یادگیری ماشین چیست؟ همه آنچه که باید درمورد ماشین لرنینگ بدانید!

تا به حال به این فکر کردهاید که اینستاگرام چطور همیشه افرادی را که در دنیای واقعی میشناسید، برای دنبال کردن پیشنهاد میدهد؟ این پلتفرم چگونه از ارتباطات شما باخبر میشود و چطور این پیشنهادها را به این دقت ارائه میکند؟ پاسخ در یک مفهوم کلیدی نهفته است: «یادگیری ماشین». اما یادگیری ماشین چیست و چگونه زندگی روزمره همه ما را تحت تأثیر قرار داده است؟
در ادامه با کوئرا بلاگ همراه باشید تا به این سوال و دیگر سوالات احتمالی شما درباره یادگیری ماشین پاسخ دهیم تا درک بهتری نسبت به این مفاهیم پیدا کنید.
یادگیری ماشین چیست ؟
یادگیری ماشین (Machine Learning | ML) زیرمجموعهای از هوش مصنوعی (Artificial Intelligence | AI) و حوزهای از علوم محاسباتی است که بر تجزیه و تحلیل و تفسیر الگوها و همینطور ساختمانهای داده تمرکز دارد. به زبان سادهتر، یادگیری ماشین زمینهای از علوم کامپیوتر است که به کامپیوترها اجازه میدهد بهتنهایی و بدون اینکه صریحاً برنامهنویسی شده باشد، مهارتها و تواناییهای تازه را یاد بگیرند.
بنابراین بهجای اینکه برای هر مسئله کدی جدید نوشته شود، الگوریتم با انبوهی داده تغذیه میشود و پس از تجزیه و تحلیل آنها، توصیهها و تصمیمات گوناگون را صرفا براساس دادههای ورودی (و بدون دخالت انسانی) پیشنهاد میکند.
نکته نیازمند توجه این است که الگوریتمهای یادگیری ماشین درست مانند انسانها از تجربیات گذشته خود یاد میگیرند. هر زمان که دادههای جدید را در اختیار الگوریتمها میگذارید، نکات تازه میآموزند، تغییر میکنند و بدون نیاز به تغییر چند مرتبهای کد، بالغتر میشوند. ممکن است در ابتدا نتایج بهدستآمده آنقدرها دقیق نباشند، اما الگوریتم یادگیری ماشین میتواند از دادههای خروجی خود برای بهبود نتایج در آینده نیز استفاده کند.
تاریخچه مختصری از یادگیری ماشین
ممکن است تصور کنید که یادگیری ماشین موضوعی نسبتاً جدید است، اما مفهوم و تاریخچه یادگیری ماشین به سال ۱۹۵۰ بازمیگردد؛ زمانی که آلن تورینگ (پدر هوش مصنوعی که فیلم The Imitation Game راجع به زندگی او ساخته شده) مقالهای در پاسخ به این سؤال که «آیا ماشینها میتوانند فکر کنند؟» منتشر کرد.

در سال ۱۹۵۷، فرانک روزنبلات اولین شبکه عصبی که امروز به نام «مدل پرسپترون» شناخته میشود را برای رایانهها طراحی کرد. شبکه عصبی یکی از انواع الگوریتم های یادگیری ماشین است که مطابق مغز انسان مدلسازی میشود و انواع مختلفی دارد. شبکه عصبی بازگشتی (Recurrent Neural Networks) و شبکه عصبی کانولوشن (CNN) دو نمونه از انواع شبکههای عصبی هستند. مدل پرسپترون نیز نوعی الگوریتم طبقهبندی دودویی (باینری) در یادگیری تحت نظارت (Supervised Learning) است.

دو سال بعد و در سال ۱۹۵۹، برنارد ویدرو و مارسیان هاف، مدل شبکه عصبی به نام ADALINE توسعه دادند که میتوانست الگوهای باینری را تشخیص دهند و انعکاس صدا در خطوط تلفن را از بین ببرد.
تقریبا سال ۱۹۶۷ بود که الگوریتم Nearest Neighbor نوشته شد. این الگوریتم به رایانهها اجازه میداد الگوهای ابتدایی را شناسایی و تحلیل کنند. تقریبا دو دهه بعد، جرالد دی جونگ مفهوم یادگیری تشریحی (Explanation-Based Learning) را مطرح کرد که در آن رایانه دادهها را تجزیهوتحلیل و یک قانون کلی برای کنار گذاشتن اطلاعات بیاهمیت را دنبال میکند.
در جریان دهه ۹۰ میلادی، کار روی یادگیری ماشین عمدتا از رویکرد دانشمحور فاصله گرفت و به رویکرد دادهمحور متمایل شد. در این دوره، دانشمندان شروع به ساخت برنامههای کامپیوتری گوناگونی کردند که حجم زیادی از دادهها را تجزیهوتحلیل میکردند، به نتیجهگیری میرسیدند و از همان نتایج میآموختند. سرانجام در طول زمان و پس از پیشرفتهای متعدد، یادگیری ماشین به شکل امروزیاش درآمد.
الگوریتمهای یادگیری ماشین چگونه کار میکنند؟
الگوریتمهای یادگیری ماشین از تکنیکهای مختلف برای مدیریت حجم زیادی از دادههای پیچیده برای تصمیمگیری استفاده میکنند. این الگوریتمها فرایند آموختن از دادهها را با ورودیهای خاصی که به دستگاه داده میشود، پیش میبرند. درک نحوه عملکرد این الگوریتمها و سیستمهای یادگیری ماشین برای بهکارگیری آنها در آینده ضروری است.
همه چیز با تعلیم الگوریتم با استفاده از مجموعه دادههای آموزشی شروع میشود تا یک مدل یادگیری ماشین به دست آوریم. سپس الگوریتم برای دادههای ورودی جدید یک پیشبینی ارائه میکند. در مرحله بعد پیشبینیها و نتایج برای بررسی سطح دقت، ارزیابی میشوند. اگر پیشبینی مطابق انتظار نباشد، الگوریتم بارها و بارها آموزش داده میشود تا خروجی موردنظر به دست آید.
این کار به الگوریتم یادگیری ماشین اجازه میدهد که بهتنهایی یاد بگیرد و به پاسخی برسد که دقت و بهینگی آن در طول زمان افزایش یابد. پس از دستیابی به سطح دلخواه از دقت، الگوریتم یادگیری ماشین برای به کار گرفته شدن آماده است.
یک مثال ساده از نحوه کار یادگیری ماشین

وقتی در گوگل عبارتی مانند «Lion Images» (به معنی تصاویر شیر) را جستجو میکنید، گوگل نتایجی مرتبط را به نمایش درمیآورد. اما این فرایند چطور طی میشود و گوگل چطور به نتایج مورد نیاز شما میرسد؟
- گوگل ابتدا تعداد زیادی نمونه عکس (یا به عبارت دیگر، مجموعه داده) با برچسب «Lion» را فراخوانی و دریافت میکند.
- سپس الگوریتم به دنبال الگوهای پیکسل و الگوهای رنگی گوناگوین میگردد که به آن در پیشبینی این موضوع کمک میکنند که آیا تصویر واقعا به عبارت «Lion» مرتبط است یا خیر.
- در ابتدا، رایانههای گوگل به طور تصادفی حدس میزنند که چه الگوهایی برای تشخیص تصویر «Lion» مناسب است.
- اگر الگوریتم اشتباه کند، مجموعهای از تغییرات انجام میشود تا امکان تشخیص درستتر مهیا شود.
- در نهایت، یک سیستم کامپیوتری بزرگ که با الگوبرداری از مغز انسان ساخته شده، از این مجموعه الگوها یاد میگیرد. این سیستم پس از پشت سر گذاشتن فرایند آموزش، میتواند بهدرستی تصاویر «Lion» را شناسایی و نتایجی دقیق ارائه دهد.
اما اگر شما مسئول ساخت یک الگوریتم یادگیری ماشین برای تشخیص تصویر بین تصاویر شیرها و ببرها باشید، چگونه باید چنین کاری را عملی کنید؟
اولین قدم این است که باید تعداد زیادی عکس با برچسب «Lion» برای شیرها و «Tiger» برای ببرها جمعآوری کنیم. سپس باید کامپیوتر را آموزش داد تا به دنبال الگوهای تصویری موجود برای شناسایی تصاویر شیرها و ببرها باشد. هنگامی که مدل یادگیری ماشین را تعلیم دادیم، میتوانیم تصاویر متفاوتی به آن بدهیم تا ببینیم که آیا بهدرستی تصاویر شیرها و ببرها را از یکدیگر تمیز میدهد یا خیر. یک مدل یادگیری ماشین آموزشدیده میتواند چنین درخواستهایی را بهدرستی تشخیص دهد.
اکنون که میدانیم الگوریتم یادگیری ماشین چیست و چگونه کار میکند، بیایید کمی عمیقتر به این موضوع بپردازیم و انواع مختلف یادگیری ماشین را بررسی کنیم.
- بیشتر بخوانید: بهترین زبان برنامهنویسی برای یادگیری ماشین چیست ؟
انواع یادگیری ماشین
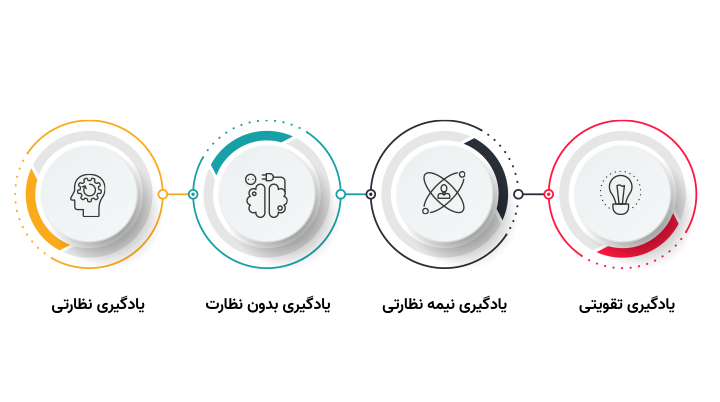
یادگیری ماشین (Machine Learning) اغلب بر اساس نحوهی یادگیری الگوریتم طبقهبندی میشود. به صورت کلی چهار رویکرد برای تعلیم مدلها داریم: یادگیری نظارتی (Supervised Learning)، یادگیری بدون نظارت (Unsupervised Learning)، یادگیری نیمهنظارتی (Semi-Supervised Learning) و یادگیری تقویتی (Reinforcement Learning). هر یک از این رویکردها طرز کار و هدف خاص خود را دارند.
یادگیری نظارتی (Supervised Learning)
در یادگیری نظارتی، دانشمندان داده الگوریتم را به کمک دادههای برچسبدار و متغیرهایی که قرار است ارتباط میان آنها شناسایی شود، آموزش میدهند. هنگامی که مدل با مجموعهای از دادههای شناختهشده (برچسبدار) آموزش دید، دادههای ناشناخته (بدون برچسب) برای دریافت پاسخ جدید به مدل ارائه میشوند.
یادگیری ماشین نظارتی نیازمند این است که دانشمندان داده، الگوریتم را با هر دو ورودی برچسبدار و خروجیهای مورد نیاز آموزش دهند.
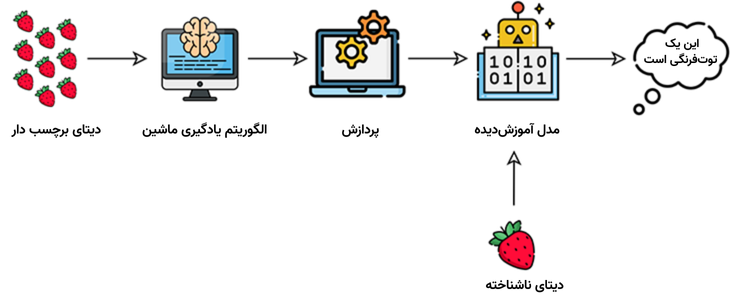
الگوریتمهای یادگیری نظارتی برای وظایف زیر مناسب هستند:
- طبقهبندی دودویی: تقسیم دادهها به دو دسته
- طبقهبندی چندکلاسه: انتخاب بین بیش از دو دسته
- مدلسازی رگرسیون: پیشبینی مقادیر پیوسته
- کلاسبندی جمعی: ادغام پیشبینیهای چند مدل یادگیری ماشین برای تولید یک پیشبینی دقیق
یادگیری بدون نظارت (Unsupervised Learning)
این نوع یادگیری ماشین شامل الگوریتمهایی است که با استفاده از دادههای بدون برچسب تعلیم میبینند. الگوریتمهای یادگیری ماشین بدون نظارت، دادههای بدون برچسب را بررسی میکنند و در صدد گروهبندی نقاط داده گوناگون برمیآیند.
نکته مهم اینکه یادگیری بدون نظارت قادر به افزودن برچسب به دادهها نیست. به عنوان مثال، نمیتواند تصاویر را در دو دستهبندی «لیمو» و «توتفرنگی» قرار دهد، اما همه لیموها را از همه توتفرنگیها جدا میکند.
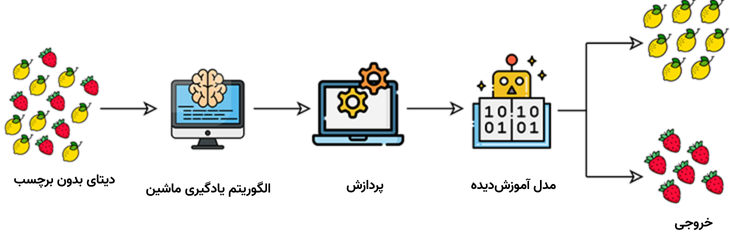
الگوریتمهای یادگیری بدون نظارت برای وظایف زیر مناسب هستند:
- خوشهبندی: تقسیم مجموعه دادهها به گروههای مختلف بر اساس شباهت
- تشخیص ناهنجاری: شناسایی نقاط داده غیرمعمول در یک مجموعه داده
- کاوش وابستگی: شناسایی مجموعهای از اقلام در یک مجموعه داده که اغلب همراه باهم اتفاق میافتند.
- کاهش ابعاد: کاهش تعداد متغیرها در یک مجموعه داده. کاهش ابعاد زمانی اتفاق میافتد که بتوانیم دادهها را از جهات کمتری بررسی کنیم و نتیجه بررسی تفاوت فاحشی با حالت اولیه نداشته باشد.
در بخش بعدی بررسی میکنیم که رویکرد نیمهنظارتی یا Semi-Supervised Learning در دنیای یادگیری ماشین چیست و کارکرد آن به چه صورت است.
یادگیری نیمهنظارتی (Semi-Supervised Learning)
این رویکرد، ترکیبی از یادگیری نظارتشده (با دادههای برچسبدار) و یادگیری بدون نظارت (بدون دادههای برچسبدار) است. در یادگیری نیمهنظارتی فقط تعداد کمی از دادههای ورودی برچسبگذاری شدهاند.
در یادگیری نیمهنظارتی ماشین، مدل ابتدا با استفاده از دادههای برچسبدار تعلیم داده میشود. پس از آن دادههای بدون برچسب در اختیار مدل قرار میگیرند. مدل سپس دادههای بدون برچسب را با دقتی پایین برچسبگذاری میکند. به این دادهها، دادههای شبهبرچسبگذاریشده (Pseudo-labeled Data) میگوییم. در نهایت از ترکیب دادههای شبهبرچسبگذاریشده و دادههای برچسبدار اولیه برای بهبود دقت مدل استفاده میشود.
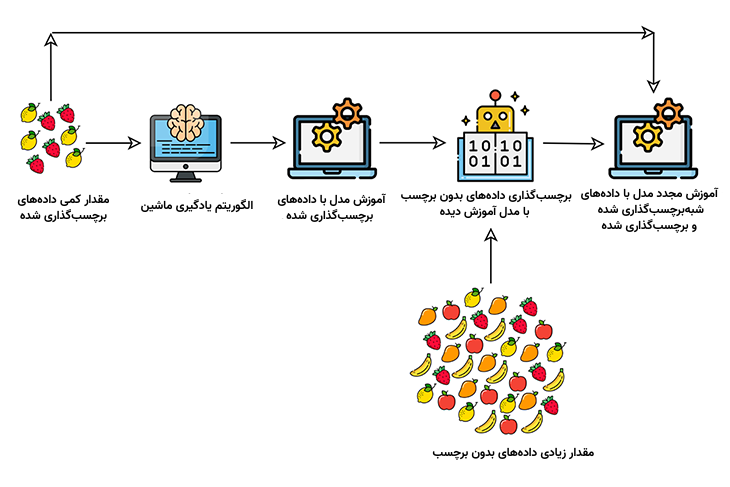
امروزه حجم عظیمی از داده در صنایع مختلف وجود دارد. اما برچسبگذاری دادههای جمعآوریشده به نیروی کار و منابع زیادی نیاز دارد و به همین خاطر بسیار هزینهبر تمام میشود.
برخی از زمینههایی که در آنها از یادگیری نیمهنظارتی استفاده میشود، عبارتاند از:
- ترجمه ماشینی: آموزش الگوریتمهای ترجمه زبان
- تشخیص کلاهبرداری: شناسایی موارد کلاهبرداری هنگامی که فقط چند نمونه مثبت وجود دارد
- برچسب زدن دادهها: الگوریتمهای آموزشدیده، به کمک مجموعه دادههای کوچک یاد میگیرند که برچسب دادهها را به صورت خودکار روی مجموعههای بزرگتر اعمال کنند.
یادگیری تقویتی (Reinforcement Learning)
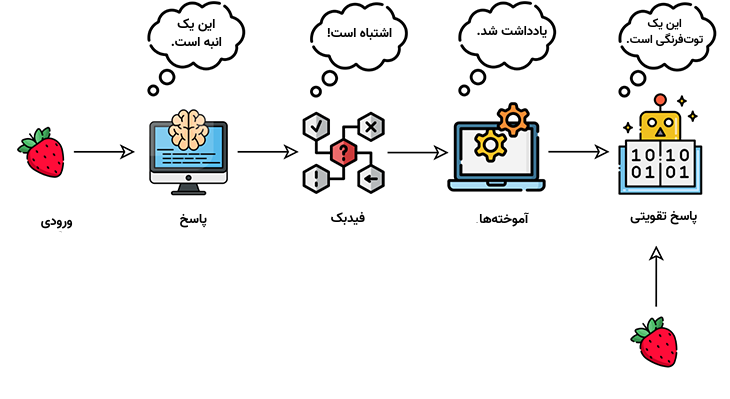
رویکرد دیگر یادگیری ماشین، یادگیری تقویتی است. دانشمندان داده معمولاً از یادگیری تقویتی برای انجام یک فرایند چندمرحلهای که قوانین مشخصی برای آن وجود دارد، استفاده میکنند. آنها الگوریتم را برای رسیدگی به وظیفهای مشخص برنامهنویسی میکنند و در حالی که الگوریتم به وظیفه خود رسیدگی میکند، بازخوردهایی مثبت یا منفی به آن ارائه میدهند. وقتی مدل، نتیجهای را پیشبینی یا تولید میکند، در صورت اشتباه بودن پیشبینی جریمه میشود و در صورت صحت پیشبینی پاداش میگیرد.
برخی از زمینههایی که در آنها از یادگیری تقویتی استفاده میشود، عبارتاند از:
- رباتیک: رباتها میتوانند با استفاده از این تکنیک، رسیدگی به وظایف دنیای واقعی را بیاموزند.
- بازیهای ویدیویی: از یادگیری تقویتی برای آموزش رباتها برای بازی در بسیاری از بازیهای ویدیویی آنلاین استفاده شده است.
- مدیریت منابع: در صورتی که منابع محدود داشته باشید اما هدفی مشخص را دنبال کنید، یادگیری تقویتی میتواند به شما در برنامهریزی برای تخصیص منابع کمک کند.
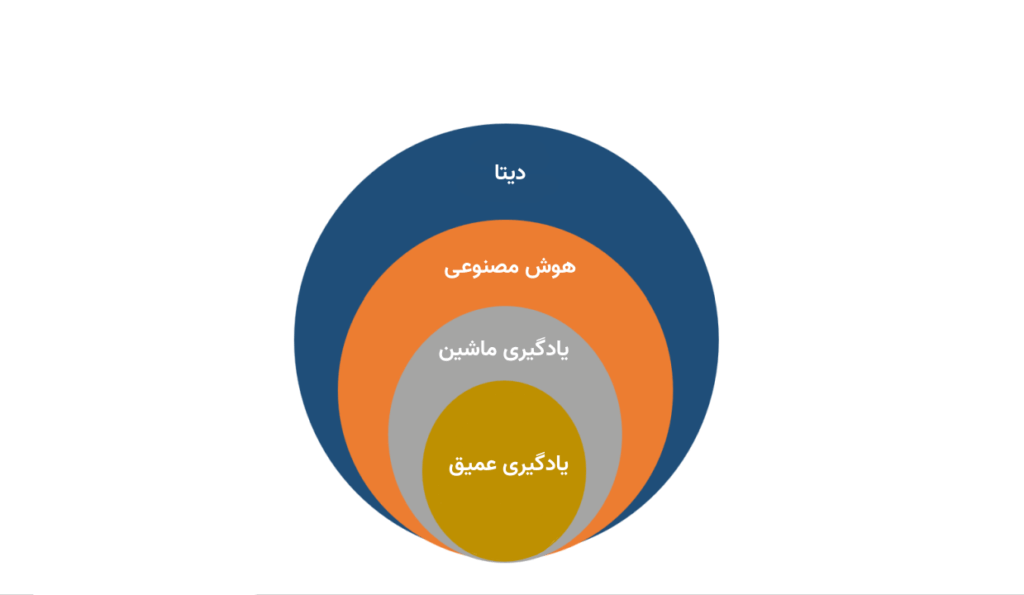
هوش مصنوعی، یادگیری ماشین و یادگیری عمیق
حتی اگر مفهوم هوش مصنوعی (AI) و یادگیری عمیق (Deep Learning) را عمیقا درک نکنید، قطعا نامشان به گوشتان خورده است. اما تفاوت هوش مصنوعی و یادگیری ماشین چیست و هر دو چه تفاوتی با یادگیری عمیق دارند؟ امروزه هر سه مفهوم در کنار یکدیگر، نقش بسیار پررنگی در زندگی ما و پیشرفت کسبوکارها ایفا میکنند. بنابراین بد نیست در این بخش کمی راجع به آنها صحبت و تفاوتشان را بررسی کنیم.
هوش مصنوعی چیست؟
هوش مصنوعی به معنی شبیهسازی هوش انسان توسط نرمافزارها و سیستمهای کامپیوتری است. این فرآیند به معنی فراگیری دانش انسانی و انجام رفتارهای هوشمندانه است. به طور کلی هوش مصنوعی اینطور کار میکند که حجم بزرگی از دادههای آموزشی (Training Data) و برچسبخورده را گردآوری میکند و سپس با تحلیل آنها، دست به پیشبینی راجع به وضعیت داده در مرحله بعد میزند. مثلا یک ابزار تشخیص تصویر میتواند با بررسی میلیونها مثال، اشیا گوناگون را در تصاویر شناسایی و یا آنها را توصیف کند.
یادگیری عمیق چیست؟
یادگیری عمیق (Deep Learning) از زیرمجموعههای خانواده یادگیری ماشین است که از شبکههای عصبی برای شبیهسازی رفتاری شبیه به مغز انسان کمک میگیرد. همانطور که در بخشهای قبلی اشاره کردیم، شبکههای عصبی مشابه مغز انسان عمل و از دادههای گذشته تجربه کسب میکنند. الگوریتمهای یادگیری عمیق نیز با تمرکز روی الگوهای پردازش اطلاعات از راه میرسنند تا امکان شناخت الگوها را فراهم کنند.
اگرچه یادگیری عمیق میتواند الگوهای پیچیده را از دادهها استخراج کند، اما به تنهایی قادر به درک کامل مفاهیم و تفاوتهای میان آنها نیست. به عنوان مثال، یادگیری عمیق نمیتواند به صورت خودکار از تفاوت بین دو تصویر «گربه» و «سگ» آگاهی پیدا کند، مگر اینکه تفاوت میان آنها را صریحا تعلیم دیده باشد. بنابراین یادگیری عمیق فرایندی هوشمند است اما برای داشتن یک هوش مصنوعی کامل، باید از روشهای دیگر همچون استدلال، دانش و منطق نیز استفاده کرد.
تفاوتهای هوش مصنوعی و یادگیری عمیق با یادگیری ماشین چیست ؟
به صورت کلی میتوان گفت یادگیری ماشین، نوعی الگوریتم هوش مصنوعی یا زیرمجموعهای از آن است. یادگیری عمیق نیز زیرمجموعهای از یادگیری ماشین است که میتواند برای پردازش مقادیری کلان از داده به کار رود. نمونههایی از تفاوت این سه را در ادامه بررسی میکنیم.
- هدف هوش مصنوعی در اصل افزایش شانس فراخوانی (Recall) است و دقت (Accuracy) آن اهمیت زیادی ندارد، در یادگیری ماشین، هدف افزایش Accuracy است و Recall از اهمیت کمتری برخوردار است. بالاترین میزان Accuracy هم زمانی حاصل میشود که یادگیری عمیق با حجم بزرگی از اطلاعات تعلیم ببیند.
- الگوریتمهای هوش مصنوعی با استفاده از تکنیکهای مختلف مانند سیستمهای قانونمحور، سیستمهای خبره (Expert System) و درخت تصمیمگیری، توسعه داده میشوند. الگوریتمهای یادگیری ماشین با استفاده از روشهای مبتنی بر ریاضیات مانند شبکههای عصبی، درخت تصمیمگیری و رگرسیون لجستیک توسعه مییابند. الگوریتمهای یادگیری عمیق هم از شبکههای عصبی مصنوعی تشکیل شدهاند که چندین لایه از نورونهای مصنوعی دارند.
- یادگیری ماشین از مقدار اطلاعات کمتری نسبت به هوش مصنوعی و یادگیری عمیق استفاده میکند.
- سیستمهای هوش مصنوعی میتوانند کاملا مستقل عمل کنند، در حالی که در یادگیری ماشین نیاز به مقداری مداخله انسانی خواهیم داشت. در یادگیری عمیق نیز الگوریتمها برای تعلیم دیدن و افزایش دقت، به ارائه بازخورد انسانی، ارزیابی عملکرد و بهینهسازی نیاز دارند.
مثالهایی از هوش مصنوعی، یادگیری عمیق و یادگیری ماشین
- هوش مصنوعی: دستیار دیجیتالی Google Assistant و برنامههایی مانند اوبر و لیفت که از هوش مصنوعی برای برقراری ارتباط میان راننده و کاربر کمک میگیرند.
- یادگیری ماشین: دستیارهای شخصی مجازی مانند سیری و الکسا و فیلترینگ اسپمها در Gmail
- یادگیری عمیق: جمع کردن خبرهای بر اساس احساسات یا sentiment-based (خبرهایی که بر اساس احساسات و نگرشهایی که انتقال میدهند آنالیز و دستهبندی میشوند) و تحلیل تصویر
بیشتر بخوانید: پردازش تصویر چیست و چه کاربردهایی دارد؟
کاربردهای گوناگون یادگیری ماشین چیست ؟
یادگیری ماشین در همهجا استفاده میشود ممکن است در زندگی روزمره بارها به نحوی از آن استفاده کنید و حتی از این موضوع اطلاع نداشته باشید. مثالهایی از کاربردهای یادگیری ماشین را در ادامه آوردهایم:
- تشخیص تصویر (Face Recognition): تشخیص تصویر یکی از رایجترین کاربردهای یادگیری ماشین است. این فناوری، رایانهها و سیستمها را قادر میسازد تا اطلاعاتی معنیدار را از ورودیهای بصری بدست آورند.
- تشخیص گفتار (Speech Recognition): تشخیص گفتار برای تبدیل گفتار به نوشتار استفاده میشود و کاربردهای گوناگون دارد، از احراز هویت تا امکان پیشبرد وظایف با دستورهای صوتی.
- سیستمهای پیشنهاددهی (Recommendation System): یادگیری ماشین بهطور گسترده توسط شرکتهای حوزه تجارت الکترونیک و سرگرمی برای پیشنهاددهی محصول به کاربر استفاده میشود. الگوریتمهای یادگیری ماشین با استفاده از دادههای مربوط به رفتار گذشته کاربر، علاقه آنها را درک و مطابق با دانش خود، محصولاتی را به آنها پیشنهاد میکنند.
- مدیریت ارتباط با مشتری (CRM): نرمافزارهای مدیریت ارتباط با مشتری میتوانند از مدلهای یادگیری ماشین برای تجزیه و تحلیل ایمیل استفاده و به اعضای تیم فروش توصیه کنند که ابتدا به مهمترین پیامها پاسخ دهند. برخی سیستمهای پیشرفتهتر حتی میتوانند پاسخهای مؤثر را توصیه کنند.
- سیستمهای اطلاعات منابع انسانی (Human Resource Information System): سیستمهای منابع انسانی میتوانند از مدلهای یادگیری ماشین برای فیلتر کردن درخواستهای شغلی و شناسایی بهترین نامزدها برای یک موقعیت شغلی کمک بگیرند.
- تشخیص کلاهبرداری (Fraud Detection): الگوریتمهای یادگیری ماشین با نظارت بر فعالیتهای هر کاربر، در تشخیص کلاهبرداری و فعالیتهای پولشویی بسیار عالی عمل میکنند. برای مثال این سیستمها انتقالات مالی را ارزیابی میکنند و معاملات غیر معمول را تشخیص میدهند.
- تشخیص ایمیلهای اسپم (Spam Detection): سیستم تشخیص اسپمی که در سرویسهای ایمیل مشاهده میکنیم، از یک مدل یادگیری ماشین نظارتی برای فیلتر کردن ایمیلهای اسپم از صندوق پستی استفاده میکند.
- معاملات خودکار سهام (Automated Trading Systems): از آنجا که در بازار سهام همیشه خطر بالا و پایین شدن ارزش سهام وجود دارد، از یادگیری ماشین بهطور گسترده در معاملات این بازار و پیشبینی الگوهای معاملاتی استفاده میشود. یادگیری ماشین به پلتفرمهای معاملاتی اجازه میدهد هزاران یا حتی میلیونها معامله را در روز و بدون دخالت انسان پیش ببرند.
- تشخیص بیماری (Medical Diagnosis): از الگوریتمهای یادگیری ماشین میتوان برای تشخیص بیماریها، تعیین بهترین دورهی درمان، کمک به تشخیص دقیقتر و مواردی از این دست استفاده کرد. یادگیری ماشین همچنین قادر به ساخت مدلهای سهبعدی، با هدف تعیین دقیق موقعیت ضایعات در مغز است.
مطلب مرتبط: یادگیری ماشین (Machine Learning) در امنیت سایبری
کاربردهای جالب یادگیری ماشین در زندگی روزمره
ظهور یادگیری ماشین و هوش مصنوعی، منجر به شکلگیری انفجاری کسبوکارهای جدید و هرچه بیشتر شده. در حال حاضر، از یادگیری ماشین برای برطرفسازی گستره وسیعی از نیازها و مشکلات در صنایع مختلف استفاده میشود. در ادامه، برخی از جالبترین کاربردهای یادگیری ماشین را در این کسبوکارهای نوظهور بررسی میکنیم.
- Yelp و مدیریت انبوه تصاویر: Yelp اپلیکیشنی برای بررسی و یافتن رستورانها است و به کاربران اجازه میدهد بهترین رستورانها را در نقاط گوناگون بیابند. از آنجا که تصاویر انواع غذاها و رستورانها تاثیری چشمگیر روی تجربه کاربران میگذارند، Yelp از الگوریتمهای یادگیری ماشین برای گردآوری، دستهبندی و لیبلزنی آنها استفاده میکند.
- Pinterest و اکتشاف هرچه بهتر محتوا: پینترست یکی متفاوتترین پلتفرمهای اجتماعی امروزی به حساب میآید. با توجه به اینکه این پلتفرم روی دستهبندی و پیشنهاددهی محتوای از پیش موجود تمرکز دارد، طبیعی است که از تکنولوژی یادگیری ماشین برای بهبود فرایندها کمک بگیرد. این روزها پینترست در تقریبا تمام ابعاد کار خود – از عملیاتهای تجاری گرفته تا مدیریت محتوای هرز و اکتشاف محتوای جدید – یادگیری ماشین استفاده میکند.
- ایکس و تایملاین سفارشی: شبکه اجتماعی «ایکس» (یا توییتر سابق) هم از الگوریتمهای یادگیری ماشین برای نمایش محتوای مورد پسند کاربران استفاده میکند. هوش مصنوعی پشت این پلتفرم در هر لحظه مشغول ارزیابی توییتهای کاربران است و بسته به معیارهای گوناگون به آنها «امتیاز» میدهد. بعد از این، الگوریتم تلاش میکند توییتهایی را به نمایش درآورد که بیشترین شانس دستیابی به نرخ تعامل یا انگیجمنت بالا دارند.
- گوگل، شبکههای عصبی و ماشینهای رویاپرداز: گوگل طی سالهای اخیر سخت مشغول کار بوده و به حوزههای گوناگون مانند تکنولوژیهای ضد پیری، دستگاههای پزشکی و جالبتر از همه، «شبکههای عصبی» (Neural Networks) ورود کرده است. یکی از دستاوردهای گوگل در حوزه شبکه عصبی، شبکه DeepMind است که نتایجی خارقالعاده به همراه میآورد و به «ماشین رویاپرداز» معروف شده است. گوگل میگوید در حال تحقیق در تقریبا تمام زمینههای مرتبط به یادگیری ماشینی است و هوش مصنوعی گوگل جمینی تنها یکی از نخستین موفقیتها به حساب میآید.
- IBM و بهبود سیستم سلامت: با توجه به اینکه IBM از موفقترین و باسابقهترین شرکتهای تکنولوژی به حساب میآید، مشاهده آن در این فهرست به هیچ وجه جای تعجب ندارد. البته IBM این روزها از روشهای کسب درآمد پیشین فاصله گرفته و دست به کارهایی جدید میزند. برای مثال میتوان به هوش مصنوعی Watson اشاره کرد که طی سالهای اخیر در بیمارستانها و مراکز درمانی گوناگون به کار گرفته شده و میتواند پیشنهاداتی بسیار دقیق برای درمان برخی از انواع سرطان ارائه کند. همین هوش مصنوعی میتواند در حوزههای دیگر نیز به کار گرفته شود، مثلا به عنوان دستیاری برای مشتریان فروشگاههای زنجیرهای.
بهترین زبانهای برنامهنویسی برای هوش مصنوعی و یادگیری ماشین چیست ؟

این روزها با انواع زبانهای برنامهنویسی میتوان پروژههای یادگیری ماشین را پیش برد. در ادامه، برخی از پرکاربردترین زبانهای برنامهنویسی در این حوزه را بررسی میکنیم.
- Python: پایتون یکی از اولین انتخابها در حوزه یادگیری ماشین به حساب میآید، عمدتا به این خاطر که زبانی بسیار ساده و انعطافپذیر است. پایتون اکوسیستمی عظیم از کتابخانهها و فریمورکهای گوناگون – مانند TensorFlow و PyTorch – دارد که پیادهسازی مدلهای یادگیری ماشین پیچیده را آسان میکنند. از سوی دیگر، قواعد نحوی (سینتکس) آسان و پشتیبانی جامعه کاربران باعث میشود پایتون برای تازهکاران هم انتخابی ایدهآل باشد.
- R: زبان برنامهنویسی R عمدتا به خاطر تواناییهای آماریاش به محبوبیت رسیده و بنابراین جزو اولین انتخابها برای تحلیل و مصورسازی داده با یادگیری ماشین به حساب میآید. R بیشمار پکیج آماری و لایبرری مختلف – مانند Caret و ggplot2 – دارد که کمک قابل توجهی به دانشمندان داده میکنند. محیط تعاملی R و تمرکز آن بر تحلیل داده نیز این زبان را به انتخابی بینظیر برای مدلسازی آماری و پروژههای تحقیقمحور تبدیل میکند.
- Julia: جولیا زبانی نسبتا جدید است که به خاطر افزایش بهرهوری و پرفورمنس وظایف مختلف، توجهها را به خود جلب کرده است. این زبان سهولت استفاده و خوانایی پایتون را با سرعت زبانهای سطح پایین – مانند سی پلاس پلاس – ترکیب میکند. سیستم کامپایل منحصر به فرد جولیا به نام Just-in-Time (یا JIT) به شما اجازه میدهد کدها را سریعتر به اجرا درآورید و بنابراین گزینهای معرکه برای رایانش مورد نیاز در وظایف یادگیری ماشین به حساب میآید. ناگفته نماند که اکوسیستم کتابخانههای Julia هر روز گسترش مییابد و اگر به دنبال بالاترین سرعت و پرفورمنس میگردید، حتما باید این زبان را هم بررسی کنید.
- Java: جاوا به خاطر مقیاسپذیری و خوانایی فراوان، معمولا جزو اولین انتخابهای سازمانها و شرکتهای بزرگ به حساب میآید. اگرچه کاربرد اصلی جاوا در حوزه یادگیری ماشین نیست، اما کتابخانههای قدرتمندی مانند Deeplearning4j برای آن ساخته شدهاند که پیادهسازی یادگیری ماشین در اپلیکیشنهای گوناگون را آسان میکنند. با توجه به تمرکز فراوان بر امنیت، ثبات عملکرد و سازگاری با پلتفرمهای گوناگون، جاوا گزینهای بینظیر برای پروژههای عظیم و صنعتی به حساب میآید.
- Lisp: این زبان، سینتکسی منحصر به فرد و قابلیتهای متعدد برای «فرا برنامهنویسی» (MetaProgramming) دارد که باعث شده از بازیگران قدیمی دنیای هوش مصنوعی باشد. از بزرگترین نقاط قوت Lisp میشود به کاربرد فراوان آن در حوزه «هوش مصنوعی نمادین» (Symbolic AI) و همینطور دستکاری کدها به شکلی یکسان با دستکاری داده اشاره کرد. اگرچه لیسپ به اندازه سایر زبانها محبوب نیست، سطوح بینظیری از انعطافپذیری و بیانگرایی را در اختیارتان میگذارد.
- JavaScript: از جاوا اسکریپت معمولا در حوزه توسعه وب استفاده میکنند، اما نمیتوان کاربردهایش در حوزه یادگیری ماشین را نادیده گرفت. با درنظرگیری دسترسی به کتابخانههایی مانند Brain.js، جاوا اسکریپت اکنون جزو اولین انتخابها برای توسعه پروژههای یادگیری ماشین تحت وب به حساب میآید. جاوا اسکریپت سازگاری گسترده با انواع زبانها و پلتفرمها دارد و از بهترین انتخابها برای اپلیکیشنهایی به حساب میآید که نیاز به استنباط در لحظه و یا تعامل از سوی کاربران دارند.
- ++C: سی پلاس پلاس زبانی سطح پایین (Low-Level) است که به خاطر سرعت و میزان کنترلی که در اختیارکاربران میگذارد محبوب شده است. اگرچه کدنویسی به زبان ++C سختتر و زمانبر تر از سایر زبانها خواهد بود، اما میتوانید منتظر عملکردی بینظیر در رسیدگی به وظایف پردازشی سنگین باشید. از سی پلاس پلاس معمولا در توسعه کتابخانهها و فریمورکهای یادگیری ماشین – مانند OpenCV و Caffe – استفاده میشود. اما اگر در غاییترین حالت به دنبال پرفورمنس بالا و کنترل سطح پایین بر سیستمهای کامپیوتری میگردید، ++C تقریبا برای هر پروژهای مناسب تلقی میشود.
روش انتخاب مدل یادگیری ماشین چیست ؟
حالا که دانشی عمیق راجع به یادگیری ماشین به دست آوردهایم، نوبت به بررسی این میرسد که چطور میتوانیم رویکرد مطلوب خود در این حوزه را شناسایی کنیم؟ به عبارت دیگر، چطور بهترین رویکرد را برای پروژه خود انتخاب کنیم؟ موارد زیر را مد نظر داشته باشید.
درک مسئله
ابتدا باید مسئله خود و اهدافی که قصد دارید با استفاده از یادگیری ماشین به آنها برسید را مشخص کنید. برای این کار میتوانید این سوالها را از خود بپرسید:
- مسئلهای که قصد دارید حل کنید چیست؟ (مثلا طبقهبندی، پیشبینی و غیره)
- به نظرتان کدام الگوریتمهای یادگیری ماشین برای این مسئله مناسبتر هستند؟
- چه نوع دادهای در اختیار دارید و چگونه میتوانید از آن در یادگیری ماشین استفاده کنید؟
بررسی دادهها
پس از درک مسئله، نوبت به بررسی دادهها میرسد. برای این کار بهتر است مراحل زیر را طی کنید:
- دادههای خام را پردازش و پاکسازی کنید.
- نمونههایی از دادهها را برای آموزش، تست و اعتبارسنجی جدا کنید.
- ویژگیهای مهم دادهها را شناسایی کنید.
انتخاب الگوریتم
در این مرحله، باید الگوریتمهای یادگیری ماشین مختلف را بررسی کرده و بر اساس نیازهای خود یک مدل مناسب را برگزینید. برخی از معیارهای مهم عبارتاند از:
- سرعت آموزش و پیشبینی
- قابلیت تفسیر
- میزان پیچیدگی مدل
- عملکرد در برابر دادههای ناقص و نویزی
آموزش و اعتبارسنجی مدل
پس از انتخاب مدل مناسب، نوبت به آموزش و اعتبار سنجی آن میرسد. مراحل این بخش نیز به شرح زیر است:
- پارامترهای مدل را بهینهسازی کنید.
- مدل را با استفاده از دادههای آموزشی، تعلیم دهید.
- عملکرد مدل را با استفاده از دادههای اعتبارسنجی ارزیابی کنید.
ارزیابی مدل
پس برای این که از عملکرد خوب مدل اطمینان حاصل کنید باید آن را ارزیابی کنید. اما چطور؟ موارد زیر برخی از روشهای این کار است.
- معیارهای ارزیابی مناسب را برای مسئله خود انتخاب کنید.
- مدل را با استفاده از دادههای تست ارزیابی کنید.
- نتایج را با الگوریتمهای رقیب مقایسه کنید.
بهینهسازی و تکرار
اگر با طی کردن مراحل بالا دیدید نتایج اولیه قابل قبول نیستند، باید به بهینهسازی و تکرار بپردازید. به این صورت که:
- پارامترها و تنظیمات مدل را بهینهسازی کنید.
- دادههای خود را مجددا بررسی و پردازش کنید.
- الگوریتمهای دیگری را بررسی و امتحان کنید.
به طور کلی انتخاب مدل یادگیری ماشین مناسب مسئله شما یک فرآیند تکاملی است و ممکن است نیاز به چندین بار تلاش و تکرار داشته باشد تا به بهترین مدل برای مسئله خود برسید. در نهایت، هدف اصلی ما انتخاب یک مدل است که بتواند به طور کارآمد و دقیق مسئله مورد نظر را حل کند.
تا اینجا درمورد این که یادگیری ماشین چیست و چه ویژگیها و کاربردهایی دارد صجبت کردیم. اما در صورت ورود به این حوزه، باید منتظر چه مشاغلی باشیم؟
برخی از مشاغل حوزه یادگیری ماشین چیست ؟
طی سال ۲۰۲۴ و سالهای بعدی، بازار هوش مصنوعی و یادگیری ماشین بزرگتر از همیشه خواهد شد و انبوهی فرصت شغلی بالقوه و پردرآمد نیز شکل خواهد گرفت. در ادامه برخی از پردرآمدترین و پرتقاضاترین سمتهای شغلی دنیای یادگیری ماشین را بررسی میکنیم.
- مهندس یادگیری ماشین: چنین مهندسانی مسئولیت ساخت الگوریتمها و مدلهایی را برعهده دارند که به ماشین اجازه میدهند به صورت خودکار، فرایند یادگیری و بهبود را پیش ببرد. این افراد نیاز به آشنایی قابل توجه با مهندسی نرمافزار، علم داده و برنامهنویسی خواهند شد. درآمد سالانه این شغل در کشورهای توسعهیافته بیش از ۱۰۰ هزار دلار است و شرکتهایی مانند اپل و فیسبوک هم بین ۱۷۰ تا ۲۰۰ هزار دلار به مهندسان یادگیری ماشین خود میپردازند.
- مهندس هوش مصنوعی: مهندس AI بر توسعه و پیادهسازی مدلها و سیستمهای هوش مصنوعی تمرکز دارد، عملکرد AI را بهینهسازی میکند و در جریان آخرین پیشرفتهای این حوزه باقی میماند. از مهارتهای ضروری این مهندسان میتوان به تخصص فنی در ریاضیات، آمار و زبانهای مختلف برنامهنویسی اشاره کرد. درآمد سالانه AI Engineer در کشورهایی مانند آمریکا، بیش از ۱۶۰ هزار دلار است.
- دانشمند داده: دانشمندان داده به تحلیل و تفسیر دادههای عمیق مشغول میشوند و برای دستیابی به اطلاعات ارزشمند، انواع تکنیکهای آماری و یادگیری ماشین را به کار میبندند. از مهارتهای مورد نیاز آنها هم میشود به استخراج داده، تحلیل آماری و زبانهایی مانند پایتون اشاره کرد. ناگفته نماند که درآمد دانشمندان داده بسته به مهارتها و تجاربشان متغیر است و در کشورهای توسعهیافته به ۶۰ هزار تا ۱۰۵ هزار دلار میرسد.
- مهندس بینایی کامپیوتر: مهندسان بینایی کامپیوتر (Computer Vision) سیستمهایی را میسازند که به کامپیوترها اجازه میدهند دادههای بصری را تفسیر و درک کنند. برای ورود به این شغل نیاز به تخصص در زمینههای هوش مصنوعی، یادگیری ماشین و تکنولوژیهای بینایی کامپیوتر داشته باشید. درآمد سالانه مهندس بینایی کامپیوتر نیز حدود ۱۶۰ هزار دلار است.
- مهندس پردازش زبان طبیعی: مهندسان «پردازش زبان طبیعی» (Natural Language Processing) به دنبال ساخت سیستمهایی هستند که بتوانند زبان انسانی را درک و تفسیر کنند. برای ورود به این جهان، مهارتهای یادگیری ماشین، زبانشناسی و برنامهنویسی ضروری خواهند بود. میانگین درآمد مهندس NLP در کشورهایی مانند آمریکا، ۸۰ هزار دلار است.
- مهندس یادگیری عمیق: تخصص مهندسی یادگیری عمیق، توسعه شبکههای عصبی و الگوریتمهای یادگیری عمیق است. برای ورود به این حوزه باید درکی عمیق از تکنولوژیهای یادگیری ماشین و برنامهنویسی به دست آورده باشید. مهندسان یادگیری عمیق درآمد سالانه حدودا ۱۴۰ هزار دلاری در کشورهای توسعهیافته دارند.
آینده و بازار کار یادگیری ماشین چه شکلی است؟
هوش مصنوعی و یادگیری عمیق در حال افزایش بهرهوری و اثرگذاری وظایف در صنایع گوناگون هستند. به تبع همین موضوع، فرصتهای شغلی فراوان در صنایع مختلف شکل گرفتهاند. این یعنی میتوانیم منتظر آیندهای نویدبخش باشیم که در آن، خلاقیت انسانی و هوش ماشینی، دستاوردهایی ورای تصور خواهند داشت. در ادامه به بررسی صنایغی میپردازیم که در آینده، بازار توسعه هوش مصنوعی و یادگیری ماشین را بزرگتر از همیشه خواهند کرد.
- امنیت سایبری: هوش مصنوعی با تشخیص تهدیدهای سایبری و جلوگیری از آنها، امنیت را بهبود میبخشد. تکنولوژیهای AI و یادگیری ماشین به سیستمهای امنیتی اجازه خواهند داد که دادههای کلان را با سرعت بالا تحلیل کنند، الگوها و ناهنجاریها را تشخیص دهند و از رخنههای امنیتی بالقوه جلوگیری کنند. الگوریتمهای یادگیری ماشین به کمک یادگیری پیوسته، خود را با تهدیدهای نوظهور تطبیق میدهند و در گذر زمان، دقت بالاتری از خود به نمایش خواهند گذاشت. راهکارهای متکی بر هوش مصنوعی هم میتوانند فرایندهایی مانند واکنشدهی به تهدیدات شناختهشده و فعالسازی تدابیر دفاعی را اتوماسیون کنند.
- سلامت: همینطور که هوش مصنوعی راه خود را بیش از پیش به صنعت بهداشت و سلامت باز میکند، شاهد دستاوردهایی مانند بالا رفتن دقت تشخیص بیماری، سرراستتر شدن وظایف مدیریتی و سفارشیسازی فرایند درمان هر بیمار بودهایم. به کمک تحلیل پیشبینانه و تشخیص تصویر هم میتوان دقت شناسایی بیماریها را بیش از پیش افزایش داد و شانس حیات بیماران را بالا برد. گذشته از این موارد، ابزارهای هوش مصنوعی میتوانند در مدیریت دادههای کلان و تصمیمگیری آگاهانه نیز به متخصصان حوزه سلامت کمک کنند.
- سرگرمی: هوش مصنوعی و یادگیری ماشین، صنعت سرگرمی را نیز دگرگون کردهاند و این روزها شاهد انبوهی از محتوا، سیستمهای پیشنهاددهی و تجارب کاربری سفارشی هستیم که بدون هوش مصنوعی، وجود خارجی نداشتند. الگوریتمهای AI میتوانند سلایق کاربر را تحلیل کنند و سپس پیشنهادات سفارشی در اختیار آنها بگذارند. به این ترتیب، احتمال تعامل گستردهتر و طولانیتر مخاطب با محتوا یا پلتفرمها، بالا میرود. هوش مصنوعی ضمنا در بهینهسازی جریانهای کاری هم نقشی حیاتی ایفا میکند و اجازه میدهد روی نوآوریهای خلاقانه متمرکز بمانید.
- استخدام و کارآفرینی: فرایندهای استخدام و جذب نیرو نیز با از راه رسیدن هوش مصنوعی، تغییرات زیادی به خود دیدهاند. در حال حاضر ۳۵ تا ۴۵ درصد از کسبوکارهای بزرگ و همینطور ۵۰۰ کمپانی برتر فورچن، از هوش مصنوعی برای استخدام نیروها کمک میگیرند. در واقع اتوماسیون، مراحل مختلف استخدام نیرو را سرراستتر کرده است و از خوانش رزومه تا یافتن کاندیداهای مناسب را میتوان با هوش مصنوعی پیش برد. از سوی دیگر، چتباتها و دستیارهای دیجیتال میتوانند مصاحبهای اولیه با نیروها داشته باشند و به زمانبندی مصاحبه نهایی کمک کنند. تمام اینها باعث میشود تجربه استخدام – هم برای نیروی کار و هم کارآفرینان – قاعدهمندتر و آسانتر باشد. نکته مهم دیگر اینکه هوش مصنوعی به فرایند استخدام سرعت میدهد و سوگیریهای انسانی را هم از معادله خارج میکند.
مهارتهای لازم برای یک متخصص یادگیری ماشین چیست ؟
با توجه به رشد و تکامل سریع جهان یادگیری ماشین، صحبت راجع به مهارتهای ضروری برای مهندسان و متخصصان یادگیری ماشین دشوار است. با این حال، برخی مهارتهای بنیادین هیچوقت تغییر نمیکنند و در ادامه، به همین موارد میپردازیم:
- تخصص در علم داده: مهندس یادگایری ماشین باید آشنایی کامل با مبانی علم داده – مانند پایتون، آمار، بهینهسازی مدل و بهکارگیری فریمورکهای یادگیری ماشین مانند Sci-Kit – داشته باشد.
- تخصص در مهندسی نرمافزار: برای ورود به این حوزه نهتنها نیاز به تسلط بر زبانهای برنامهنویسی گوناگون (مثل پایتون، جاوا، سی پلاس پلاس و جاوا اسکریپت) دارید، بلکه باید با پردازش توزیعشده، مدیریت دیتابیس، کانتینرسازی (Containerization) و توسعه API هم آشنا باشید. درک قواعد و رویکردهای مهندسی نرمافزار – مثل ایرادیابی، تست و توسعه پیوسته – نیز برای تبدیل شدن به مهندس یادگیری ماشین ضروری است.
- آشنایی با الگوریتمها و فریمورکهای یادگیری ماشین: مهندس یادگیری ماشین باید درکی جامع از معماریهای یادگیری عمیق، الگوریتمهای یادگیری ماشین و نظریههای بنیادین این حوزه داشته باشد. تسلط بر فریمورکهایی مانند Keras ،TensorFlow و PyTorch هم کاملا ضروری به حساب میآید.
- طراحی سیستم یادگیری ماشین: گذشته از تخصص الگوریتمی، مهندسان یادگیری ماشین باید بتوانند سیستمهای یادگیری ماشین سرتاسر (End-to-End) را نیز طراحی و پیادهسازی کنند. این یعنی باید زیرساخت لازم و ابزارهایی که خط لوله یادگیری ماشین را به جریان میاندازند را به درستی به کار بست.
- پردازش توزیعشده: تسلط بر روشهای مدیریت دادههای کلان و توانایی افزایش مقیاس مدلهای یادگیری ماشین، از دیگر موارد ضروری است. برای مدیریت کلاندادههای پیچیده، لازم است تجربه کار با پلتفرمهای پردازش توزیعشده – مانند Hadoop و Spark – را داشته باشید.
- پردازش ابری: مهندس یادگیری ماشین باید به راحتی قادر به پیادهسازی مدلها در پلتفرمهای ابری گوناگون مانند AWP آمازون و Azure مایکروسافت باشد. از سوی دیگر باید بتوان استفادهای موثر از مقیاسپذیری و انعطافپذیری موجود در زیرساختهای ابری داشت.
مهارتهای نرم ضروری
در قلمروی پویای یادگیری ماشین، تخصص فنی تنها یکی از پیشنیازهای ورود به مشاغل به حساب میآید و مهارتهای نرم هم به همان اندازه موثر ظاهر خواهند شد. این مهارتها به شما اجازه خواهند داد که ارتباطی موثر با همکاران برقرار کنید، خودتان را به شرایط کاری هر شرکت تطبیق دهید و بهرهوری خود را در تیم بالا ببرید.
- مهارتهای ارتباطی: ارتباط واضح و موثر با تمام بازیگران – چه سهامداران شرکت، چه دانشمندان داده و چه بازاریابان – برای دستیابی به اهداف پروژه و برآوردهسازی انتظارات ضروری خواهد بود.
- مهارتهای حل مسئله: برای اینکه بتوانید از پس چالشهای روزمره پروژههای یادگیری ماشین برآیید، نیاز به تفکر انتقادی و حل مسئله خلاقانه خواهید داشت.
- مدیریت زمان: زمانی که به خواستهها و نیازهای اعضای تیم و مشتریان رسیدگی میکنید، نیاز به برنامهریزی زمانی موثر خواهید داشت تا فرایند تحقیق، برنامهریزی، طراحی و تست بدون هیچ اختلالی پیش رود.
- کار تیمی: همکاری با تمام افراد دخیل در پروژه – از دانشمندان داده گرفته تا مدیران محصول – منجر به شکلکیری یک محیط کاری سالم و مشارکتی میشود.
- کنجکاوی: این مهارت نهتنها برای کارآفرینان مهم است، بلکه برای پیشرفت شغلی شما هم ضروری به حساب میآیند. حوزههایی مانند یادگیری ماشین و هوش مصنوعی در هر روز و هر ساعت دستاوردهایی تازه از خود به نمایش میگذارد. بنابراین همینطور که الگوریتمها، فریمورک و تکنیکهای جدید از راه میرسند، باقی ماندن در جریان امور ضروری است.
جمعبندی و پاسخ به سوالات متداول پیرامون اینکه یادگیری ماشین چیست
امروزه با توجه به رشد سریع فناوری و حجیمتر شدن داده، یادگیری ماشین به عنوان یکی از رشته های پرطرفدار و جذاب در علوم کامپیوتر و داده ها شناخته میشود. در این مطلب به تفصیل گفتیم یادگیری ماشین چیست و چطور با استفاده از الگوریتمهای خاص، امکان تحلیل دادهها و شناسایی الگوهایی برای پیشبینی دادههای آینده را به کامپیوترها میدهد.
در این مقاله علاوه بر پرداختن عمیقتر به مفهوم یادگیری ماشین، به مواردی همچون اهمیت یادگیری ماشین، انواع یادگیری ماشین، کاربردهای آن و… پرداختیم و تلاش کردیم تا به مهمترین چالشهای ذهنی علاقه مندان به این مفهوم پاسخ دهیم.
اتوماسیون به معنی واداشتن سیستم به دنبال کردن قواعدی کاملا مشخص است و تمام وظایف هر بار به شکلی یکسان انجام میشوند. از طرف دیگر اما یادگیری ماشین به سیستم اجازه میدهد رفتاری منطبق با اطلاعات دریافتی و پردازششده داشته باشد و در گذر زمان، بیاموزد و بهبود یابد.
فرایند دادهکاوی، الگوهایی تولید میکند که برای شناسایی انواع مشخصی از وظایف – مثلا تشخیص ناهنجاری، خوشهبندی یا دستهبندی – به کار میآیند. در نتیجه، دادهکاوی راجع به تشخیص گروهها یا ناهنجاریهای مشابه در دادهای یکسان است. از طرف دیگر، یادگیری ماشین به تولید الگوریتم یا مدلی میپردازد که با دریافت ورودی، خروجی را پیشبینی میکند.
منبع: Skedler و Elite Recruitments و Eleks