این الگوریتم همه درختان یکسان نیستند.
- کاهش فضای اشغالشده: از آنجایی که درخت یک ایده مفهومی است، نیازی به در نظر گرفتن هیچ ویژگی ندارد. بنابراین، فضای ویژگی کاهش مییابد.
- موازیسازی: ما میتوانیم بهطور کامل از CPU برای ساخت جنگلهای تصادفی استفاده کنیم؛ زیرا هر درخت بهطور مستقل از دادهها و ویژگیهای مختلف ایجاد میشود.
- عدم نیاز به تقسیم دادههای آموزشی و آزمایشی: در یک جنگل تصادفی، مجبور نیستیم دادهها را برای آموزش و آزمایش متمایز کنیم؛ زیرا درخت تصمیم هرگز 30٪ از دادهها را نمیبیند.
- ثبات: نتیجه نهایی بر اساس رای اکثریت یا میانگین مجموع درختان است.
مزایای الگوریتم جنگل تصادفی
این الگوریتم همراه با مزایای خود میتواند برای موقعیتهایی استفاده شود که دیگر الگوریتمها قادر به پردازش دادههای آن موقعیت نیستند. در ادامه به مزایای جنگل تصادفی اشاره خواهیم کرد.
کاهش خطر بیشبرازش
درختهای تصمیمگیری دچار بیشبرازش میشوند؛ زیرا تمایل دارند تمام نمونهها را در دادههای آموزشی کاملا منطبق کنند. با این حال، هنگامی که تعداد زیادی درخت تصمیم در یک جنگل تصادفی وجود دارد، طبقهبندیکننده با مدل سازگاری بیش از حد پیدا نمیکند؛ زیرا میانگینگیری درختان غیر همبسته واریانس کلی و خطای پیشبینی را کاهش میدهد.
انعطافپذیری
از آنجاییکه جنگل تصادفی میتواند هر دو وظایف رگرسیون و طبقهبندی را با درجه بالایی از دقت انجام دهد، روشی محبوب در میان متخصصان داده است. همچنین Bagging ویژگی جنگل تصادفی را به ابزاری موثر برای تخمین مقادیر گمشده تبدیل میکند؛ زیرا دقت را در مواقعی که بخشی از دادهها از دست میروند، حفظ میکند.
تعیین آسان اهمیت ویژگی
تعیین اهمیت ویژگی از طریق چند روش امکانپذیر است. جنگل تصادفی از دو راه «اهمیت جینی (Gini)» و «کاهش میانگین ناخالصی (MDI)» برای ارزیابی اهمیت متغیر استفاده میکند. این دو روش معمولا برای اندازهگیری میزان کاهش دقت مدل، زمانی که یک متغیر معین حذف میشود، بهکار میروند. همچنین این الگوریتم از روشی دیگر به نام «اهمیت جایگشت» که بهعنوان دقت کاهش میانگین (MDA) هم شناخته میشود، بهمنظور تعیین اهمیت استفاده میکند. از دیگر مزایای این الگوریتم میتوان به موارد زیر اشاره کرد:
- میتواند هر دو وظایف رگرسیون و طبقهبندی را انجام دهد.
- پیشبینیهای خوبی تولید میکند که بهراحتی قابل درک است.
- میتواند مجموعه دادههای بزرگ را بهطور موثر اداره کند.
- سطح بالاتری از دقت پیشبینی نتایج در الگوریتم تصمیمگیری را فراهم میکند.
تفاوت جنگل تصادفی و درخت تصمیم
درخت تصمیم یکی از الگوریتمهای تحت نظارت است که با ساختن یک ساختار درختمانند کار میکند، جایی که هر گره نشاندهنده یک تصمیم و هر گره برگ نشاندهنده یک پیشبینی است. درخت تصمیم با تقسیم بازگشتی دادهها به زیر مجموعههای فرزند، بر اساس مقادیر ویژگیها ساخته میشود. برای پیشبینی یک نقطه داده جدید، الگوریتم کار خود را از گره ریشه درخت شروع و شاخهها را تا رسیدن به یک گره برگ دنبال میکند. سپس پیشبینی توسط برچسب گره برگ تعیین میشود. از طرفی دیگر، جنگل تصادفی یک الگوریتم یادگیری گروهی است که از چندین درخت تصمیم برای پیشبینی استفاده میکند. این الگوریتم با آموزش تعداد زیادی درخت تصمیم بر زیر مجموعههای مختلف دادههای آموزشی کار خود را انجام میدهد. اما این دو تفاوتی با یکدیگر دارند که در ادامه به سه مورد از مهمترین آنها اشاره خواهیم کرد.
| درخت تصمیم | جنگل تصادفی |
| اگر اجازه داده شود بدون هیچ کنترلی رشد کند، معمولا دچار مشکل بیشبرازش (Overfitting) خواهد شد. | از آنجایی که از زیرمجموعههای داده ایجاد میشوند و خروجی نهایی بر اساس رتبهبندی متوسط یا اکثریت است، مشکل بیشبرازش (Overfitting) در رخ نمیدهد. |
| یک درخت تصمیم واحد در محاسبات نسبتا سریعتر است. | جنگل تصادفی سرعت کمتری نسبت به درخت تصمیم دارد. |
| هنگامی که یک مجموعه داده با ویژگیها بهعنوان ورودی در نظر گرفته میشود، از مجموعه خاصی از قوانین استفاده میکند. | بهطور تصادفی مشاهدات را انتخاب میکند، یک درخت تصمیم میسازد و سپس نتیجه بر اساس رای اکثریت بهدست میآید. در این الگوریتم هیچ فرمولی لازم نیست. |
بیشتر بخوانید: درخت تصمیم (Decision Tree) – تعریف، مزایا و کاربردها
کاربردهای الگوریتم جنگل تصادفی
برخی از کاربردهای الگوریتم جنگل تصادفی در زیر ذکر شده است:
بانکداری
این الگوریتم میزان پرداخت بدهی متقاضی وام را پیشبینی میکند. این موضوع موسسات وامدهنده را قادر میسازد تا تصمیم درستی در مورد دادن وام به مشتری بگیرند. همچنین از این الگوریتم برای شناسایی کلاهبرداران استفاده میشود.
سیستم سلامت
متخصصان بهداشت از سیستمهای جنگل تصادفی برای تشخیص بیماران و بیماری آنها استفاده میکنند. در این فرآیند، با ارزیابی سابقه پزشکی قبلی هر فرد، بیمار بودن یا نبودن او تشخیص داده میشود. همچنین الگوریتم Random Forest برای بررسی سوابق پزشکی گذشته هر شخص برای تعیین دوز مناسب دارو بهکار میرود.
بازار سهام
تحلیلگران مالی از این الگوریتم برای شناسایی بازارهای بالقوه سهام استفاده میکنند. همچنین الگوریتم جنگل تصادفی تحلیلگران را قادر میسازد تا رفتار سهام را بهخاطر بسپارند.
تجارت الکترونیک
از طریق این سیستم، فروشندگان Ecommerce میتوانند ترجیحهای مشتریان را بر اساس رفتار مصرفی گذشتهشان پیشبینی کنند.
معایب الگوریتم جنگل تصادفی
جنگل تصادفی در کنار مزایای خود، دارای معایبی است که در ادامه به آنها اشاره خواهیم کرد.
- با استفاده از الگوریتم جنگل تصادفی، منابع بیشتری برای محاسبات مورد نیاز است. از آنجاییکه جنگل تصادفی مجموعه دادههای بزرگتری را پردازش میکند، به منابع بیشتری برای ذخیره آن دادهها نیاز دارد.
- در مقایسه با الگوریتم درخت تصمیم، زمان بیشتری مصرف میکند. از آنجاییکه الگوریتمهای جنگل تصادفی میتوانند مجموعه دادههای بزرگی را مدیریت و پیشبینیهای دقیقتری ارائه کنند، اما در عین حال در پردازش دادهها کند هستند؛ زیرا برای هر درخت تصمیم، دادهها را محاسبه میکنند.
- وقتی مجموعه گستردهای از درختان تصمیم داریم، عملکرد آن کمتر قابل درک است.
- بسیار پیچیدهتر از درخت تصمیم عمل میکند؛ زیرا تفسیر یک درخت تصمیم منفرد در مقایسه با جنگل تصادفی آسانتر است.
آنچه در الگوریتم جنگل تصادفی خواندیم
اگر مایلید مدل سریع و کارآمد بسازید، الگوریتم جنگل تصادفی یک انتخاب عالی است؛ زیرا یکی از بهترین چیزها در مورد جنگل تصادفی این است که میتواند مقادیر از دسترفته را مدیریت کند. این الگوریتم یکی از بهترین تکنیکها با عملکرد بالا است که بهطور گسترده در صنایع مختلف استفاده میشود. جنگل تصادفی میتواند دادههای باینری، پیوسته و دستهبندی را مدیریت کند. بهطور کلی، جنگل تصادفی یک مدل سریع، ساده، انعطافپذیر و قوی است.